Paper Summary #5 - XLNet: Generalized Autoregressive Pretraining for Language Understanding

Paper: XLNet: Generalized Autoregressive Pretraining for Language Understanding
Link: https://arxiv.org/pdf/1906.08237.pdf
Authors: Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le
Code: https://github.com/zihangdai/xlnet
I have also released an annotated version of the paper. You can find it here.
What?
The paper proposes XLNet, a generalized autoregressive pretraining method that enables learning bidirectional contexts over all permutations of the factorization order and overcomes the limitations of BERT due to the autoregressive formulation of XLNet. XLNet incorporates Transformer-XL as the underlying model. It outperforms BERT in 20 NLP tasks like question answering, natural language inference, sentiment analysis and document ranking.
Why?
The existing unsupervised representation learning approaches can be divided into two types - autoregressive language modeling and autoencoding approaches. The autoregressive methods like ELMo and GPT tried to estimate the probability distribution of a text corpus with an autoregressive model. They had a limitation in that they only captured the unidirectional context. BERT aimed to solve this problem by aiming to reconstruct the original data from the corrupted input. So BERT could capture the bidirectional context, but by converting this into a prediction problem, BERT assumed that the predicted tokens are independent of each other. However, that is not the case in natural language where long term dependency is prevalent. Moreover, the use of the [MASK] tokens also created a pretrain-finetune discrepancy as there are no [MASK] tokens available during finetuning.
XLNet tries to leverage the best of both worlds. The qualities of XLNet are -
- XLNet computes the maximum likelihood of a sequence w.r.t. all possible permutations of the factorization order. So when calculating the expectation, each position learns to capture the context from all positions, hence capturing bidirectional context.
- XLNet does not rely on data corruption as in BERT and hence does not suffer from the pretrain-finetune discrepancy.
- XLNet integrates the novelties from Transformer-XL like recurrence mechanism and relative encoding scheme (explained later as well). This improves the performance of tasks that utilise a longer text sequence.
How?
Autoregressive language modeling performs pretraining by maximizing the likelihood under the forward autoregressive factorization -
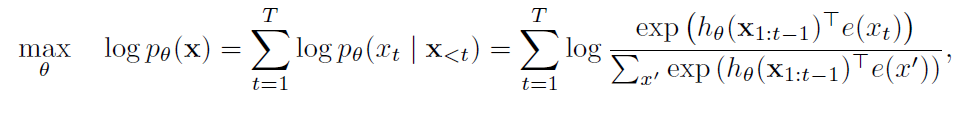
Here x is the given text sequence. hΘ(x1:t-1) is the context representation produced by the model and e(x) is the embedding of x.
Denoising autoencoding approach like BERT first constructs a corrupt version x(cap) by randomly masking a fraction (15%) of tokens of x to a special symbol [MASK]. The masked tokens are denoted by x(bar). So, the training objective in the case of BERT becomes -
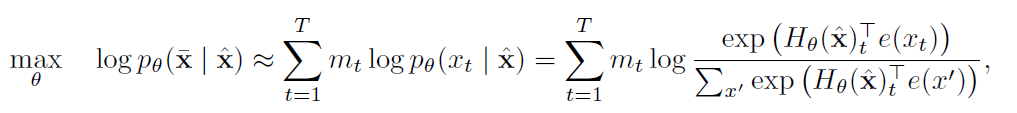
Here mt is 1 when xt is masked. Here HΘ is a Transformer that maps each token to a sequence of length T to hidden vectors [HΘ(x)1, HΘ(x)2, …, HΘ(x)T].
In BERT, the conditional probability is taken when the input is masked, denoted using mt. Hence denoting the independence assumption among the targets.
Objective: Permutation Language Modeling
Both autoregressive and autoencoding approaches have their benefits over each other. XLNet tries to bring both their advantages into the picture while avoiding their weaknesses.
XLNet proposes the use of permutation language modeling objective that looks like the general autoregressive language modeling approach but it allows the model to capture bidirectional context as well. Here, the training is performed for each valid autoregressive factorization order (permutations) of the sequence. The model parameters are shared across all the factorization orders, and hence the model learns to capture information from all positions on both sides.
