These are just short notes / excerpts from the technical paper for quick lookup. Actual implementational details are anyways missing in the technical paper.
Gemini 1.5 Pro is a sparse MoE Transformer-based model (seems like a trend these days, after GPT-4’s rumors and Mixtral).
It supports upto 10M context multimodal context length which is about a day of 22 hours of audio recordings, more than ten times the entirety of the 1440 page book “War and Peace”, the entire Flax codebase (41,070 lines of code), or three hours of video at 1 frame-per-second.
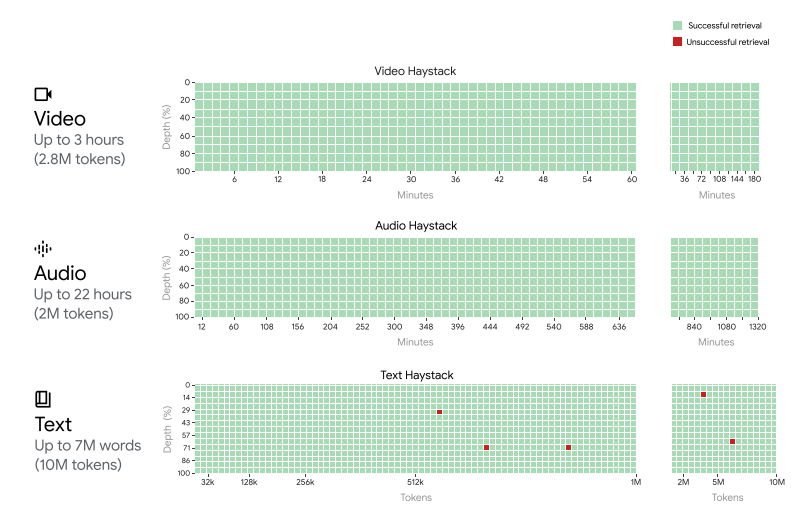
Near-perfect retrieval across complete context length. In all modalities, i.e., text, video and audio, it achieves 100% accurate needle-in-a-haystack recall for 530k tokens, 99.7% accurate recall for 1M tokens and 99.2% for 10M contexts.
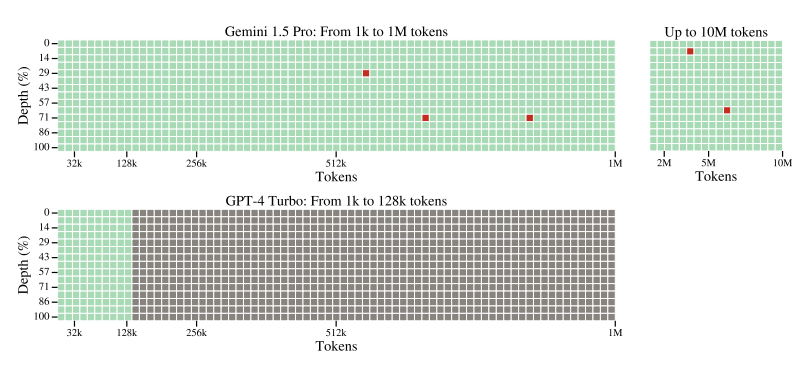
Text Haystack. This figure compares Gemini 1.5 Pro with GPT-4 Turbo for the text needle-in-a-haystack task. Green cells indicate the model successfully retrieved the secret number, gray cells indicate API errors, and red cells indicate that the model response did not contain the secret number. The top row shows results for Gemini 1.5 Pro, from 1k to 1M tokens (top left), and from 1M to 10M tokens (top right). The bottom row shows results on GPT-4 Turbo up to the maximum supported context length of 128k tokens. The results are color-coded to indicate: green for successful retrievals and red for unsuccessful ones.
