- mlsys
- transformers
- paper-summaries
- MLSys
- LLMs
- PPML
•
•
•
•
•
-
Softmax and Cross-Entropy Backward Pass
A step-by-step derivation of softmax, logsoftmax, and cross-entropy backward passes: how the softmax Jacobian turns into a row-wise dot product, and why the logits gradient is p - y.

-
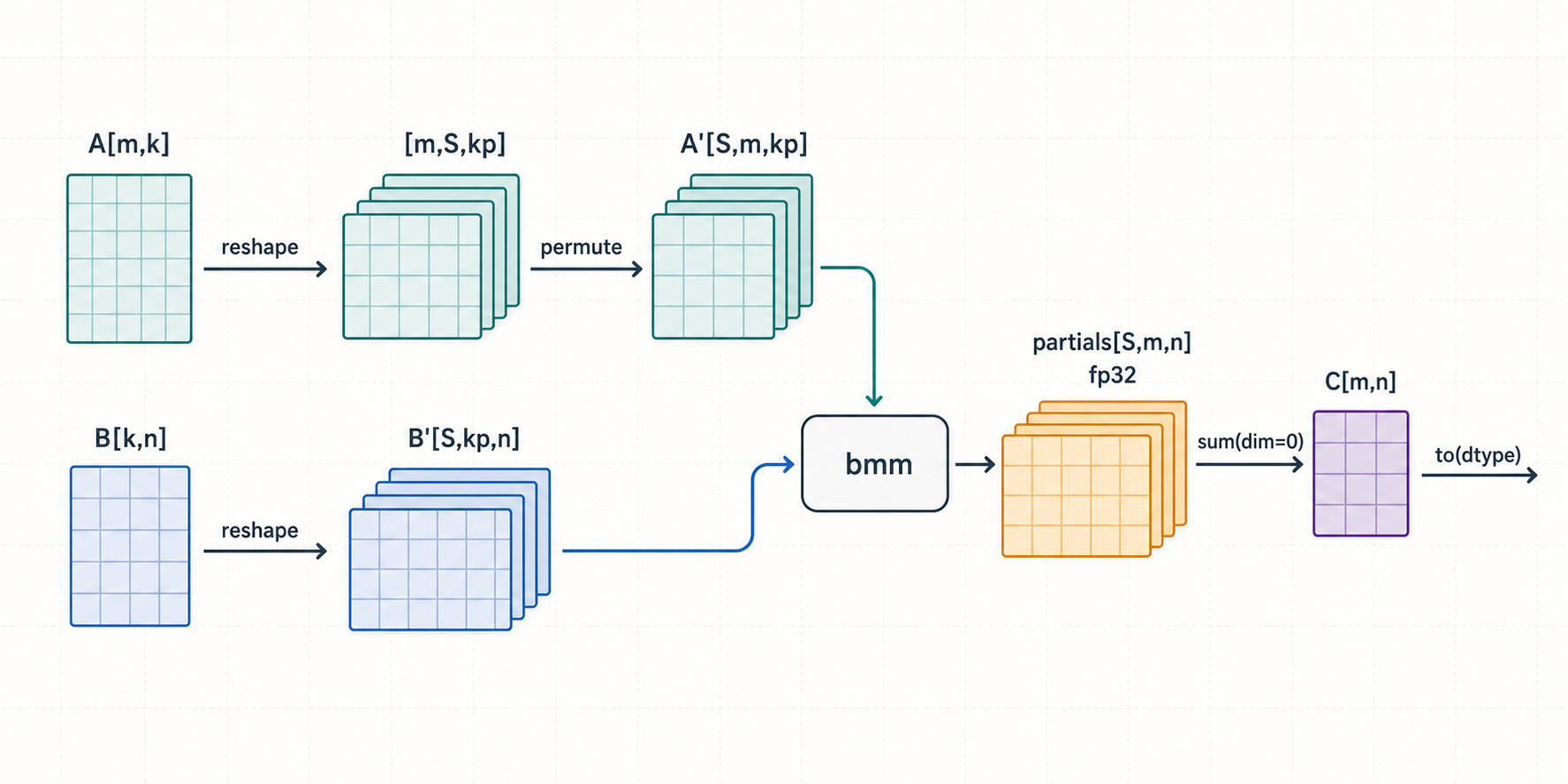
Decompose-K: From torch.compile to Hand-Tuned Triton Kernels for Skinny Large‑K Matmuls
An implementation deep dive into Decompose-K matmul: why splitting the K dimension helps skinny large-K GEMMs, what torch.compile and Inductor custom-op autotuning emit, and how a vectorized split-reduction Triton kernel ends up beating both.
