Paper Summary #6 - Language Models are Unsupervised Multitask Learners

Paper: Language Models are Unsupervised Multitask Learners
Link: https://bit.ly/3vgaVJc
Authors: Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever
Code: https://github.com/openai/gpt-2
I also made an annotated version of the paper which you can find here
What?
The paper demonstrates that language models begin to learn NLP tasks like question answering, machine translation, reading comprehension and summarization without any explicit supervision. The results shown are obtained after training the model on a new dataset of millions of web pages called WebText. GPT-2 is a 1.5 billion parameter model that achieves SOTA on 7 out of 8 LM tasks in a zero-shot setting. The paper proves that it is possible to build NLP systems that learn to perform tasks from the naturally occurring demonstrations of the tasks in text.
Why?
The main motivation arises from the fact that current systems are narrow experts rather than competent generalists. There should be a shift to more general systems which can perform many tasks without the need to manually create and label a training dataset for each one. There have been examples of erratic behaviour of captioning models, reading comprehension systems and image classifiers due to the large variety of possible inputs which can’t be modeled using supervised approaches. There is a lack of generalization in current systems.
Additionally, multitask NLP systems are still in a very early stage mostly due to the fact that it would require a large amount of very specific labeled data for the model to learn from. Although some models use a combination of unsupervised pretraining followed by supervised fine-tuning. GPT-2 wants to do away with any supervised training and show how language models perform in a zero-shot setting on a wide range of tasks.
How?
Language modeling is usually framed as a unsupervised distribution estimation. It is modeled as a joint probability over the symbols. Due to the sequential order of natural text, this can be written as a product of the conditional probabilities.
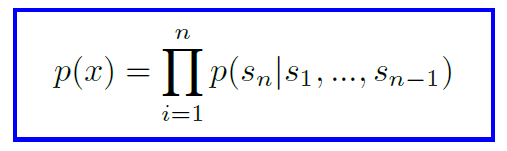
Instead of a simple conditional probability distribution for a single task p(output|input). To make a system that can perform multiple tasks, the distribution should be conditioned on the task as well i.e., p(output|input, task). This is usually implemented at the architecture level for example, by using task-specific encoders and decoders. It can also be performed by the language directly. A translation task can be represented as \(\texttt{(translate to french, english text, french text)}\). A reading comprehension can be written as \(\texttt{(answer the question, document, question, answer)}\).
In principle, language modeling will be able to learn these tasks without any supervision of which symbols are to be predicted. Since the global minimum of the unsupervised objective is also the global minimum of the supervised objective (which is based on a subset of the sequence), hence the model can focus only on optimizing for the unsupervised objective. For this, very large models are required, however the learning is slower as compared to the explicitly supervised approaches.
The authors believe that a large enough language model will begin to learn the tasks embedded within the natural language itself and won’t require any additional supervision. For example, given enough text, the model will learn what question answering is, without having to train on question-answering data specifically.
Dataset
A new dataset (self-curated), WebText was used by the authors to train the model. The dataset contained page contents of all the scraped outbound links from Reddit, from posts that received at least 3 karma. They performed HTML cleaning, de-duplication. Also, Wikipedia pages were removed as the test datasets of many of the downstream tasks had information from Wikipedia.
Input Representation
BytePair encoding, which effectively interpolates between word level inputs for frequent symbol sequences and character level inputs for infrequent symbol sequences was used for tokenizing the corpus. The encoding in the paper was not performed on bytes but Unicode points. This increases the base vocabulary from 256 (in byte mode) to 130,000 (with Unicode).
The BPE encoding allowed the authors to combine the benefits of word-level LMs with the generality of byte-level approaches. Also, since now the model can assign a probability to any Unicode string, so the LM will be able to be evaluated on any dataset regardless of the pre-processing, tokenization or vocabulary size.
Model
The model is a Transformer decoder architecture, very similar to GPT-1. You can find details here. Some modifications include
- Moving the layer norm to the input of each sub-block and adding an additional layer norm after the final self-attention block.
- A modified initialization which accounts for the accumulation on the residual path with model depth is also used.
- The weights of the residual layers are scaled by 1/sqrt(N) where N is the number of residual layers.
- The vocabulary is expanded to 50,257.
- The context size from 512 to 1024 tokens and a larger batch size of 512 is used.
