Paper Summary #1 - Attention Is All You Need

Paper: Attention Is All You Need
Link: https://bit.ly/3aklLFY
Authors: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
Code: https://github.com/tensorflow/tensor2tensor
What?
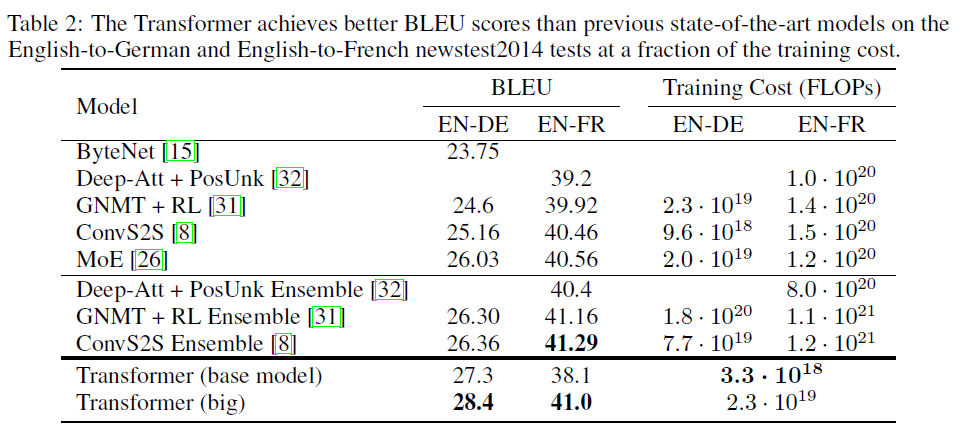
Proposes Transformers, a new simple architecture for sequence transduction that uses only an attention mechanism and does not use any kind of recurrence or convolution. This model achieves SOTA (at the time) on the WMT 2014 English-to-French translation task with a score of 41.0 BLEU. Also beats the existing best results on the WMT 2014 English-to-German translation task with a score of 28.4 BLEU. The training cost is also much less than the best models chosen in the paper (at the time).
Why?
Existing recurrent models like RNNs, LSTMs or GRUs work sequentially. They align the positions to steps in computation time. They generate a sequence of hidden states as a function of the previous hidden state and the input for the current position. But sequential computation has constraints. They are not easily parallelizable which is required when the sequence lengths become large. The Transformer model eschews recurrence and allows for more parallelization and requires less training time to achieve SOTA in the machine translation task.
How?
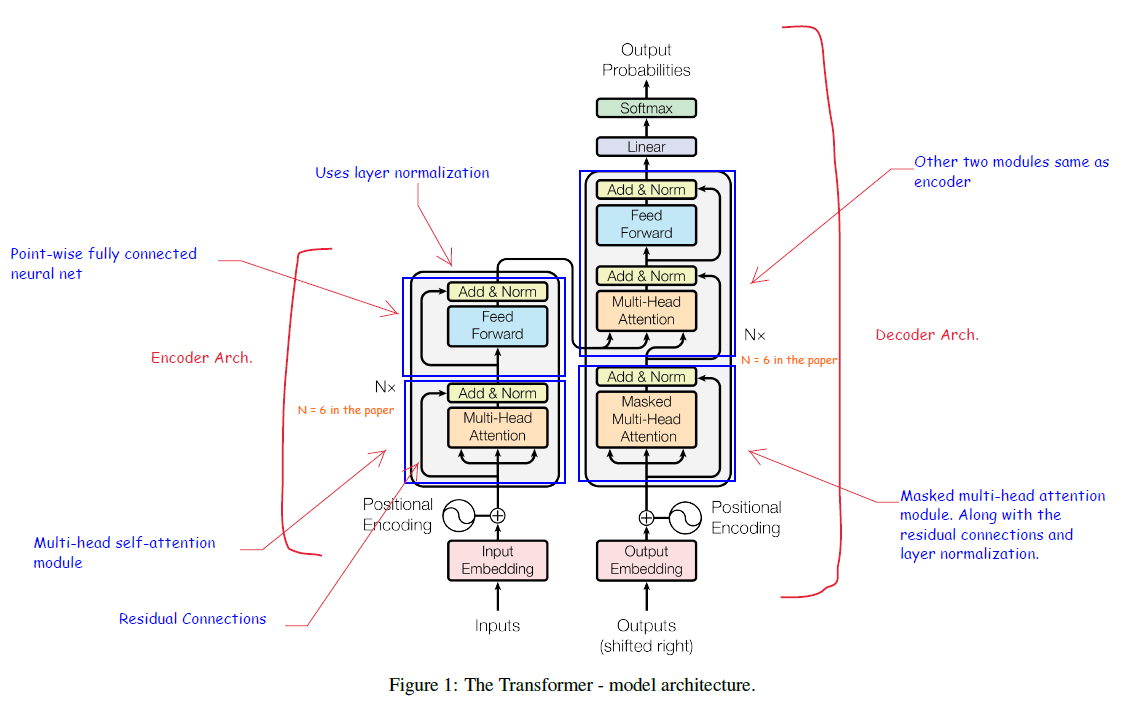
The model is auto-regressive, it consumes the previously generated symbols as additional input when generating the next.
Encoder
The figure above shows just one layer of the encoder on the left. There are N=6 such layers. Each layer has two sub-layers - a multi-head self-attention layer and a position-wise fully connected feed-forward network. Residual connections and layer normalization is used for each sub-layer.
Decoder
This also has N=6 stacked layers. The architecture diagram shows one layer of the decoder on the right. Each layer has three sub-layers. Two of them are the same as the encoder. The third layer performs multi-head attention over the output of the encoder stack. This is modified to prevent positions from attending to subsequent positions. Additionally, the output embeddings are also offset by one position. These features ensure that the predictions for a position depend only on the known outputs for positions before it.
Attention
The paper uses a modified dot product attention, and it is called “Scaled Dot Product Attention”. Given queries and keys of dimension dk and values of dimension dv, the attention matrix is calculated as shown below.
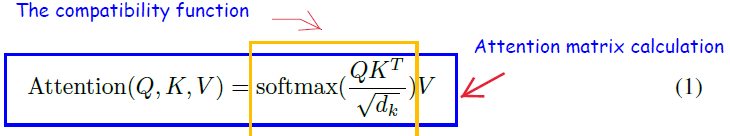
Since, for large values of dk the dot product grows large in magnitude, it pushes the softmax function into regions where it has extremely small gradients. The scaling of 1/sqrt(dk) is done to avoid the problem of vanishing gradients.
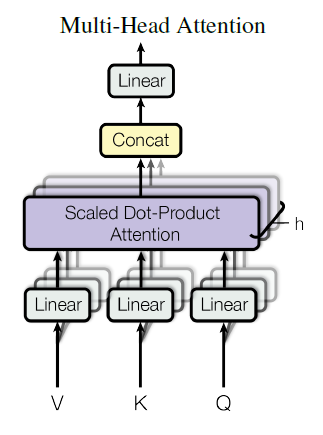
Multi-Head attention allows computing this attention in parallel. This helps to focus on different positions. Secondly, it also helps to attend to information from different subspaces due to the more number of attention heads.