The proposed permutation language modeling approach is -
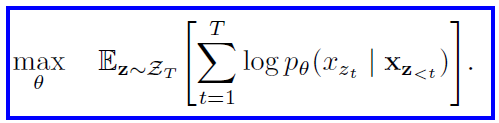
Here ZT is the set of all possible permutations of the length-T index sequence [1, 2, 3…, T]. zt and z<t denote the t-th element and the first t-1 elements of the permutation. So, basically the autoregressive formulation is applied for each factorization order z.
Since this is based on the autoregressive framework, the independence assumption of BERT is no longer present in this case and the pretrain-finetune discrepancy is also not present.
* One must note that here the objective does not permute the sequence order. The sequence order remains as it is and the positional encodings correspond to the original sequence itself. Here, the attention mask in Transformers is used to achieve the permutation of the factorization order. This is done because permuting the sequence itself can cause problems as during finetuning, the natural order will always be preserved. The authors do not want to include any other pretrain-finetune discrepancy.
Architecture: Two-Stream Self-Attention for Target-Aware Representations
Using the Transformer(-XL) directly with the permutation language modeling objective will not work. This is because, say we have two sequences, in which z<t sequence is same but the zt token is different. And in the current formulation using transformers(-XL) the z<t sequence determines zt but that would not be correct if we predict the same distribution for both the sequences while they have two different tokens as the target.
To solve this, a re-parameterization of the next-token distribution with the target-position (zt) is required.
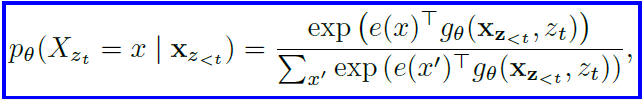
Here, gΘ(xz<t, z) is a new type of representation that takes in the zt as input as well.
Two-Stream Self-Attention
Now, there is a contradiction here. If we want to predict xzt, gΘ(xz<t, zt) should only use position zt and not xzt itself. Also, to predict the future tokens xzj with j > t, we need xzt to provide the full context information.
So, to resolve this, XLNet uses two hidden representations -
- Content representation hΘ(xz<=t) abbreviated as hzt, which is similar to the general Transformer hidden state. This encodes both the context and the token xzt.
- Query representation gΘ(xz<t, zt) , abbreviated as gzt, which only has access to the contextual information xz<t and the position zt but not the contents xzt.
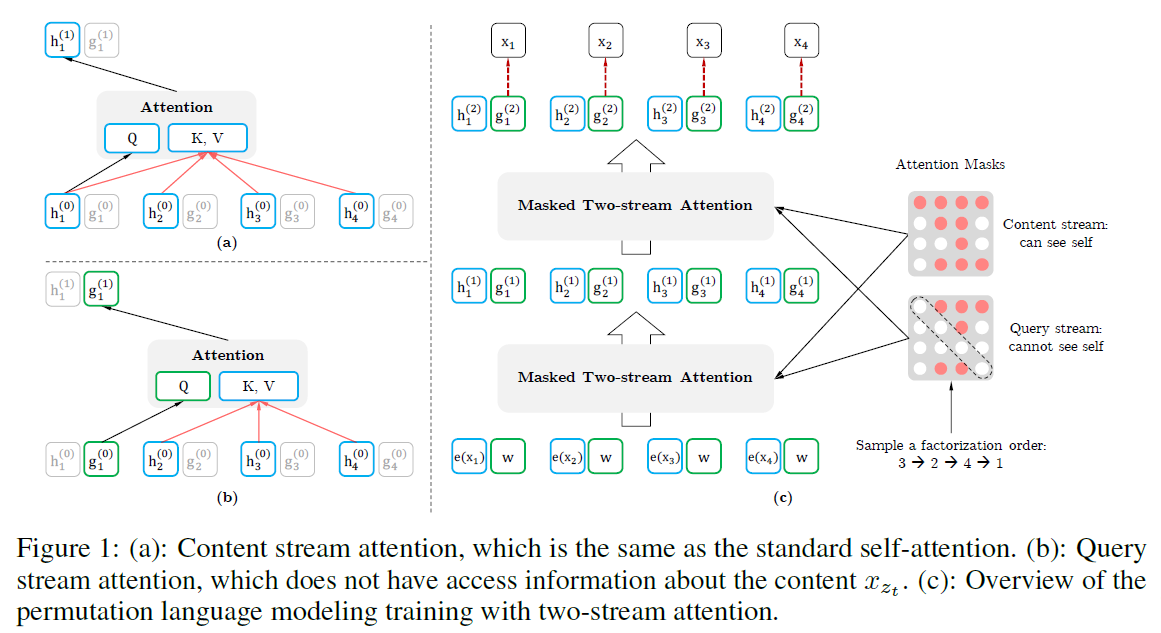
The above diagram shows the flow of the two streams. The two streams are updated with a set of shared parameters as follows -

The update rule of the content representations is exactly the same as the standard self-attention. During finetuning, the query stream can be dropped and the content stream can be used as a normal Transformer(-XL). And in the end, the last-layer query representation gzt is used to compute the likelihood.