-
KV Cache Compaction and Compression: From Attention Sinks to Learned Memory
A code-first guide to KV cache compression: why the cache dominates long-context serving, how token-eviction methods work, and how Cartridges and STILL turn compact KV tensors into reusable memory.

-
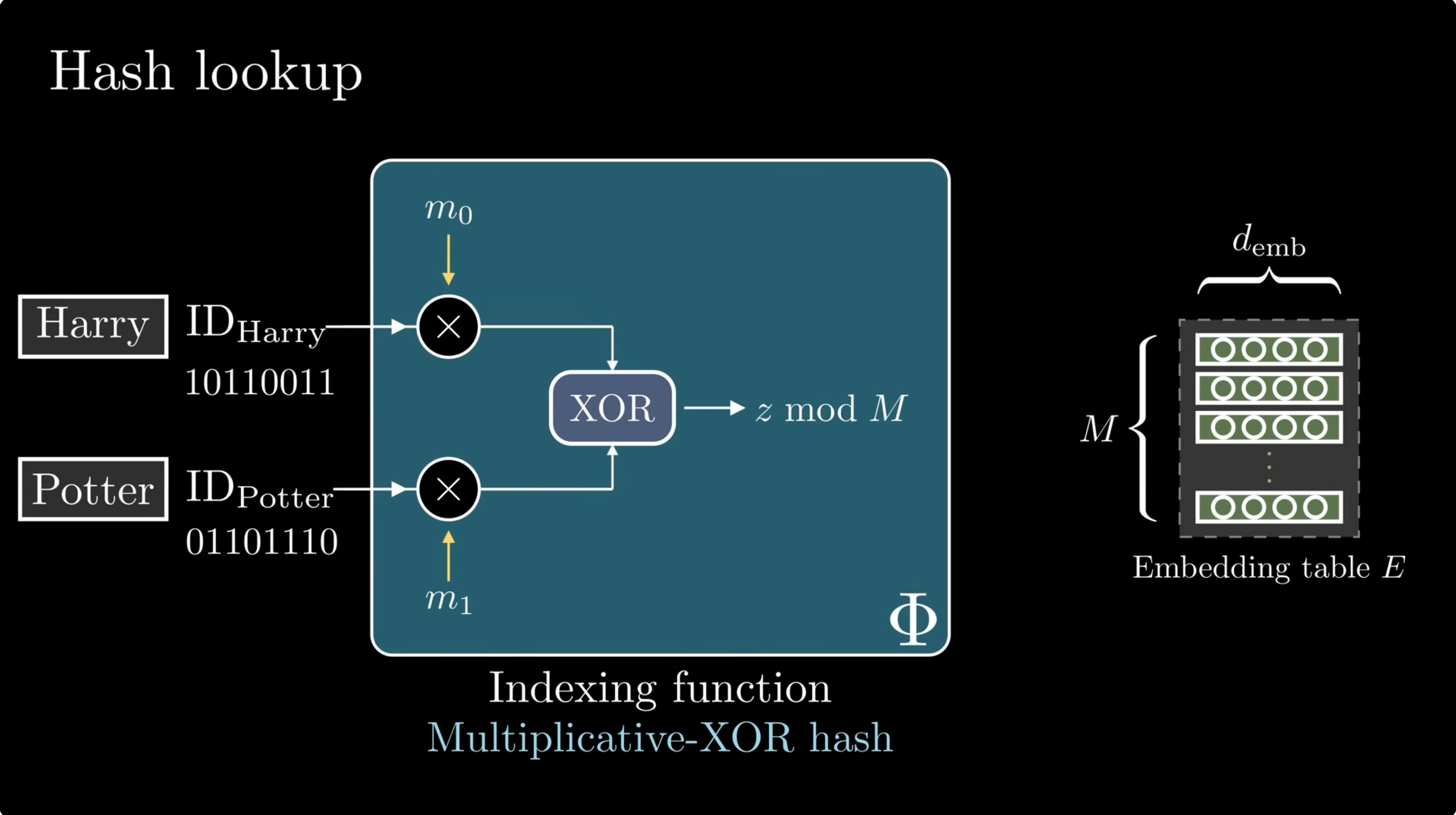
Paper Summary #17 - Engram
A technical explainer for DeepSeek's Engram layers: conditional memory, hashed n-gram lookup, context-aware gating, sparse-capacity allocation, and the implementation path inside Transformer blocks.
