Paper Summary #3 - Improving Language Understanding by Generative Pre-Training

Paper: Improving Language Understanding by Generative Pre-Training
Link: https://bit.ly/3xITvGP
Blog: https://openai.com/blog/language-unsupervised/
Authors: Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever
Code: https://bit.ly/3gUFrUX
What?
The paper proposes a semi-supervised technique that shows better performance on a wide variety of tasks like textual entailment, question answering, semantic similarity text classification by using a single task-agnostic model. The model can overcome the constraints of the small amount of annotated data for these specific tasks by performing an unsupervised generative-pretraining of a language model on a large diverse text corpus followed by supervised discriminative fine-tuning on each specific task. The pretraining model remains the same for all the tasks. Only a small, task-aware input adaptation is required when performing the fine-tuning. The model significantly improved the state-of-the-art (at the time) in 9 of the 12 tasks studied.
Why?
Most deep learning models require a substantial amount of data, which makes them difficult to train for tasks in which there is a dearth of good quality annotated data. Historically, pre-trained word embeddings have been used for such cases but the word-level information in itself is sometimes not enough for many of the complex tasks.
How?
The goal of the model is to learn a universal representation that transfers with little adaptation to a wide range of tasks. The paper assumes access to a large corpus of unlabeled text and several datasets with manually annotated training examples (the target tasks). The unlabeled corpus and the annotated datasets need not be in the same domain.
A two-stage training procedure is used. First, a language modelling (LM) objective is used on the unlabeled data to learn the initial parameters of the model. Next, these parameters are adapted to a target task using the corresponding supervised objective.
A Transformer (specifically a Transfomer decoder) is used as the underlying architecture. Transformers work better than LSTMs (shown in the results as well) because they can capture long-term dependencies well which results in robust transfer performance across diverse tasks. Furthermore, during the transfer, as mentioned above, task-specific input adaptations are used which process the structured text input as a single contiguous sequence of tokens. This is something very interesting and will be shown in the subsequent sections.
Unsupervised pre-training
A standard forward LM objective is used to maximise the likelihood -
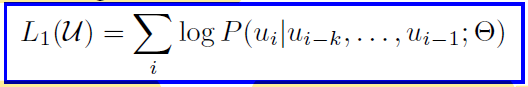
Here, , U is the corpus of tokens {u1,… un}, k is the context window size and the conditional probability P is modeled using a network with parameters Θ. SGD is used to learn the parameters. The model uses a multi-layer Transformer decoder. The multi-head self-attention is applied over the input context tokens. This is followed by position-wise feedforward layers to produce an output probability distribution over the target tokens.

Here U is (u-k,…, u-1) which is the context vector of tokens, n is the number of layers, We is the token embedding matrix and Wp is the position embedding matrix.
Supervised fine-tuning
After the training of the model with optimization L1, the parameters are now adapted to the supervised target task. The labelled dataset is denoted by C, where each instance is a sequence of input tokens, x1,…,xm, along with a label y. The inputs are passed through the pre-trained model to obtain the final transformer block’s activation hlm, which is then fed into an added linear output layer with parameters Wy to predict y.
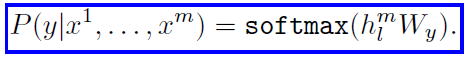
The objective to be maximized is as follows
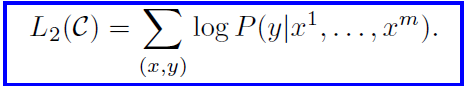
Using an LM objective as an auxiliary objective to the finetuning helped to improve the generalization of the supervised model and make it converge faster.
The overall objective can be written as -
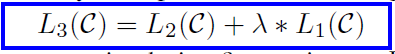
Task-specific input transformations
Since the pretrained model is trained on a contiguous sequence of texts, to handle the inputs of the various tasks, certain input transformations are needed as shown above. These transformations help to avoid making extensive changes to the architecture across tasks.
- Textual Entailment - The premise (p) and the hypothesis (h) sequences are concatenated with a delimiter token in between.
- Similarity - Since there is no inherent ordering of the two sequences being compared, the input sequence is modified to contain both possible sentence orderings (with a delimiter in between). Each of these concatenated sequences is processed independently to produce two sequence representations hlm which are then element-wise added before feeding to the linear output layer.
- Question Answering - This one is interesting. For a given context document z, question q and a set of possible answers {ak}. The document and question are concatenated with each of the possible answers, with a delimiter token in between [z; q;$;ak]. Each of these sequences is processed independently by the model and then normalized by a softmax layer to produce an output distribution over possible answers.
The model specifications for the experimental setup are shown below -

