Paper Summary #4 - BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding

Paper: BERT - Pre-training of Deep Bidirectional Transformers for Language Understanding
Link: https://bit.ly/3bdTUra
Authors: Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
Code: https://bit.ly/3vRXlM7
What?
The paper proposes BERT which stands for Bidirectional Encoder Representations from Transformers. BERT is designed to pre-train deep bidirectional representations from unlabeled text. It performs a joint conditioning on both left and right context in all the layers. The pre-trained BERT model can be fine-tuned with one additional layer to create the final task-specific models i.e., without substantial task-specific architecture modifications. BERT achieves SOTA results on eleven NLP tasks such as natural language inference, question answering textual similarity, text classification, etc.
Why?
The existing strategies for the pre-trained language representations are mostly based on unidirectional language models and hence are not very effective in capturing the entire context for sentence-level tasks. These are also harmful when applying fine-tuning based approaches to token-level tasks such as question answering, where it is crucial to capture context from both directions. BERT aims to generate deep bidirectional representations by using maked language models.
How?
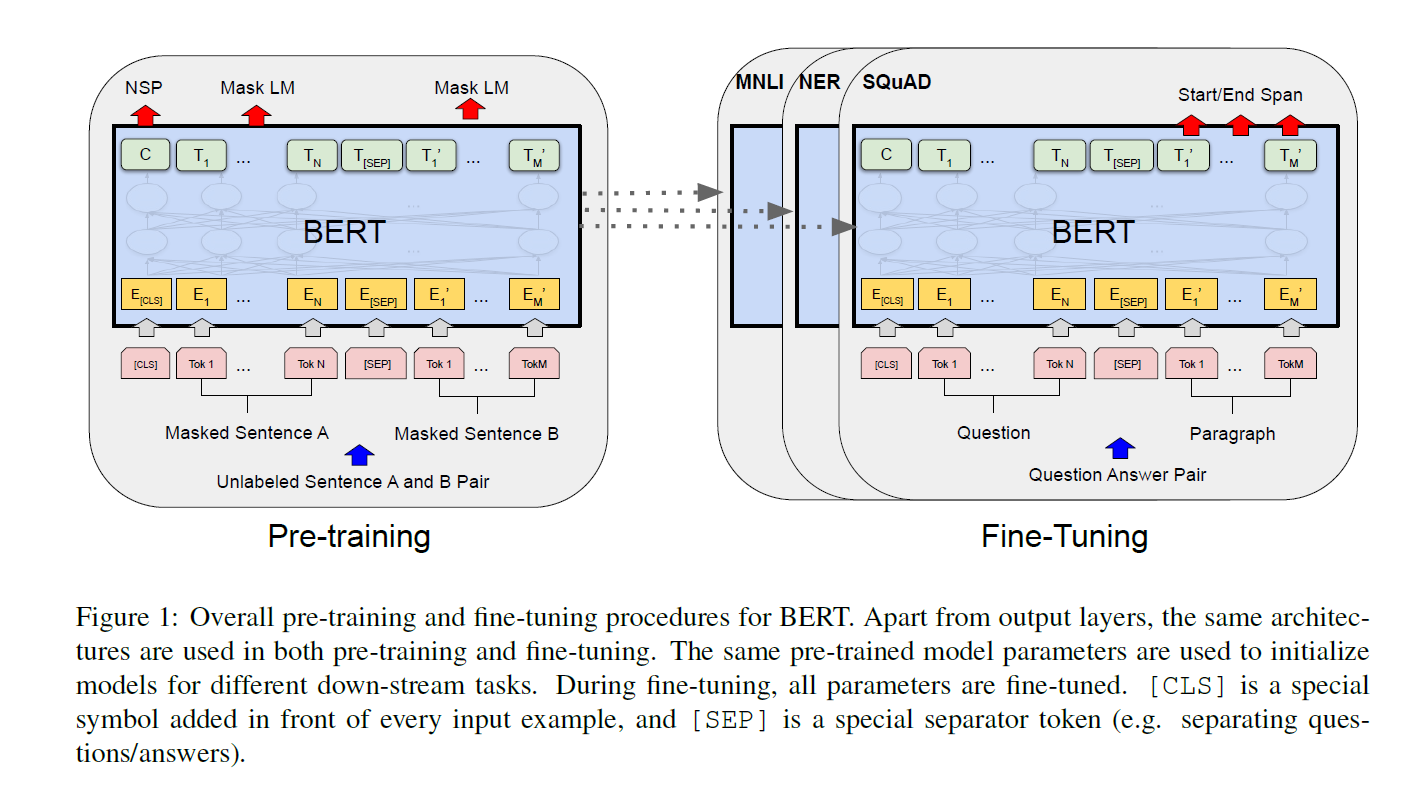
Two main steps in the BERT framework are - pre-training and fine-tuning. Pre-training involves training the model on unlabeled data over different pretraining tasks. During fine-tuning, all the BERT parameters are fine-tuned using the labelled data from the downstream tasks. The fine-tuned model is different for each task, however, they share the same pre-trained parameters.