-
Paper Summary #16 - Canon Layers
A deep dive into Canon Layers: why sequence models need cheap horizontal token flow, how residual causal depthwise convolution implements it, and where Canon-A/B/C/D fit inside Transformer and linear-model blocks.

-
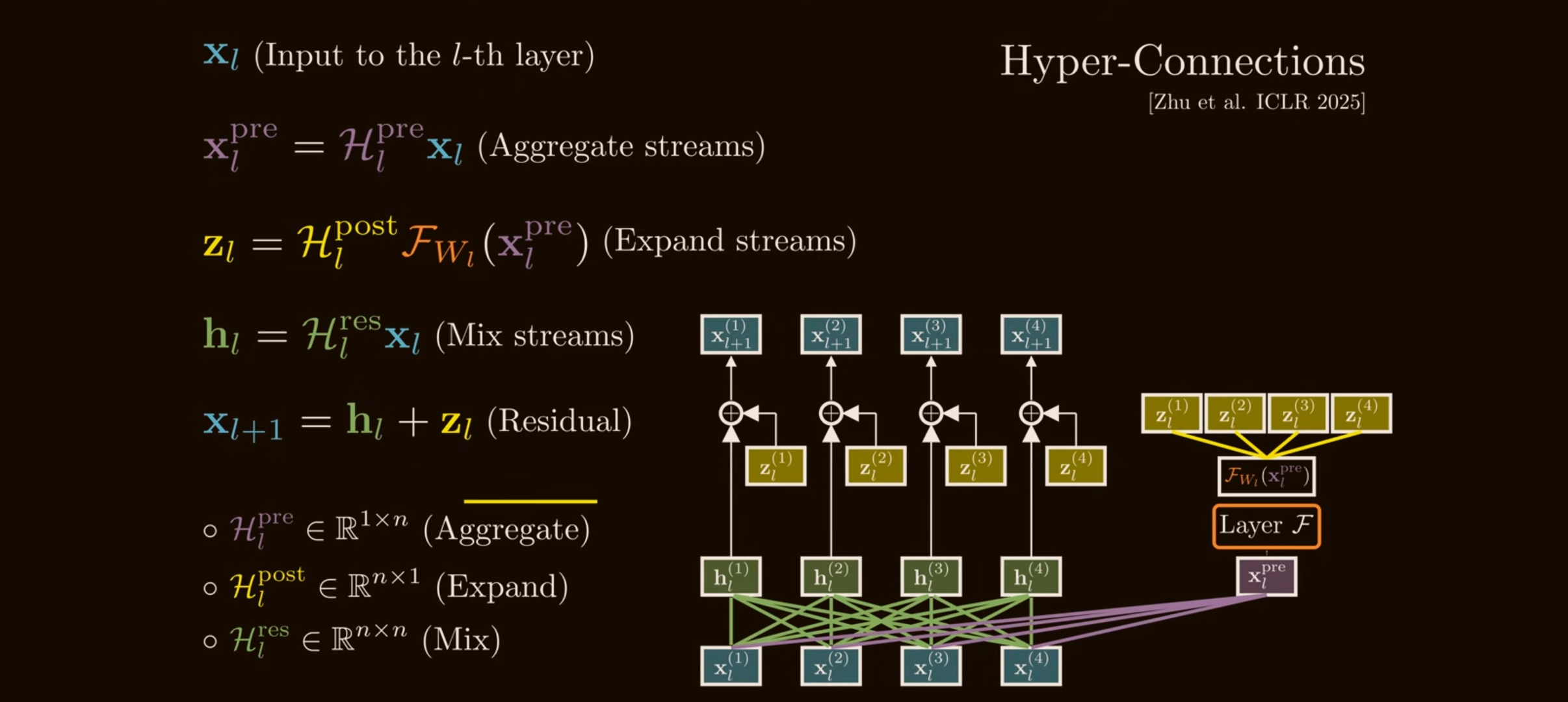
Paper Summary #15 - Hyper-Connections and mHC
From residual-stream basics to manifold-constrained mixing: why widening the residual path helps, why unconstrained products destabilize depth, and how Sinkhorn-Knopp turns HC into conservative feature routing.