Partial Prediction
For a given factorization order z, cutting point c is chosen which splits the sequence into two subsequences. z<=c is the non-target subsequence and z>c is the target sequence. The objective to maximize the log-likelihood of the target subsequence conditioned on the non-target subsequence is written as -
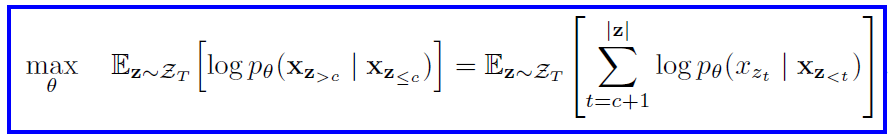
A hyperparameter K is chosen to determine what fraction of the sequence length will be the target sequence. This is done so that sufficient sequence length is present for the model to learn the context.
| Here again, XLNet differs from BERT. Let us consider an example [New, York, is, a city]. If both BERT and XLNet take two tokens [New, York] as the prediction task and so they have to maximize p(New York | is a city). Here BERT and XLNet get the following objectives - |
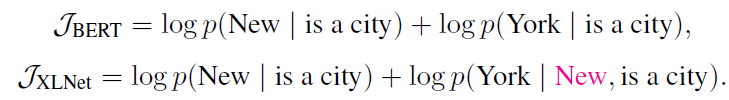
XLNet considers the dependency in the target subsequence as well i.e., how “York” depends on “New” as well. XLNet always learns more dependency pairs given the same target and contains “denser” effective training signals.
Ideas from Transformer-XL
Transformer-XL introduced the segment recurrence mechanism for caching and reuse of the previous segment knowledge. For a long sequence s, if we take two segments z(bar) and z which are permutations of the segment, then the obtained representations from the first segment h(bar)(m) for each layer m can be cached and reused for the next segment. This can be written as -
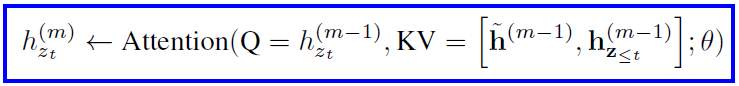
Also since the positional embeddings depend on the actual positions in the original sequence, the above attention update is independent of the previous segment once the hidden representations have been calculated. So the factorization order of the previous segment need not be known. Subsequently, the model learns to utilize the memory over all factorization orders of the last segment. The same is done for the query stream as well.
Modeling Multiple Segments
Like BERT, XLNet randomly samples two segments (either from the same context or not) and treats the concatenation of two segments as one sequence to perform permutation language modeling.
XLNET introduces Relative Segment Encodings. Unlike BERT which had absolute segment embeddings that were added to the word embedding at each position, here, rather than giving the entire segment an encoding, relative encoding is used between positions to denote whether they belong to the same segment or not. The segment encoding of the positions is used to compute the attention weight. So, when position i attends to j, the segment encoding sij is used to compute an attention weight aij = (qi + b)Tsij , where qi is the query vector as in a standard attention operation and b is a learnable head-specific bias vector.
Relative segment encodings help because -
- Inductive bias of the relative encodings improves the generalization.
