Paper Summary #11 - Sora

Technical Paper: Sora - Creating video from text
Blog: Video generation models as world simulators
These are just short notes / excerpts from the technical paper for quick lookup.
Sora is quite a breakthrough. It is able to understand and simulate the physical world, generating up to 60s long high-definition videos while maintaining the quality, scene continuation and following the user’s prompt.
Key papers Sora is built upon -

Sora (being a diffusion transformer) uses the idea from ViT of using patches. The videos are converted to patches by first first compressing videos into a lower-dimensional latent space (as in the Latent Diffusion Models paper) and then decomposing the representation into spacetime patches.
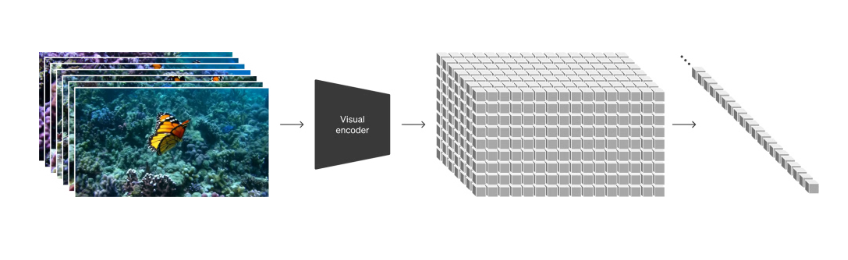
The network takes raw video as input and outputs a latent representation that is compressed temporally and spatially. The video training and generation is done within this latent space. A decoder model is also trained that maps generated latents back to pixel space.
A sequence of spacetime patches is extracted from the compressed video. The patch-based representation enables Sora to train on videos and images of variable resolutions, durations and aspect ratios. During inference time, an appropriately-sized grid (for the random patches) can be selected to control the size of the generated videos.
Hence, while past approaches resized, cropped or trimmed videos to a standard size, Sora can sample widescreen 1920x1080p videos, vertical 1080x1920 videos and everything inbetween. Training on the native aspect ratios was in fact helpful for the model to improve composition and framing. This is similar to what Adept did in Fuyu-8B.
How does it adhere to text so well?
OpenAI trained a very descriptive captioner model which they used to generate captions for all the videos in their training set (probably a finetuned GPT-4V ?). Training on highly descriptive video captions improves text fidelity as well as the overall quality of videos.
They also use query expansion - using GPT to turn short user prompts into longer detailed captions that are sent to the video model.
More details about the image captioner in the next blog post.
What are some emergent capabilities that are exhibited with scale?
- 3D consistency - Sora videos can shift and rotate elements based on the camera motion.
- Long-range coherence and object permanence
- Interacting with the world - Though not perfect, Sora can sometimes remember the state of the world after an action was taken.
- Simulating digital worlds - Sora can generate Minecraft videos, wherein it can simultaneously control the player with a basic policy while also rendering the world and its dynamics in high fidelity.