Model Architecture
The underlying architecture of BERT is a multi-layer Transformer encoder, which is inherently bidirectional in nature. Two models are proposed in the paper.
- BERTBASE - 12 Transformer blocks, 12 self-attention heads, 768 is the hidden size
- BERTLARGE - 24 transformer blocks, 16 self-attention heads, 1024 is the hidden size
The model size of BERTBASE and Open AI’s GPT was chosen to be the same.
Input-Output Representations
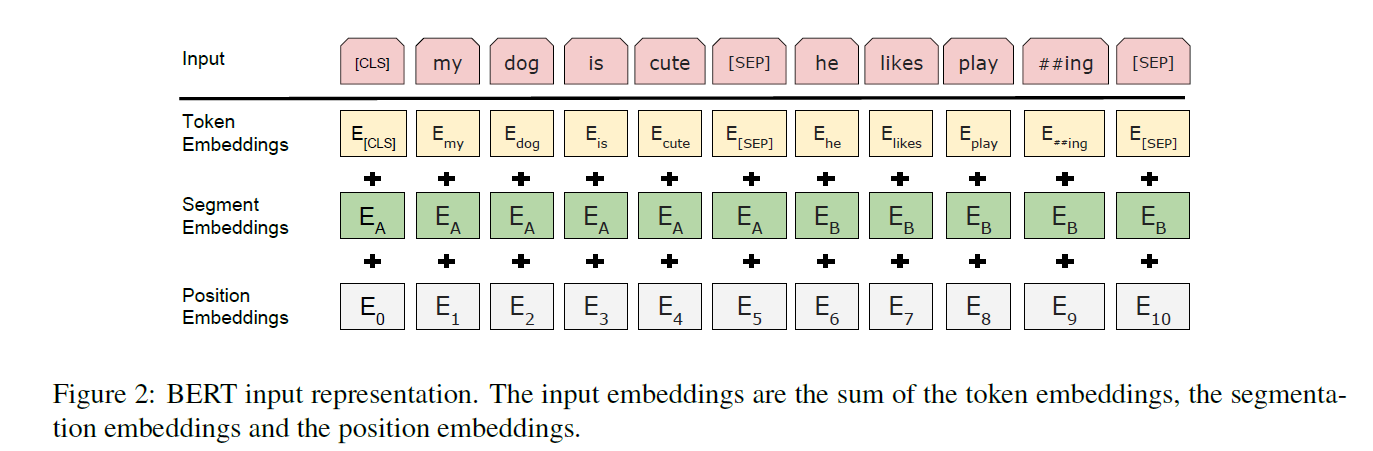
BERT uses WordPiece embeddings with a 30,000 token vocabulary. The first token of every sequence is ([CLS]). The final hidden state corresponding to the [CLS] token is used as the aggregate sequence representation.
To deal with sentence pairs, BERT uses a special token [SEP] to separate the two sentences. A learned embedding is added to every token indicating whether it is the first or the second sentence. The input embedding for each token is obtained by adding the corresponding token embedding (WordPiece embedding), segment embedding (first / second sentence) and position embedding (as in Transformers).
BERT pre-training
BERT is pre-trained using two unsupervised tasks.
Masked LM
The bidirectional model is more powerful than either a left-to-right model or the shallow concatenation of a left-to-right and right-to-left model.
