Paper Summary #2 - Deep contextualized word representations (ELMo)

Paper: Deep contextualized word representations
Link: https://arxiv.org/abs/1802.05365
Authors: Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, Luke Zettlemoyer
Code: https://bit.ly/3xpHNAI
Note - Since this is a relatively old paper, all the performance comparisons and state-of-the-art claims mentioned below should only be considered for the models at the time the paper was published.
What?
The paper proposes a new type of deep contextualized word representation that helps to effectively capture the syntactic and semantic characteristics of the word along with the linguistic context of the word. It can help differentiate the same word being used in different contexts with different meanings. The representations (embeddings) are learned from the internal states of a deep bidirectional language model (biLM). The embeddings, when used with the existing models, significantly improved the state of the art in six NLP problems - Question Answering, Natural Language Inference, Semantic Role Labeling, Coreference Resolution, Named Entity Recognition and Sentiment Analysis.
Why?
The existing word representations commonly in use were Word2Vec and GloVe. However, there was a need to capture even richer word representations. The paper states that the two main requirements of a good representation should be that they should be able to capture the complex characteristics of the word use and at the same time capture polysemy as well. This is the idea behind using ELMo (Embeddings from Language Models) representations.
How?
As a high-level overview, it can be said that the ELMo representations are a function of the entire input sequence. A two-layer biLM model with character-level convolutions is trained on a text corpus. The ELMo word representations are computed as a linear function of the internal network states of the biLM. The biLM is pretrained on a large scale and the ELMo representations can be incorporated into several deep learning-based NLP architectures.
biLM (Bidirectional Language Model)
A forward language model computes the probability of the sequence by modelling the probability of a token tk given the history (t1, …, tk-1). Similarly, a backward language model predicts the previous token given the nature context i.e., it performs the same function but in reverse order.
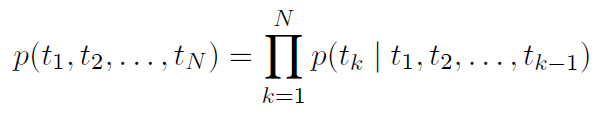
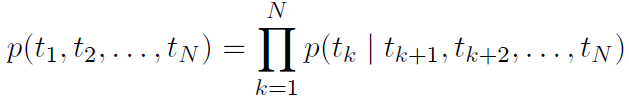
In a forward LM, a context-independent token representation xkLM is obtained from a character-level CNN and then passed through L layers of LSTMs. At each position k, the LSTM layer outputs a context-dependent representation hk,jLM, where j = 1, …, L. the top layer of the LSTM output is used to predict the next token tk+1 with a Softmax layer. The same procedure is applied to the backward LM as well.
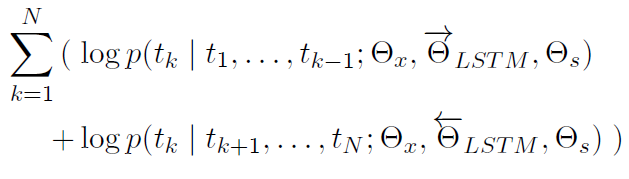
A biLM combines both the forward and backward LM. The above formulation jointly optimizes the log-likelihood of the forward and backward directions.
The formulation ties both the token representation \(\Theta_x\) and the Softmax layer Θs. Separate parameters are maintained for the forward and backward LSTMs.
Next, we look at getting the word representations using ELMo.
ELMo
ELMo is a task-specific combination of the intermediate layer representations of the biLM model. If we have L LSTM layers, then for each token tk we have 2L + 1 representations.
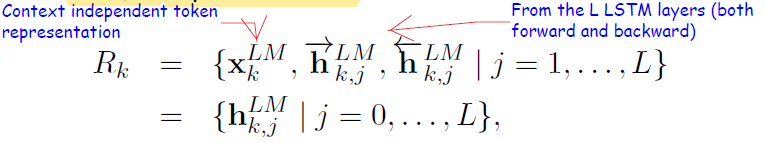
Now to get one single vector for each token, all the representations in R are merged to one. Usually, task-specific weighting is performed.
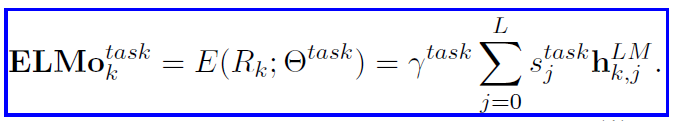
The stask are softmax normalized weights and the scale parameter γtask allows the task model to scale the entire ELMo vector. In some cases, applying LayerNorm to each biLM layer before weighting also helped.