Results
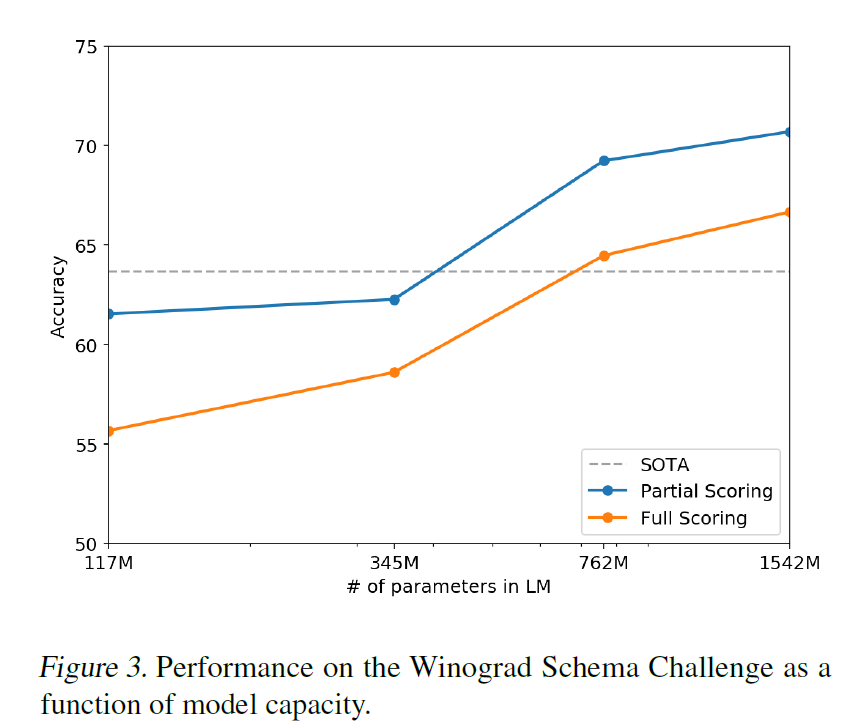
Language Modeling
This is the primary task the model was trained for. In this category, the model is evaluated on its perplexity score. Some invertible de-tokenizers had to be used on the test set as not all types of text are seen during training for example, standardized text, having tokenization artifacts like shuffled sentences and <UNK> string. A de-tokenizer that removes those artifacts improves the score by 2.5 - 5 perplexity points.
- Large improvements were seen on small datasets like Penn Treebank and WikiText-2.
- Large improvements were also seen on LAMBADA and Children’s Book Test where long-term dependency had to be measured.
- It failed to perform better than existing approaches for the One Billion Word Benchmark, probably because of it being the largest dataset and having the most destructive pre-processing - the sentence level shuffling which removes all range structure. this makes it difficult for GPT-2 to perform well on it.
Children’s Book Test (CBT)
- CBT task was to predict which of 10 possible choices for an omitted word is correct.
- Data overlap analysis showed one of the CBT test set books, The Jungle Book by Rudyard Kipling, is in WebText, so the authors report results on the validation set which has no significant overlap.
- GPT-2 achieved SOTA results on both prediction of common nouns (CBT-CN) and the prediction of named entities (CBT-NE).
LAMBADA
- In LAMBADA, the task is to predict the final word of sentences which require at least 50 tokens of context for a human to successfully predict.
- GPT-2 improved the perplexity from 99.8 (existing SOTA) to 8.6 and the accuracy from 19% to 52.66%.
- Choosing a stopping filter was difficult as many times GPT-2 predicted valid continuations of the sentence but not valid final words. A stop-word filter for this helped improve the accuracy a bit.