The paper uses h=8 parallel attention layers or heads. The reduced dimension of each head compensates for the more number of heads and hence the computational cost remains the same as with single-head attention with full dimensionality.
Applications of multi-head attention in the paper are given below -

Position-wise Feed-Forward Networks
The FFN sub-layer shown in the encoder and decoder architecture is a 2-hidden layer FC FNN with a ReLU activation in between.
Positional Encodings
Positional encodings are injected (added) to the input embeddings at the bottom of the encoder and decoder stack to add some information about the relative order of the tokens in the sequence. The positional encodings have the same dimension as the input embeddings so that they can be added. For position pos and dimension i the paper uses the following positional embeddings -
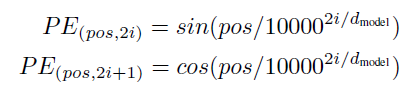
This choice allows the model to easily learn by the relative positions. The learned positional embeddings also perform about the same as the sinusoidal version. The sinusoidal version may allow the model to extrapolate to sequence lengths longer than the ones encountered in training.
Results
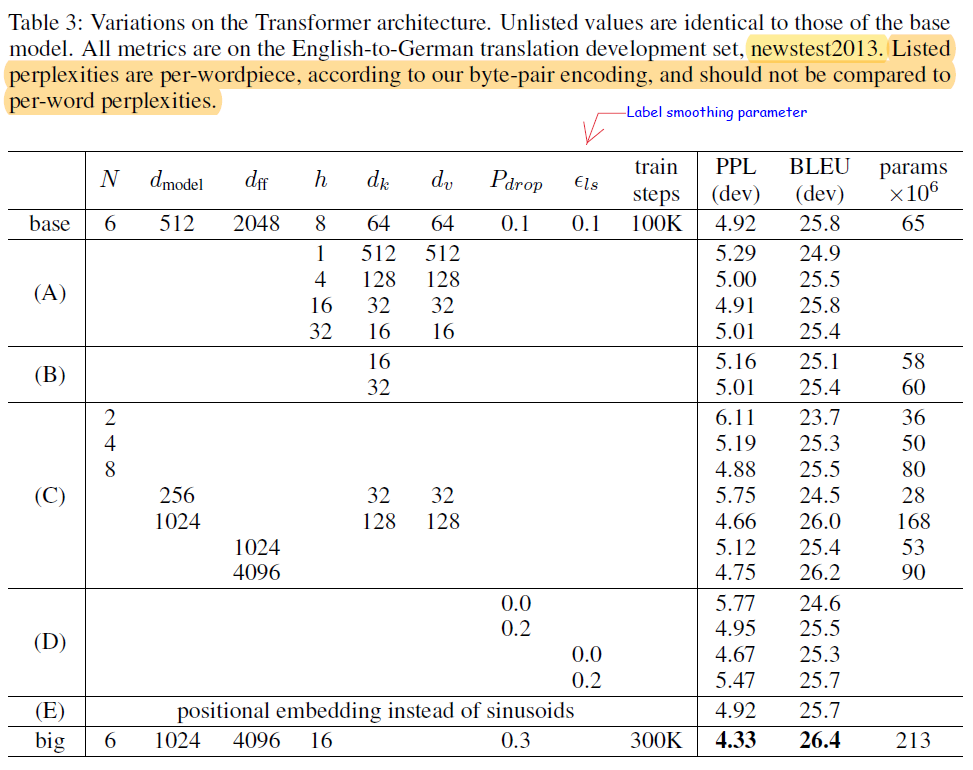
- Form (A), it can be seen that single-head attention is slightly worse than the best setting. The quality also drops off with too many heads.
- (B) shows that reducing the attention key size dk hurts model quality.
- In (C) and (D), it is visible that bigger models are better and dropout helps in avoiding overfitting.
- (E) shows that sinusoidal positional encoding when replaced with learned positional embeddings also does not lead to a loss in quality
For the base models, the authors used a single model obtained by averaging the last 5 checkpoints, which were written at 10-minute intervals. The big models were averaged over the last 20 checkpoints. Beam search with a beam size of 4 and length penalty α = 0.6. The maximum output length during inference is set to input length +50, but if it is possible, the model terminates early.
The performance comparison with the other models is shown below -
I have also released an annotated version of the paper. If you are interested, you can find it here.
This is all for now!