Paper Summary #12 - Image Recaptioning in DALL-E 3

Technical Paper: Improving Image Generation with Better Captions
OpenAI’s Sora is built upon the image captioning model which was described in quite some detail in the DALL-E 3 technical report.
In general, in text-image datasets, the captions omit background details or common sense relationships, e.g. sink in a kitchen or stop signs along the road. They also omit the position and count of objects in the picture, color and size of the objects and any text present in the image.
OpenAI trained a captioner model to solve this.
An image captioner is similar to a language model that predicts the next token conditioned on the image and the past generated tokens. Since images are composed of many thousands of pixel values, conditioning on all of this information is very complex and inefficient. The solution DALL-E 3 used was to use CLIP’s compressed representational space to condition upon. OpenAI jointly pre-trained a captioner with a CLIP and a language modeling objective using this formulation on the text and image pairs.

However, this still doesn’t solve the reluctance of the captioning model to provide details, as mentioned above. The fine-tuning of this captioner to be more descriptive and helpful for the text-to-image task is done in two phases.
First, they built a small dataset of captions that describe only the main subject of the image. The captioner is fine-tuned on this dataset. Now the model is more biased towards describing the main subject of the image.
Next, they created a dataset of long, highly-descriptive captions describing the contents of each image in the fine-tuning dataset. In addition to the main subject, these captions describe the surroundings, background, text found in the image, styles, coloration, etc. as well. The captioner is then fine-tuned on this dataset to generate descriptive synthetic captions.

There is a still a problem though…
Text-to-Image diffusion models have a tendency to overfit to the text distribution. Using synthetic captions can lead to such issues since the captioner model can have many modal behaviours that won’t be apparent but can bias the text-to-image model when trained on the synthetic captions.
Examples of where this might occur is in letter casing, where punctuation appears in the caption (e.g. does it always end with a period?), how long the captions are, or stylistic tendencies such as starting all captions with the words “a” or “an”.
OpenAI overcame this issue by regularizing the text inputs to a distribution that is similar to the humans. The ground-truth captions provide this already since they were drawn from a distribution of human-written text. The regularization can be introduced during training the model by randomly selecting either the ground truth or synthetic caption with a fixed percent chance. DALLE-3 used 95% synthetic captions and 5% ground truth captions.
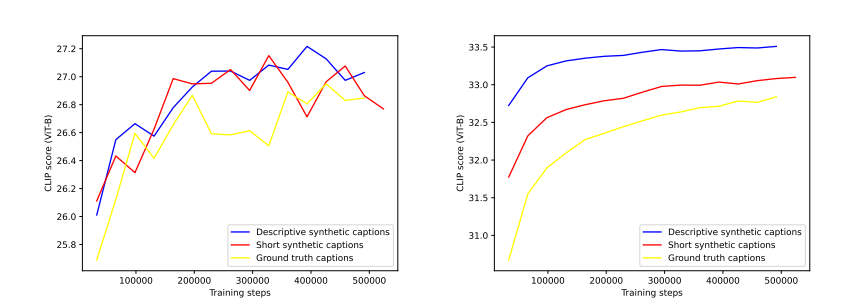
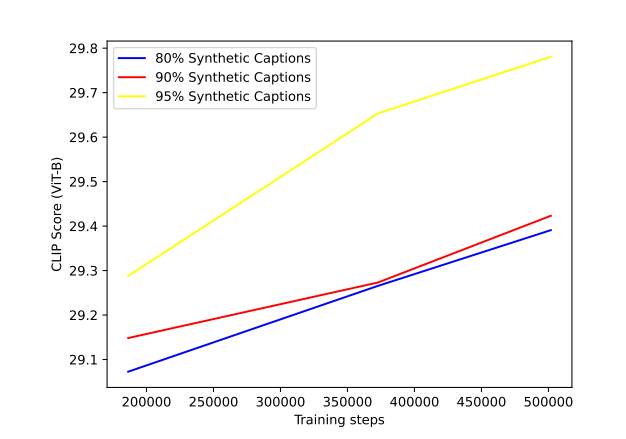
The above figure shows that using very high percentage of synthetic captions maximizes the performance of the models. But increasing the synthetic caption ratio implies biasing the model to the distribution of long, highly-descriptive captions emitted by the captioning model. OpenAI used GPT-4 to upsamples any caption into a highly descriptive one.
Here are some examples -

Below is the prompt OpenAI used to “upsample” the captions.