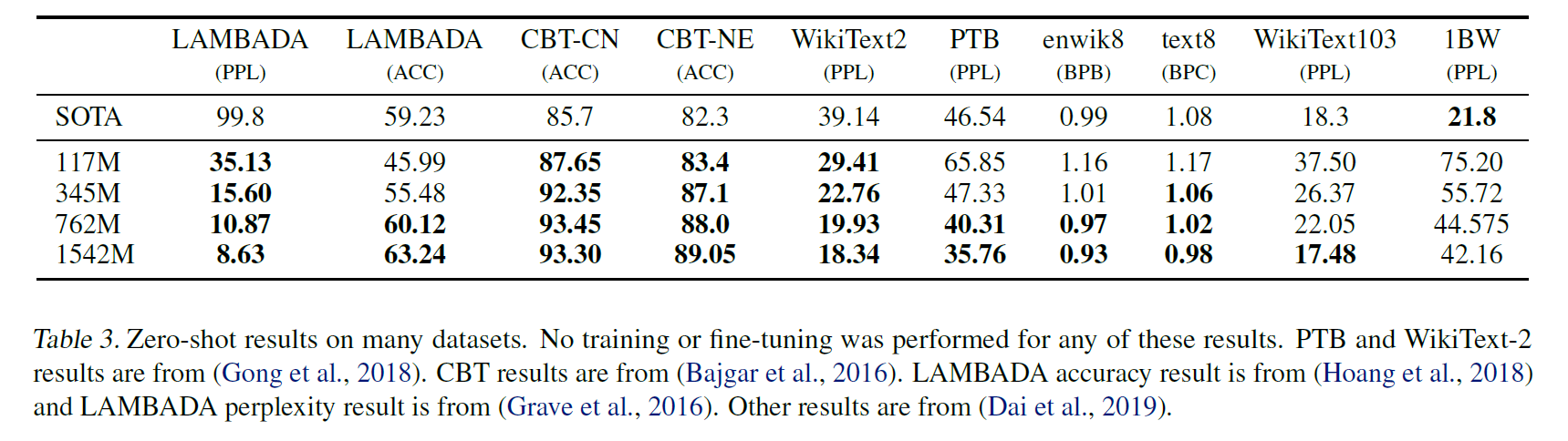
Winograd Schema Challenge
- The Winograd Schema challenge aims to measure the capability of a system to perform commonsense reasoning by measuring its ability to resolve ambiguities in the text.
- GPT-2 improves the state of the art accuracy by 7%, achieving 70.70%.
Reading Comprehension
- The CoQA dataset consists of documents from different domains with natural dialogues in the form of questions and answers. The task tests the reading comprehension capabilities and also the ability to answer questions based on conversation history.
- GPT-2 was evaluated on this task by conditioning on the document, the conversation history and the final token.
- This matched or exceeded the results from 3 of 4 baselines. Also, these models were trained on the 127,000+ question-answer pairs of the training data, which GPT-2 didn’t look at.
- GPT-2 didn’t perform as well as the BERT SOTA but the score is still impressive since it is a completely unsupervised model.
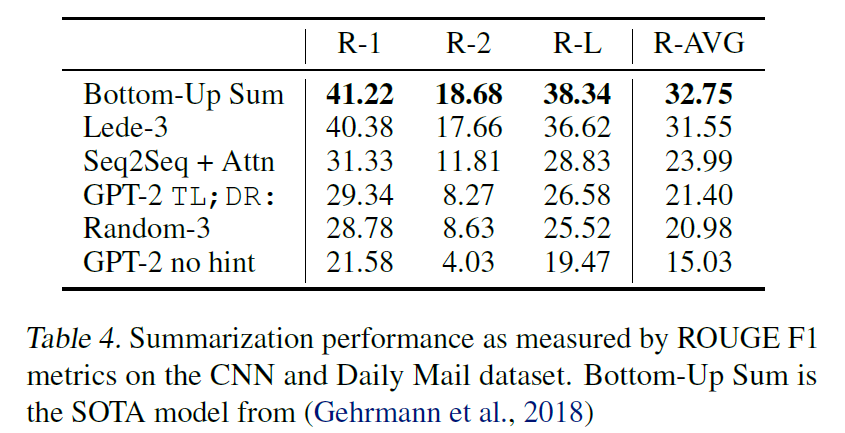
Summarization
- GPT-2 didn’t perform well on the summarization task on the CNN and Daily Mail dataset.
- It just barely outperforms selecting 3 random sentences from the article.
- Removing the hint reduced the score by 6.4 points indicating that task-specific behaviour was being invoked by natural language.
Translation
- The model was conditioned in the following manner - english sentence = french sentence and then after the prompt of english sentence = , the greedy decoding and the first generated sentence was used as the translation.
- However, the performance of the model was very poor, even worse than a word-by-word substitution of the words with their translation.
- However, the French to English task was a bit better, surpassing some unsupervised methods but very far from the best unsupervised method.
- The result is interesting as almost all non-English text was removed from WebText during preprocessing. And the best unsupervised method used 500x more French data.
Question Answering
- The context of the language model is seeded with example question-answer pairs which helps the model infer the short answer style of the dataset.
- However the performance is very poor and the model only answers 4.1% of the questions correctly.