In order to train a deep bidirectional representation, some percentage (15% in the paper) of the input tokens are masked at random, and those masked tokens are predicted using an output softmax over the vocabulary. This is called a masked LM. The masking is performed by replacing the token with a [MASK] token. Now since the [MASK] token does not appear during fine-tuning, the [MASK] token is used 80% of the time. For 10% of the selected tokens (from the 15%) a random token is used to replace it and the token is kept unchanged for the rest 10%. The token is then predicted using cross-entropy loss.
Next Sentence Prediction (NSP)
To understand the relationship between two sentences (which is not captured by language modelling), a binarized NSP task is formulated. Here, when choosing the sentences A and B (refer to the model pre-training figure above) for each pre-training example, 50% of the time B is the actual next sentence and the rest 50% of the time, a random sentence from the corpus is used. The vector C (without fine-tuning) is used for NSP. This is helpful for tasks like Question Answering and Natural Language Inference.
Pre-training data
It is useful for BERT to use a document-level corpus rather than a shuffled sentence-level corpus. BERT 9as in the paper) uses the BookCorpus (800M words) and English Wikipedia (2500M words).
Fine-tuning BERT
Instead of independently encoding text (sentence) pairs and then applying bidirectional cross attention, BERT uses the Transformer model architecture’s self-attention mechanism. Encoding the concatenated text (sentence) pair with self-attention effectively incorporates bidirectional cross attention between the two sentences.
The fine-tuning is performed for all the parameters and the task-specific inputs and outputs of the downstream task are plugged for fine-tuning.
- A and B are the sentence pairs in case of paraphrasing
- A and B are hypothesis-premise pairs in the entailment task
- A and B are question-passage pairs in question answering
- A and B are the text and Φ in text classification or sequence tagging task
At the output, for the token-level tasks (sequence tagging, question answering), the token representations are fed into the output layer. For the sentence-level tasks, the representation of the [CLS] token is fed to the output layer for classification.
Results
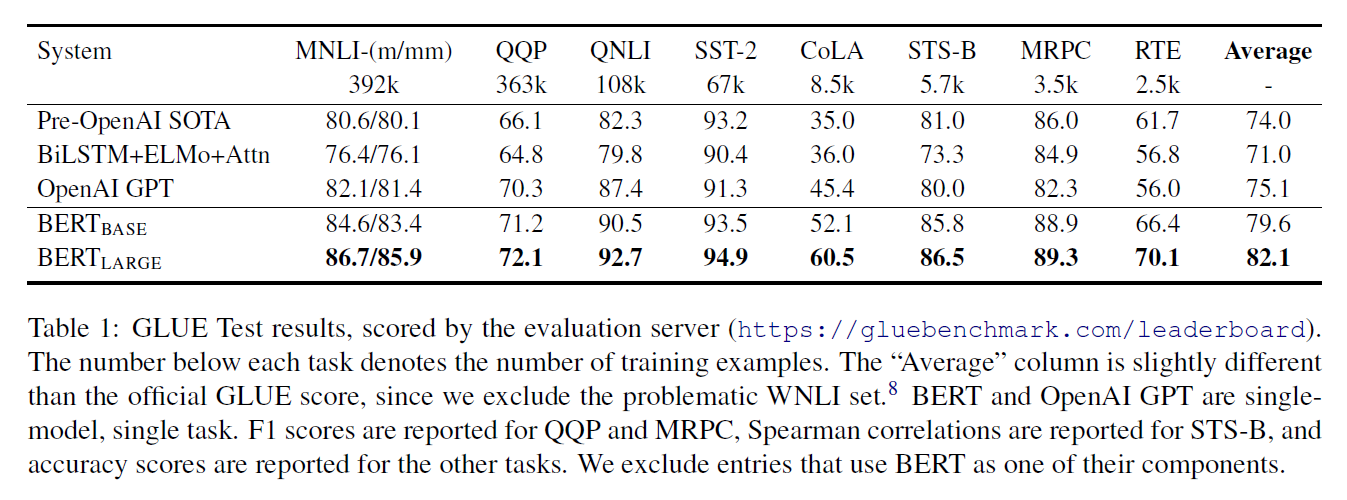
GLUE - The General Language Understanding Evaluation benchmark is a collection of a number of diverse NLP tasks. The 8 datasets the paper evaluates on, are shown below. For these tasks, the [CLS] representation (hidden vector associated with it) is used. The classification layer (a single layer is used) and its weights are the only new parameters introduced. Standard log softmax loss is used. The model used a batch size of 32 and was fine-tuned for 3 epochs. The learning rate was chosen from a list based on performance on the validation set. BERTLARGE was unstable on small datasets so random restarts were done with data shuffling and classification layer initialization. It was found that BERTLARGE significantly outperforms BERTBASE (and all other models) across all tasks, especially those with very little training data.