Using ELMo for supervised NLP tasks
We start with a pretrained biLM model, The biLM is run to record the layer representations for each word. When using any supervised deep learning MLP model have a common architecture for the lowest layers. They usually use a context-independent token representation xk for each token position using pre-trained embeddings and optionally also using character-based representations. Then, in the higher layers, the model forms context-sensitive representations using RNNs, CNNs or whatever, as per the task and the model. For using ELMo, we can start in the same manner. We obtain the embeddings from the freezed weights of the biLM. Now instead of passing just xk to the above layers, we will pass </br> [xk; ELMoktask ] into the task model layers. For some tasks like SNLI (Natural language Inference) and SQuAD (Question-Answering), it was also seen that including ELMo at the output of the task model by introducing another set of output specific linear weights and replacing hk with [hk; ELMoktask ] led to an improvement.
Additionally, in some cases, regularizing the ELMo weights with \(\lambda {\lVert x \rVert}_2^2\) helped introduce an inductive bias on the ELMo weights to make it stay close to the average of all biLM layers.
Pre-trained bidirectional language model architecture
The pre-trained biLM used in the paper is similar to the architecture in Józefowicz et al.. It is modified to support joint training of both directions and a residual connection is added between the LSTM layers. The size of the embeddings and layers were from what was in the CNN-BIG-LSTM architecture in Józefowicz et al.. The final model has L=2 biLSTM layers with 4096 units and 512-dimensional embeddings and a residual connection from the first to the second layer. The context insensitive type representation uses 2048 character n-gram convolutional filters followed by two highway layers and a linear projection down to a 512 representation. As a result, the biLM provides three layers of representations for each input token, including those outside the training set due to the purely character input.
Results
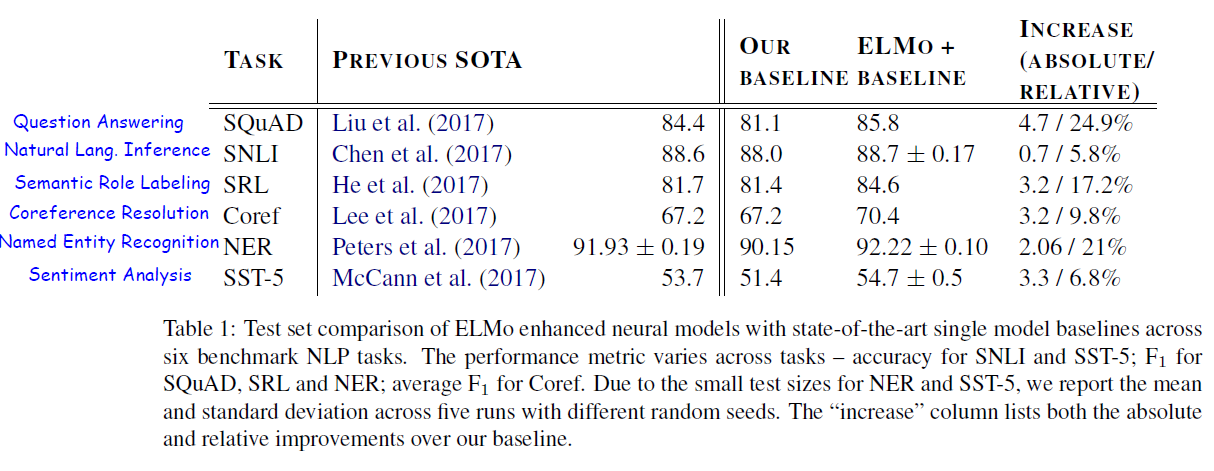
The details of the baseline models are given in the paper. In all the tasks, the use of the ELMo representations led to improvement in the state-of-the-art results.
Key points from the analysis section -
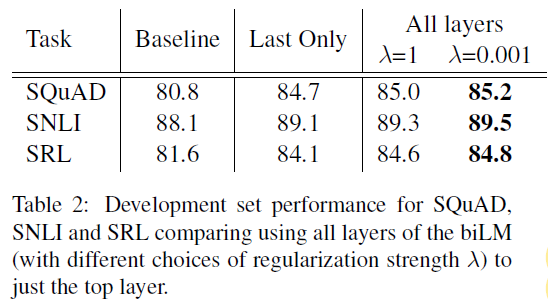
- Regularization parameter λ is important. λ=1 means that we are effectively reducing the weighting function to a simple average over the layers, while smaller values like λ=0.001 allows the layer weights to vary.