- It was seen that the smaller models could answer around 1% of the questions, indicating that a larger model size helped.
- GPT-2 has an accuracy of 63.1% on the 1% of questions it is most confident in.
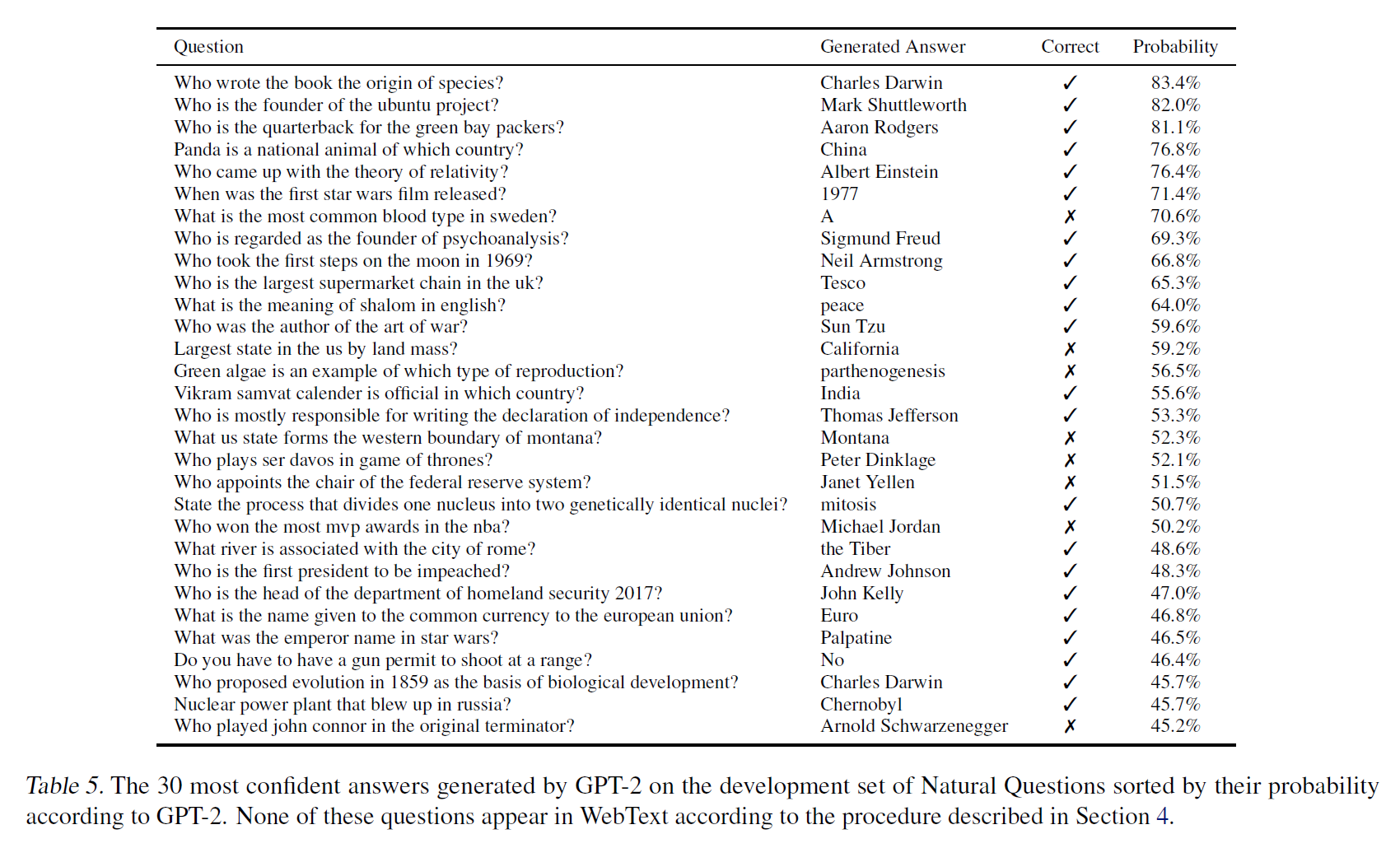
Generalization vs Memorization
- In general, it was seen that all the major datasets have some amount of overlap between the train and the test datasets.
- Even CIFAR-10 has a 3.3% overlap of train and test images.
- To test this, Bloom filters containing 8-grams of WebText training set tokens were created.
- These Bloom filters helped to calculate, given a dataset, the percentage of 8-grams from that dataset that are also found in the WebText training set.