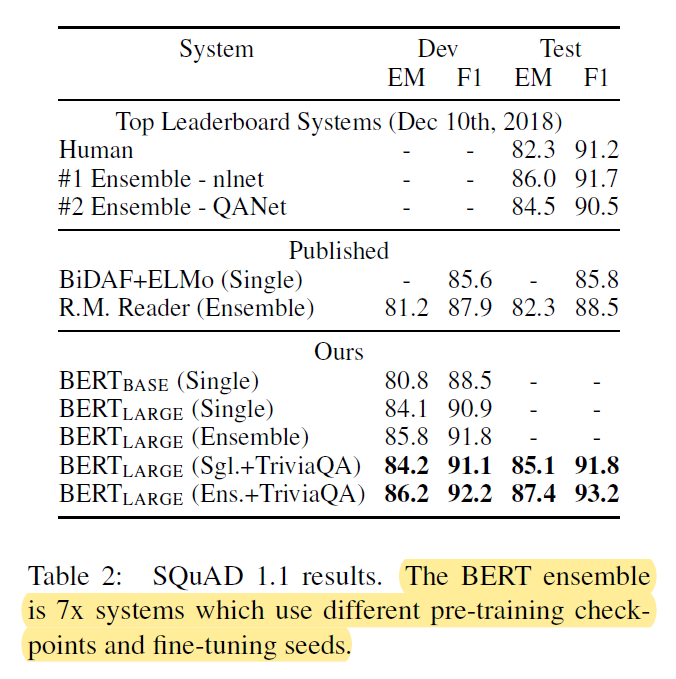
SQuAD v1.1 - A collection of 100k question-answer pairs. Given a question and a passage, the task is to predict the answer span in the text. The question and the passage are represented using A and B embedding respectively. A start vector S and end vector E is introduced in the output. The probability of token i being the start of the answer is given as
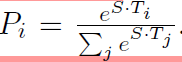
and similarly for the end token. The score of a candidate span from position i to position j is decided to be -
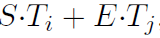
This objective is maximised to get the answer range. Batch size of 32, learning rate of 5e-5 was used and the model was fine-tuned for 3 epochs. Also, for enhanced performance, a prior fine-tuning on the Trivia-QA dataset was done before the fine-tuning on SQuAD.
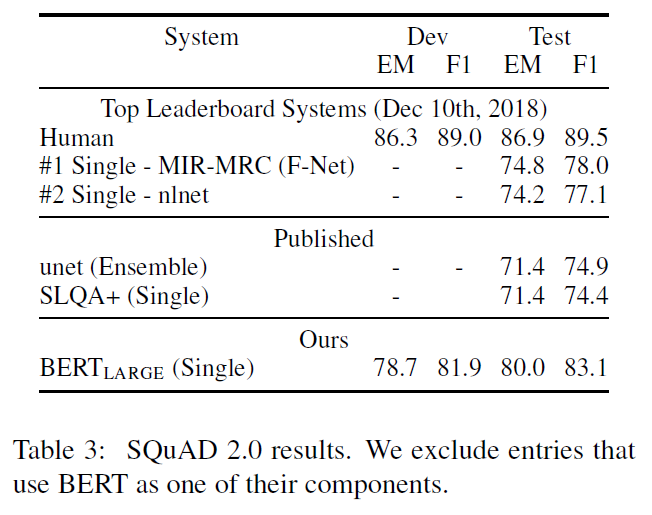
SQuAD v2.0 - This task allows for the possibility of no short answer existing in the passage for the question, to present a more realistic situation. So, in this case, for the questions which don’t have an answer, the start and end is set to be the [CLS] token. So, now there is also a snull = S•C + E•C as the no-answer span score. For a non-null answer, a si,j = S•Ti + E•Tj is defined. A non-null answer is predicted when si,j > snull + τ. τ is decided on the basis of the performance of the model on the validation set. TriviaQA data was not used for this model. The model was fine-tuned for 2 epochs with a learning rate of 5e-5 and a batch size of 48.