Results
The datasets that were used are listed below -

- Natural Language Inference - This task is challenging due to the presence of a wide variety of phenomena like lexical entailment, coreference, and lexical and syntactic ambiguity. The model performs better than the state-of-the-art in 4 (MNLI, QNLI, SNLI, SciTail) out of 5 datasets.
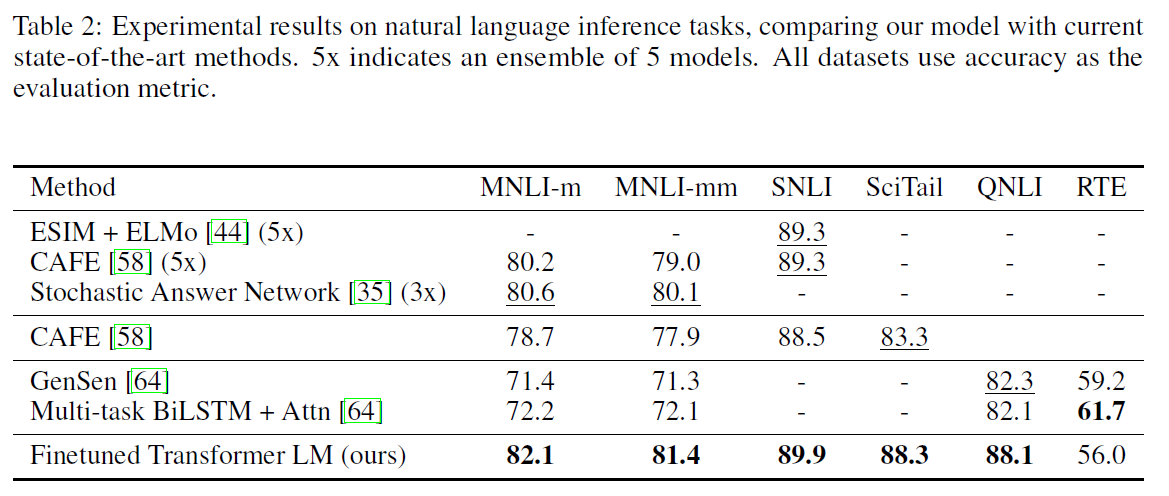
- Question Answering and Commonsense Reasoning - The RACE dataset (passages with associated questions from middle and high school exams) and Story Cloze dataset (selecting correct ending to multi-sentence stories from two options) were used. The model outperformed the baseline on both these datasets.
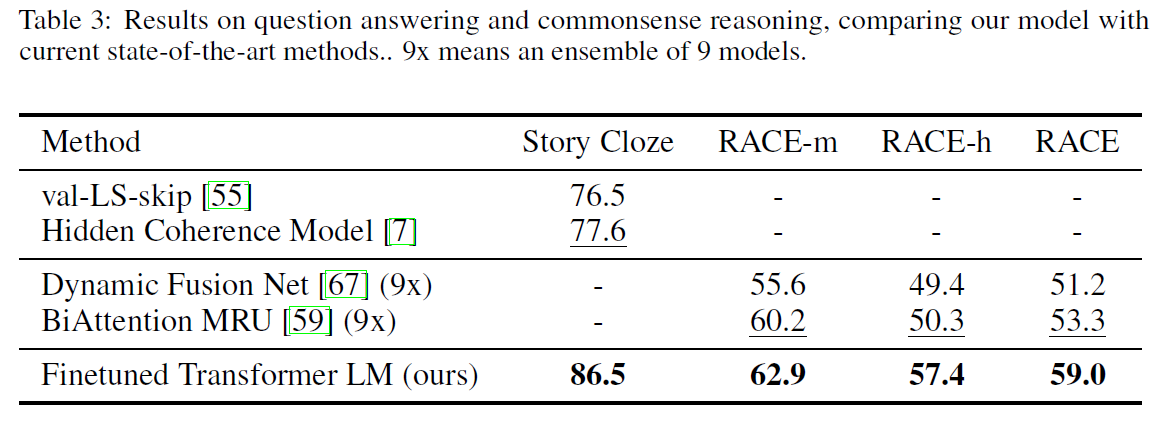
-
Semantic Similarity - The challenges in this task are recognizing rephrasing, negation, and handling ambiguity. The model performs better on 2 (QQP and STS-B) of the 3 datasets.
-
Classification - The model performs better on both Corpus of Linguistic Accepttability (CoLA) dataset and is at par with the state-of-the-art results on the Stanford Sentiment Treebank dataset.
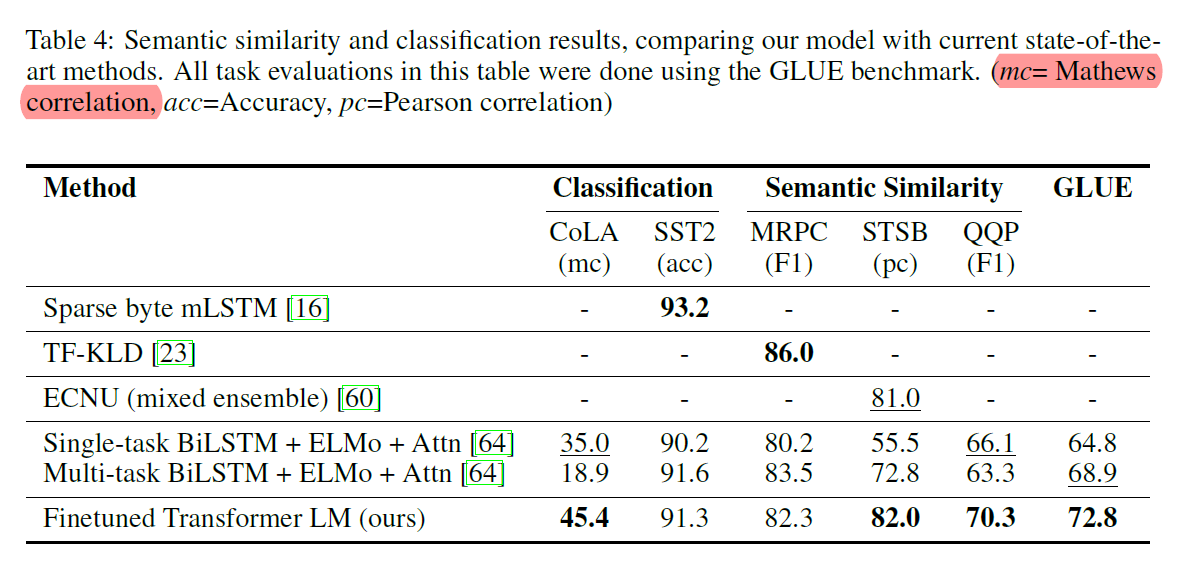
Key points from the analysis section -
- More the number of layers that are transferred from the pretrained model to the supervised target task, the better is the performance on the target tasks.
- To understand whether the unsupervised pre-training is effective or not, zero-shot testing was also performed i.e., using the pre-trained model directly without any finetuning. The model performance is stable and steadily increases over training suggesting that the generative pre-training supports the learning of a wide variety of task-relevant functionality. LSTMs exhibit higher variance in their zero-shot performance. The testing and input transformations for using the pretrained model directly are explained below -

- From the ablation studies, the authors show that the auxiliary LM objective helps on the NLI tasks and QQP (Quora Question Pairs data).
- Overall, larger datasets benefit from the auxiliary objective more than the smaller datasets.
- In general, the Transformer architecture performs better than a 2048 unit single layer LSTM model (if the Transformer in the pretraining model is replaced by an LSTM) on all datasets except the MRPC (Microsoft Paraphrase Corpus for semantic similarity) dataset.
- On comparing this model with the same transformer architecture trained in a supervised manner, it is observed that the model with pre-training performs better. This consistent for all the tasks mentioned in the paper, suggesting that pre-training helps to capture important linguistic information which is not captured when training with a supervised approach alone.
I have also released an annotated version of the paper. If you are interested, you can find it here.
This is all for now!