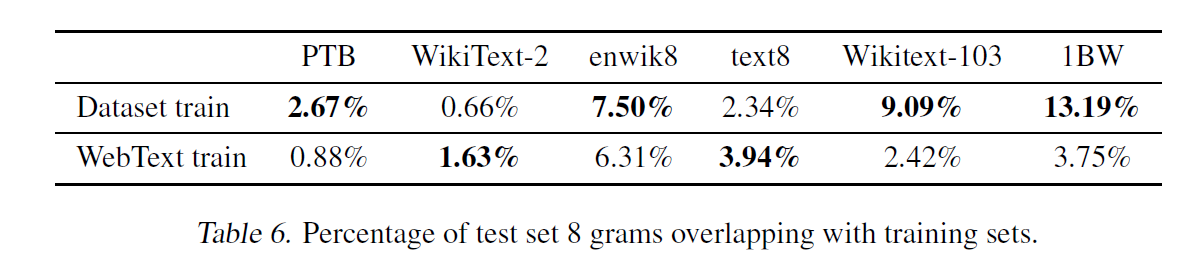
- The overlap between the datasets’ train and test set was also very high in some.
- And on analysis, it was seen that removing these overlaps from the train set, resulted in a slight drop in performance across tasks.
- The authors suggest fuzzy string matching or n-gram overlap based de-duplication as important sanity checks when splitting NLP datasets to create the train and test set.
- The performance on both the training and test sets of WebText are similar and improve together as model size is increased
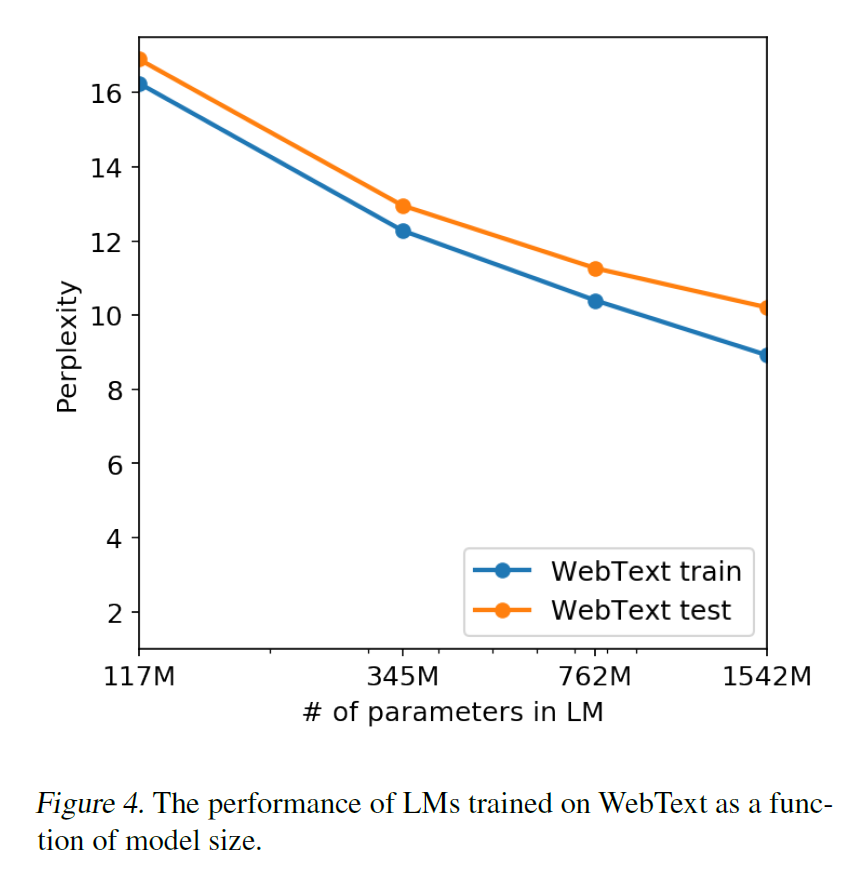
The authors conclude by saying that since finetuning had helped GPT, the same could be tried for GPT-2 as well for benchmarks such as decaNLP and GLUE. Also, it may be helpful because as BERT pointed out, the inefficiency of unidirectional representations can not absolutely be eliminated by more training data and model size, as could be seen in tasks like summarization, translation and question answering.
I have also released an annotated version of the paper. If you are interested, you can find it here.
This is all for now!