SWAG - The Situations With Adversarial Generations (SWAG) dataset contains 113k sentence-pair completion examples that evaluate grounded commonsense inference. Given a sentence, the task is to choose the most correct continuation of the sentence among four choices. Scoring is performed for the four sentence pairs, the given sentence A and the possible continuation B. Here a vector is introduced whose dot product with the [CLS] token representation C denotes the score for each of the four choices and a softmax layer is used to get the probability distribution. The model was fine-tuned for 3 epochs with a learning rate of 2e-5 and a batch size of 16.
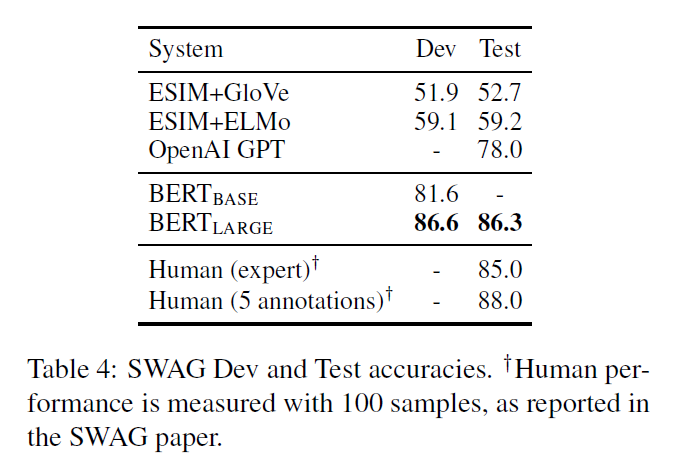
Key points from the analysis/ablation studies section -
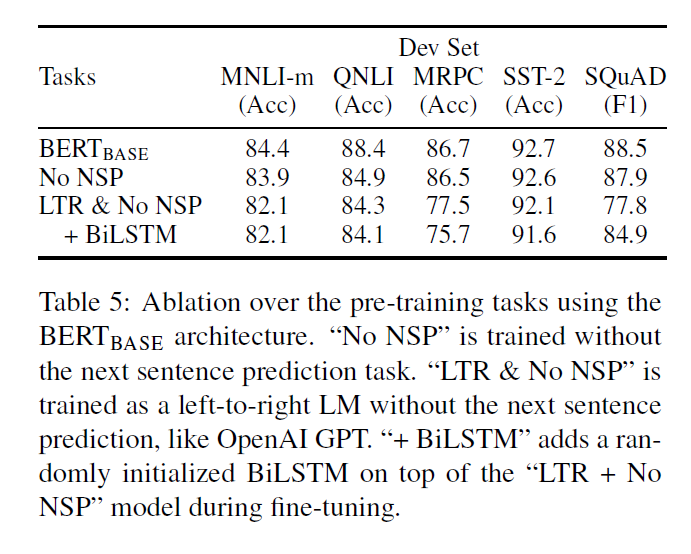
- Two additional modes of pre-training were performed.
- No NSP - The model is pre-trained with mask LM but not with the NSP task.
- LTR and No NSP - Instead of a masked LM, a standard left-to-right LM is used and the NSP task is again not performed.
- The LTR model performs worse than the MLM model on all tasks, with large drops on MRPC and SQuAD.
- An LTR model performs poorly on token predictions and hence doesn’t perform well on SQuAD.
- For strengthening the LTR models, a randomly initialized BiLSTM model is added on the top. This improves the results on SQuAD but does not perform well on the GLUE tasks.
- Separately training LTR (left-to-right) and RTL (right-to-left) models and concatenating them for the token representations is an approach similar to ELMo. But the authors mention that this is twice as expensive as a single bidirectional model. Also, this is unintuitive for tasks like Question Answering since the RTL model would not be able to condition the answer on the question. Furthermore, it is less powerful than a deep bidirectional model, since it can use both left and right context at every layer.