- Opens up the possibility of finetuning on tasks that have more than two input segments, which is not possible when using absolute segment encodings.
Results
Two datasets were the same as the ones BERT used i.e., BooksCorpus and English Wikipedia. Furthermore, Giga5, ClueWeb 2012-B and CommonCrawl datasets were also used. SentencePiece tokenization was used.
XLNet had the same architecture hyperparameters as BERT-Base and XLNet-Large had the same hyperparameters as BERT-Large. this resulted in similar model size and hence a fair comparison.
XLNet was trained on 512 TPU v3 chips for 500K steps with an Adam weight decay optimizer, linear learning rate decay, and a batch size of 8192, which took about 5.5 days. And even after using so much compute and time, the model still underfitted on the data at the end of the training.
Since the recurrence mechanism is introduced, XLNet uses a bidirectional data input pipeline where each of the forward and backward directions takes half of the batch size. The idea of span-based prediction, where first, a sample length L from [1, …, 5] is chosen and then a consecutive span of L tokens is randomly selected as prediction targets within a context of (KL) tokens.
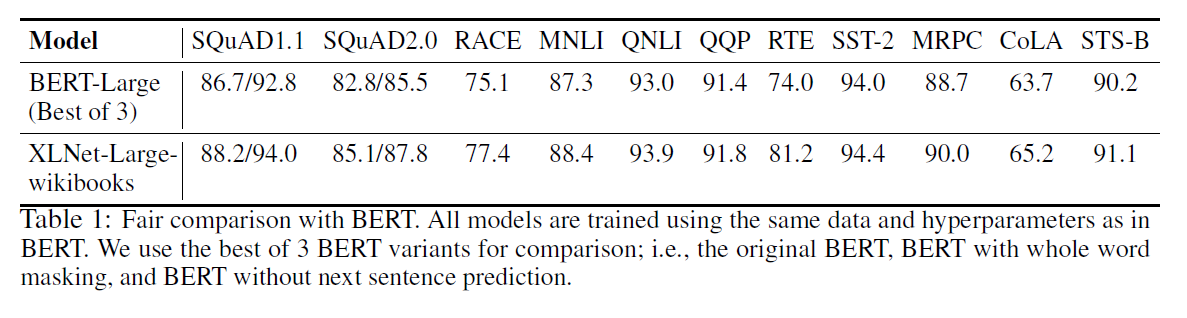
As seen above, trained on the same data with an almost identical training recipe, XLNet outperforms BERT by a sizable margin on all the considered datasets.
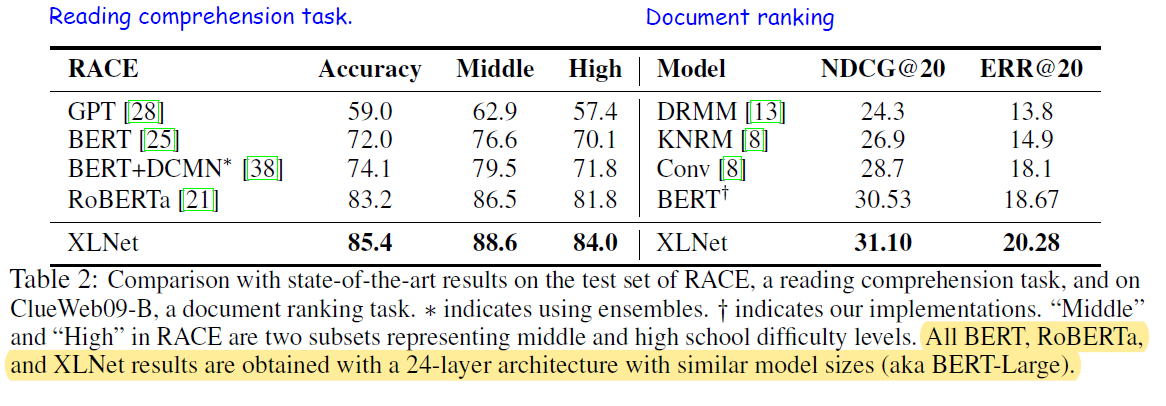
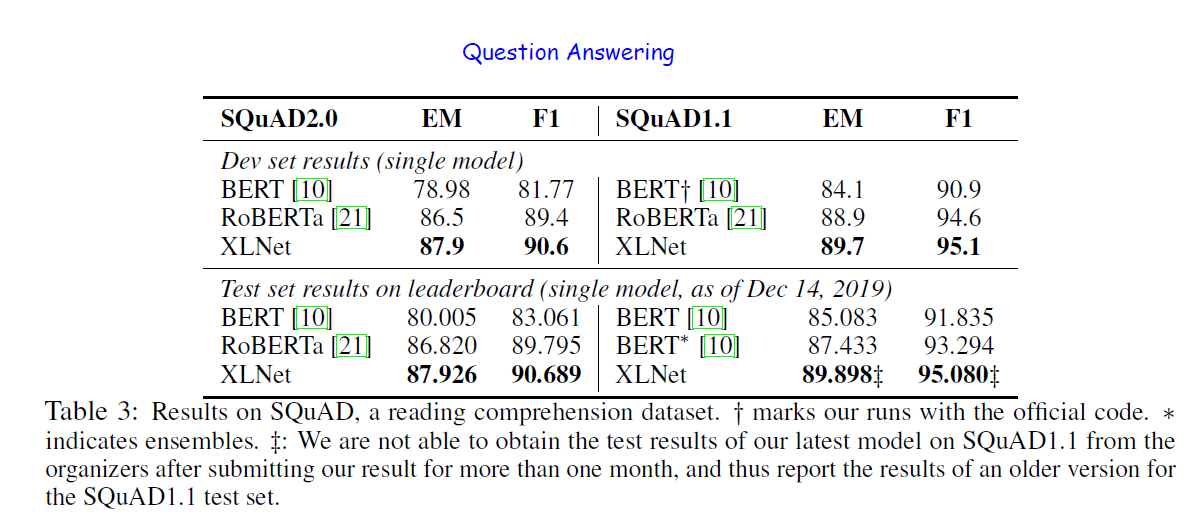
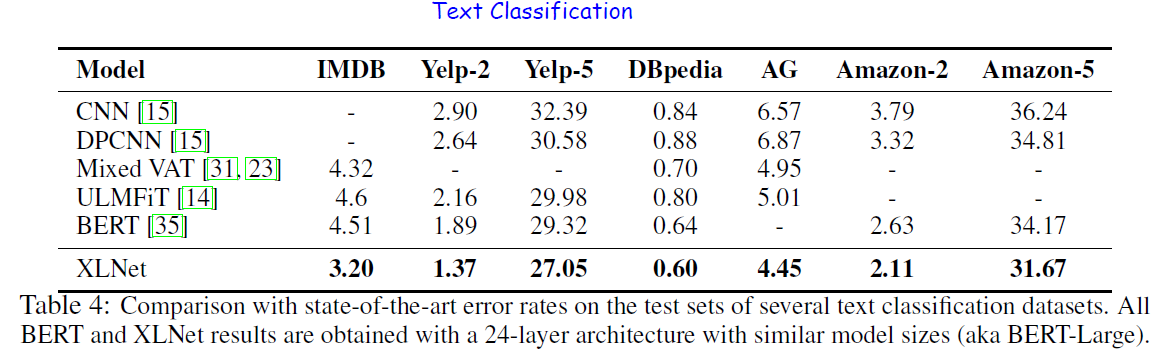
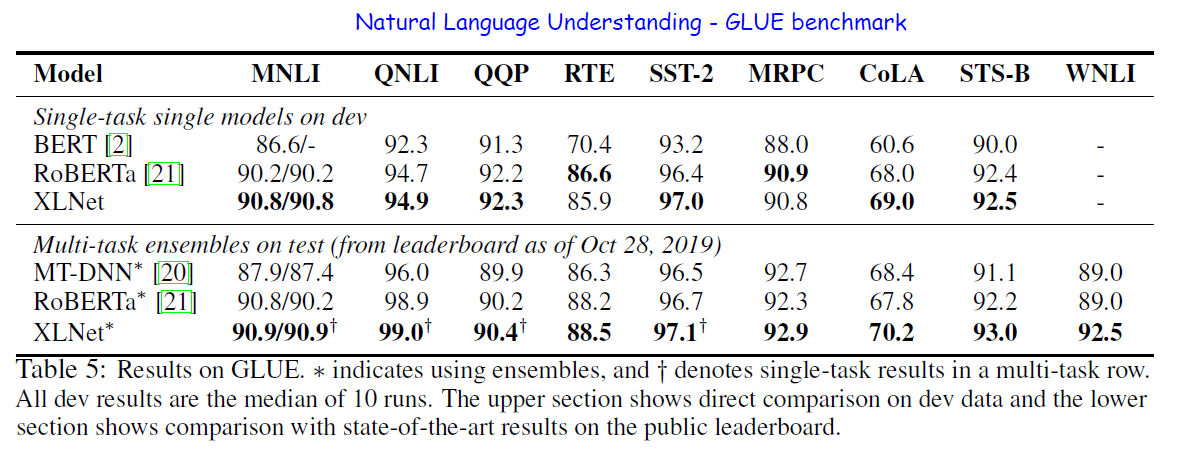
- For explicit reasoning tasks like SQuAD and RACE that involve longer context, the performance gain of XLNet is larger. The use of Transformer-XL could be the main reason behind this.