-
Deep dive into CUDA Scan Kernels: Hierarchical and Single-Pass Variants
A guided tour of hierarchical and single-pass CUDA scan kernels with coarsening and warp-level optimizations.
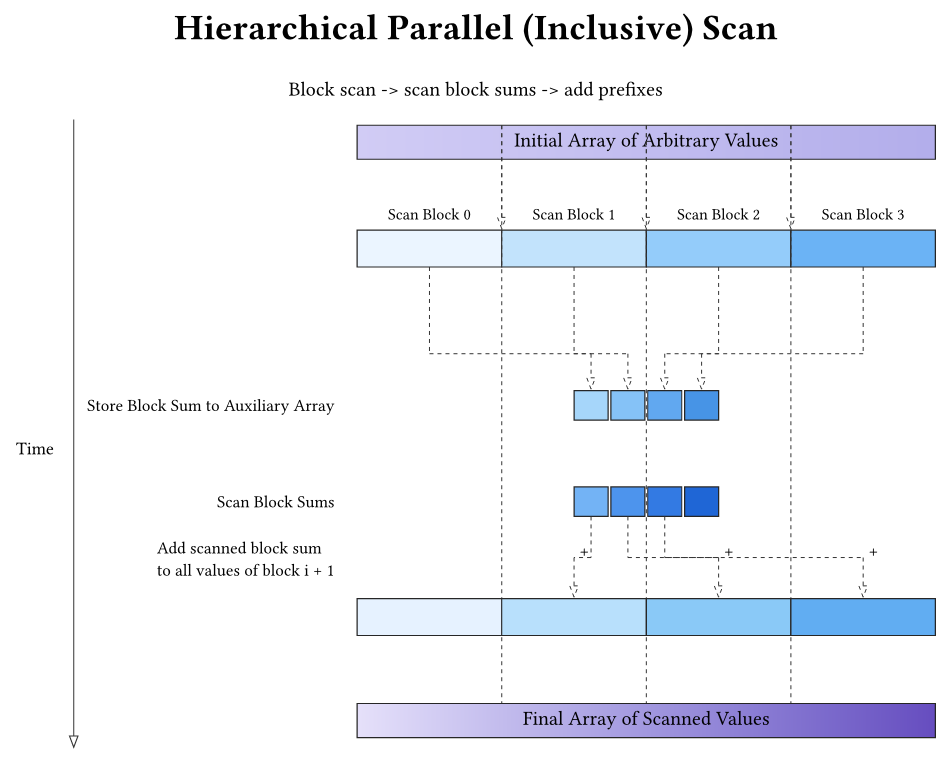
-
Paper Summary #14 - Physics of Language Models: Part 3.1, Knowledge Storage and Extraction
My notes from the Physics of Language Models series of papers.