- The fact that we take the representations from all the layers gives a better performance as compared to just taking the topmost layer. Taking just the last layer is still better than the baseline.
- A small λ is preferred in most cases with ELMo, although for NER, a task with a smaller training set, the results are insensitive to λ.
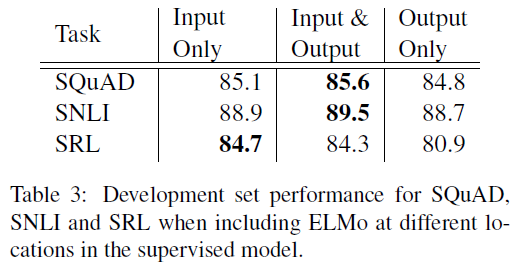
- Including ELMo at both the input and output layers for SNLI and SQuAD improves over just the input layer. This is because SNLI and SQuAD use an attention layer after the biRNN and using ELMo at the output layer would allow the model to attend directly to the internal representations of the biLM. But for SRL (and coreference resolution) performance is highest when it is included at just the input layer. Probably because the task-specific context representations are more important than those from the biLM.
- The higher-level LSTM states of the biLM capture context-dependent aspects of word meaning (e.g., they can be used without modification to perform well on supervised word sense disambiguation tasks) while lower-level states model aspects of syntax (e.g., they can be used to do part-of-speech tagging).
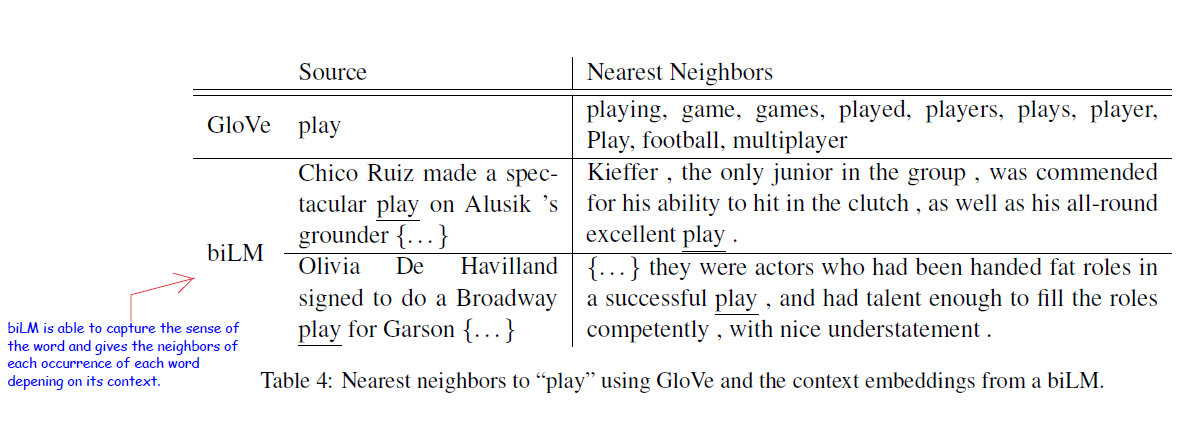
-
Different layers in the biLM represent different types of information and explains why including all biLM layers are important for the highest performance in downstream tasks.
-
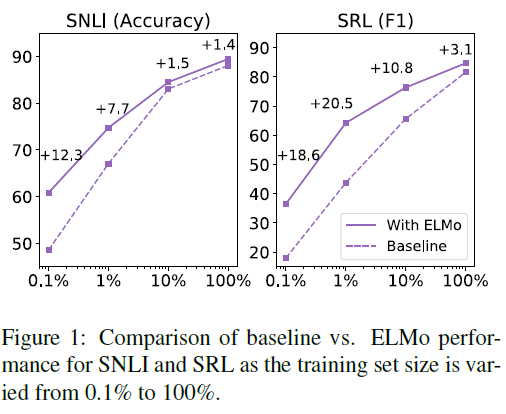
Using ELMo with a model also improves the sample efficiency. The model now requires a fewer number of epochs (parameter updates) and less amount of training data as well. For eg., the baseline SRL model requires 486 epochs to reach the maximum F1 score. The model with the ELMo representations only requires 10 epochs to exceed the baseline. In addition, ELMo-enhanced models use smaller training sets more efficiently than models without ELMo. Again, if we consider the SRL case, the ELMo model with 1% of the training set has about the same F1 as the baseline model with 10% of the training set.
I have also released an annotated version of the paper. If you are interested, you can find it here.
This is all for now!