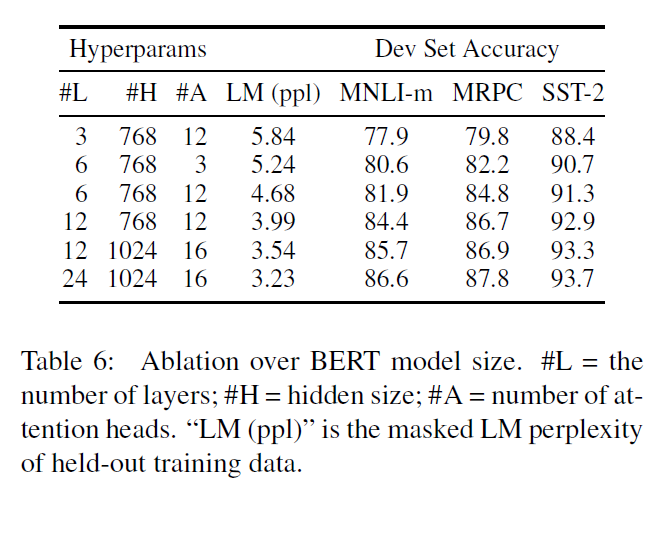
- BERTBASE contains 110M parameters and BERTLARGE contains 340M parameters.
- Larger models lead to a strict accuracy improvement across all four datasets, even for MRPC (paraphrasing) which only has 3,600 labelled training examples.
- BERT claims to be the first model to demonstrate convincingly that scaling to extreme model sizes also leads to large improvements on very small scale tasks, provided that the model has been sufficiently pre-trained.
- When the model is fine-tuned directly on the downstream task and uses only a very small number of randomly initialized additional parameters, the task-specific models can benefit from the larger, more expressive pre-trained representations even when downstream task data is very small.
- The feature-based model, in which fixed features are obtained from the model, has some advantages. Firstly, not all tasks can be modelled using a Transformer encoder and require task-specific model architecture to be added.
- Secondly, pre-computing the expensive representations and using them for multiple experiments with cheaper models is a computational benefit.
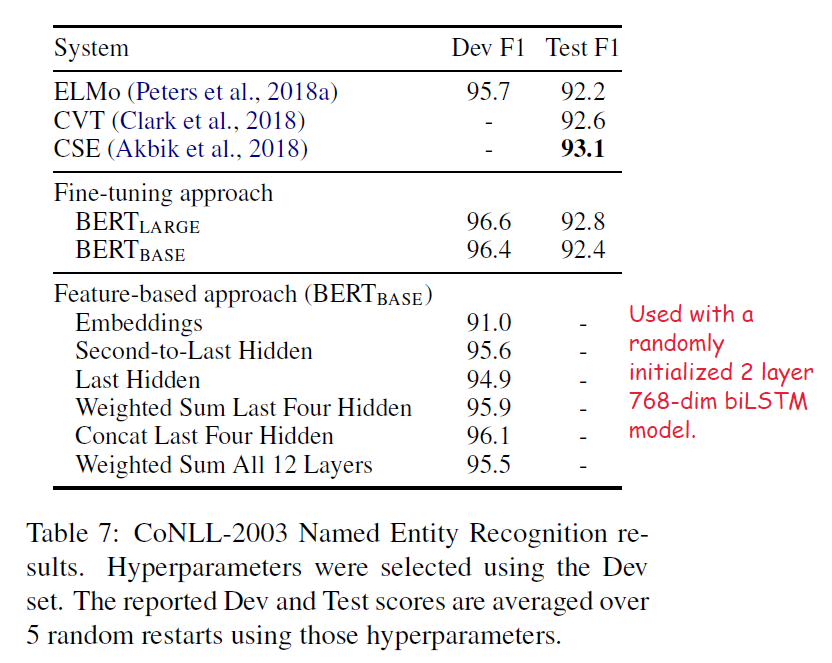
- The authors compare the feature-based approach for the BERT inference and the normal BERT for the NER task. In the inference part of the feature-based approach, the activations from one or more layers are taken without any fine-tuning of the BERT parameters for the NER task. These contextual embeddings are used as input to a randomly initialized two-layer 768-dimensional BiLSTM before the classification layer.
- Although this does not perform better than the fine-tuned approach, the best performing method used the concatenation of the last four hidden layers’ representation of the pre-trained Transformer as the token representation is only 0.3 F1 behind the fine-tuning approach. So, the authors conclude that BERT is effective for both fine-tuning and feature-based approaches.