-
Understanding Multi-Head Latent Attention (MLA)
A mathematical and code deep-dive on one of the key innovations from Deepseek - Multihead Latent Attention (MLA)
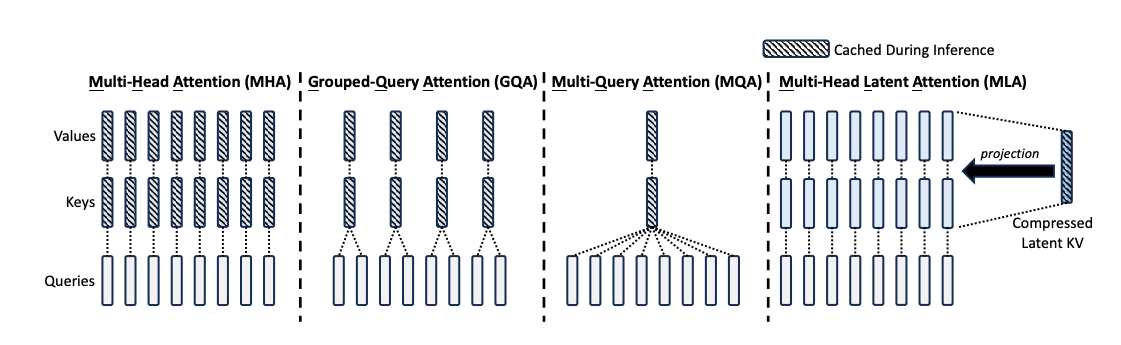
-
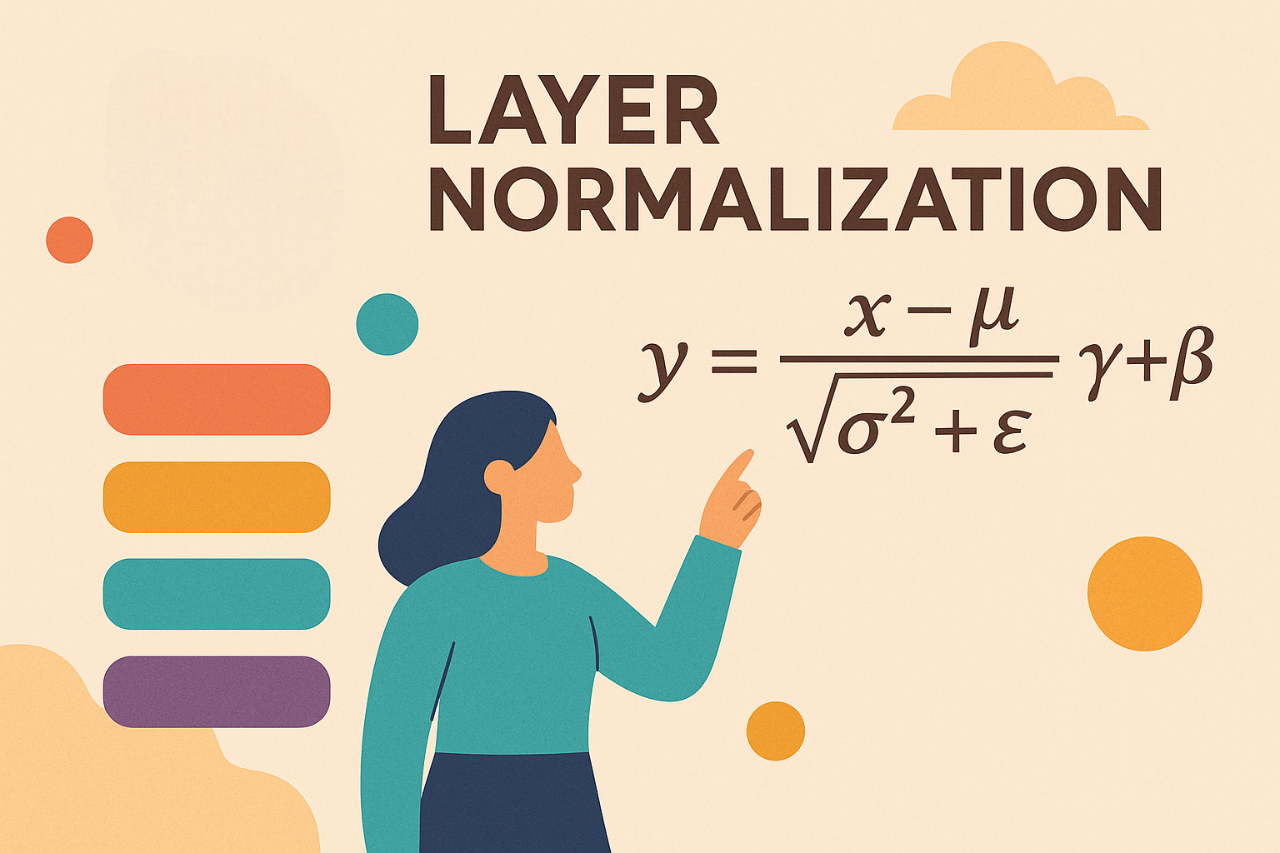
Deriving the Gradient for the Backward Pass of Layer Normalization
Understanding the math behind Layer Normalization and deriving the gradients for the backward pass.