- For classification tasks that already have abundant supervised examples such as MNLI (>390K), Yelp (>560K) and Amazon (>3M), XLNet still lead to substantial gains.
Ablation study was also performed to understand the importance and effect of introducing each component. The points of the study were -
- The effectiveness of the permutation language modeling objective alone, especially compared to the denoising auto-encoding objective used by BERT.
- The importance of using Transformer-XL as the backbone neural architecture. For this, a DAE + Transformer-XL model was used.
- The necessity of some implementation details including span-based prediction, the bidirectional input pipeline, and next-sentence prediction.
For a fair comparison, all models were based on a 12-layer architecture with the same model hyper-parameters as BERT-Base and were trained on only Wikipedia and the BooksCorpus. All results reported are the median of 5 runs.
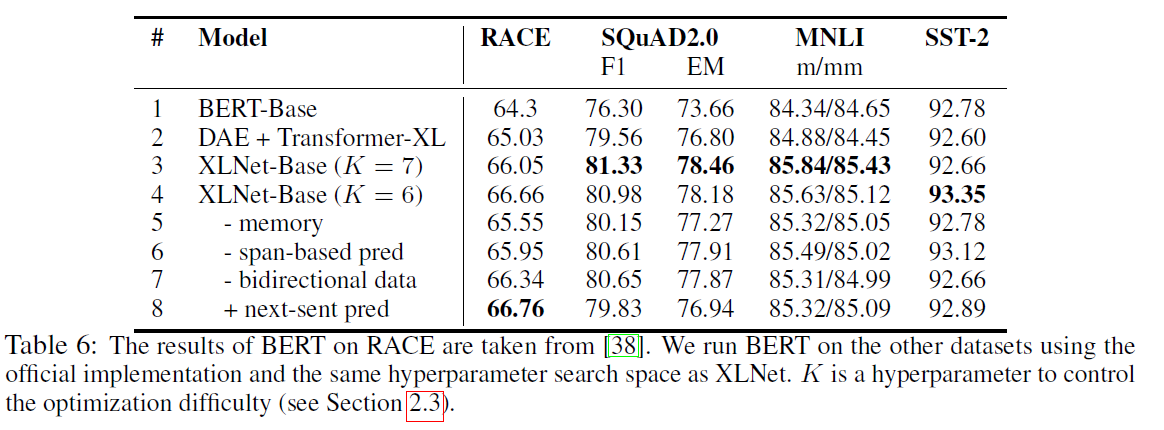
From the table -
- Transformer-XL and the permutation LM (the basis of XLNet) are big factors in the superior performance of XLNet over BERT.
- On removing the memory caching mechanism, the performance drops especially for RACE where long context understanding is needed.
- Span-based prediction and bidirectional input pipeline also help in the performance of XLNet.
- The next-sentence prediction objective does not lead to an improvement. Hence the next-sentence prediction objective is excluded from XLNet.
This is all for now!