PPML Series #1 - An introduction to Federated Learning
Motivation
Privacy-preserving Machine Learning had always been exciting for me. Since my B.Tech. thesis involving PPML (SMPC + Computer Vision), I didn’t get a chance to work on it after that. So, after about 2 years, I have started to read about it again, and sharing it with the community.
Federated Learning is a domain that I had somewhat eluded during my thesis. I had some idea about the topic but didn’t get into it much. So, I decided to start with FL this time. There is a ton of literature out there and is a field of active interest right now.
Introduction
Modern mobile devices have abundance of data, majorly textual data, image data. Applying machine learning to these can definitely help improve user experience. For example - your mobile keyboard uses language models can improve speech recognition and text entry, your photos apps (Google Photos, say) has image models that can automatically select good photos.
However, we have two problems here. Firstly, if we consider millions of devices, then this data is large in quantity. Secondly, this dataset may have personal pictures, textual information written by the device owners,among other things. Hence, this data is privacy sensitive in most cases. This creates problems to store this data in a database. It can be both infeasible as well as cause privacy violations.
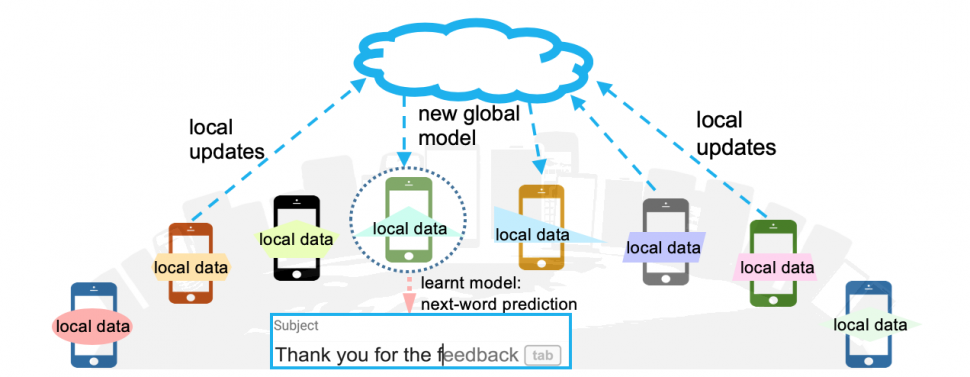
Federated Learning is a decentralised machine learning approach which allows to leave the training data on the individual devices and learns a shared model by aggregating locally computed gradient updates. Federated Learning can significantly reduce privacy and security risks by limiting the attack surface to only the device, rather than the device and the cloud. Obviously, some level of trust on the server coordinating the training is still required.
Why FL?
Federated Learning usually helps in three contexts -
- Training on real-world data from mobile devices provides advantage over training on proxy data stored in data centres. The distributions from which these examples are drawn are likely to differ substantially from easily available proxy datasets: the use of language in chat and text messages is generally much different than standard language corpora, e.g., chat messages are not like Wikipedia articles. Images taken through the camera are also not like Flickr images.
- The data is privacy sensitive or large in size (compared to the size of the model), so it is preferable not to log it to the data centre purely for the purpose of model training.
- Sometimes, labels for tasks can naturally be obtained from user interaction. Entered text is self-labeled for learning a language model, and photo labels can be defined by natural user interaction with their photo app (which photos are deleted, shared, or viewed).
Applications of FL could include image classification, predicting which images will be viewed multiple times in the future, language modelling, next word/phrase prediction.
How does FL provide privacy (up to a certain extent)?
Handling even anonymized data can lead to privacy concerns. What better way than to use the data itself to train the models but at the same time, not risk its privacy. In contrast, the information transmitted for federated learning is the minimal update necessary to improve a particular model. They will generally contain much less information about the raw data. Further, the source of the updates is not needed by the aggregation algorithm, so updates can be transmitted without identifying meta-data over a mix network such as Tor or trusted third-parties.
Federated Optimization
The optimization problem implicit in federated learning as federated optimization, drawing a connection (and contrast) to distributed optimization.
How is FL different from any other distributed optimization problem?
In federated optimization, there are a few key properties that differentiate from a typical distributed optimization problem.
- Non-IID - Training data will vary from user to user and will not have properties that are similar to the population.
- Unbalanced - Some users use a device more and generate more data, some less.
- Massively distributed - Number of users are much more than the average number of examples per client.
- Limited communication - Devices are frequently offline and are on slow or expensive connections.
How to perform Federated Optimization?
In this blog post, I won’t go into the mathematical details regarding the optimization techniques used in Federated Learning. However, we will be discussing the high-level overview of how training is performed. The steps are as follows -
- There is a fixed set of K clients, each with a fixed local dataset.
- At the beginning of each round, a random fraction C of clients is selected, and the server sends the current global algorithm state to each of these clients (e.g., the current model parameters).
- Only a fraction of clients is selected for efficiency, as experiments show diminishing returns for adding more clients beyond a certain point.
- Each selected client then performs local computation based on the global state and its local dataset, and sends an update to the server.
- The server then applies these updates to its global state, and the process repeats.
Challenges
In general, for ML tasks, and in data centres, the costs of compute is what is the most important - GPUs are used to lower the computation cost. In Federated Learning, the communication costs somewhat dominate.
But what do communication costs mean here?
- Upload bandwidths in mobiles (globally) is limited to 1 MB/s or less.
- Clients volunteer only if the charged, plugged-in and on free/unmetered WiFi connections.
- Each client participates in only a small number of rounds per day.
In Federated Learning, computation is not much of an issue because the dataset size on each device will be relatively much less and modern smartphones now have processors fast enough to do those computations locally. So, the goal becomes to use additional computation in order to decrease the number of rounds of communication needed to train a model.
So, the goal becomes to use additional computation in order to lower the number of rounds of communication needed to train the model.
There are two approaches which can be adopted for this -
- Increased parallelism - More clients are used which work independently between each communication round.
- Increased computation on each client - Rather than performing a simple computation like gradient calculation, each client performs a more complex calculation between each communication round.
In practice, major speedups are obtained when computation on each client is improved, once a minimum level of parallelism over clients is achieved.
I wrote a Twitter thread on this topic as well - do give it a like/follow me if you liked the article.
There was a 'Moved Permanently' error fetching URL: 'https://twitter.com/shreyansh_26/status/1462262151209381888'
This is all for now. Thanks for reading!
In my next post, I’ll share a mathematical explanation as to how optimization (learning) is done in a Federated Learning setting. I will also explain some experimental results that have been published.