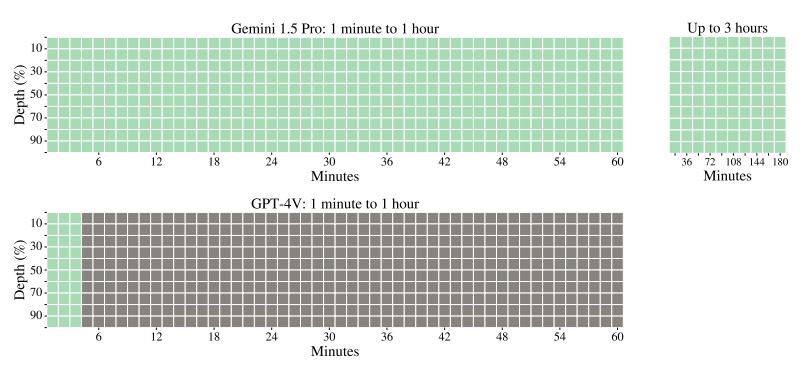
Video Haystack. This figure compares Gemini 1.5 Pro with GPT-4V for the video needle-in-a-haystack task, where the models are given video clips of different lengths up to three hours of video and are asked to retrieve a secret word embedded as text at different points within the clip. All video clips are sampled at one frame-per-second (1 fps). The first pair of 10 × 50 haystack plots on the left compare Gemini 1.5 Pro with GPT-4V on the first hour of the documentary. The x-axis represents the video duration which ranges from 1.2 minutes to 1 hour, and the y-axis represents the depth, namely the relative offset of the needle (e.g., the top left cell represents providing the model with the first 1.2 minutes and randomly sampling a frame in the first ten percent of that trimmed video where the needle is inserted). A green cell indicates that the model successfully retrieved the needle, whereas a gray cell indicates an API error. Whereas the GPT-4V API supports video lengths only up to around the first 3 minutes of the full hour, Gemini 1.5 Pro successfully retrieves the secret word inserted at all depth percentages up to an hour of video, as shown by the all-green plot. Finally, the 10 × 10 grid on the right shows Gemini 1.5 Pro’s perfect retrieval capabilities across three full hours of video, constructed by concatenating two copies of the documentary back-to-back.
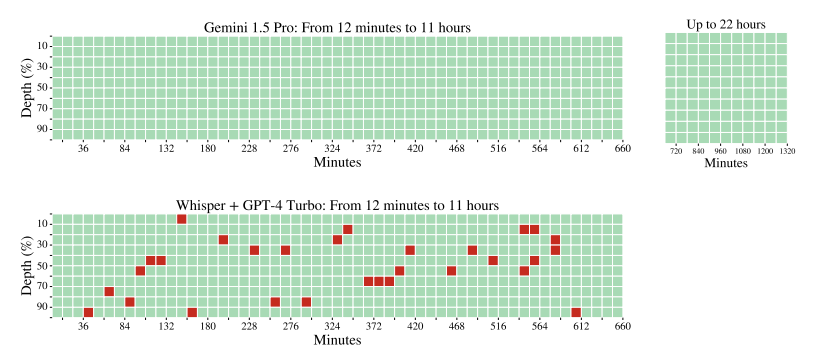
Audio Haystack. This figure presents the audio version of the needle-in-a-haystack experiment comparing Gemini 1.5 Pro and a combination of Whisper and GPT-4 Turbo. In this setting, the needle is a short segment of audio that is inserted within a very large audio segment (of up to 22 hours) containing concatenated audio clips. The task is to retrieve the 'secret keyword' which is revealed in the needle. Red indicates that the model did not identify the keyword, whereas green indicates that the model identified the keyword correctly
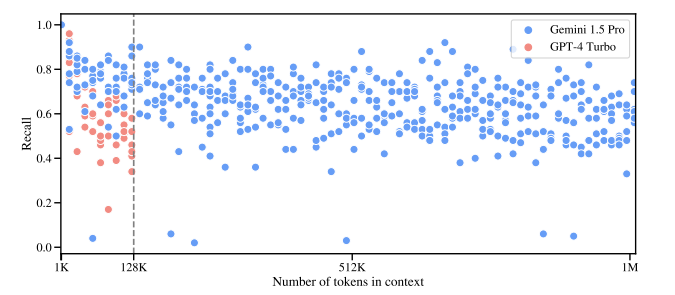
However, with about 100 needles (with the model requiring to retrieve them all), the performance drops to 70% recall up to 128K tokens, and >60% recall up to 1M tokens. GPT-4 is 50% recall at 128k tokens (its maximum context).
Gemini 1.5 Pro beats RAG-based systems for all modalities. Although this may not be cost efficient right now unless there are multiple queries and the long context can be prefix-cached.
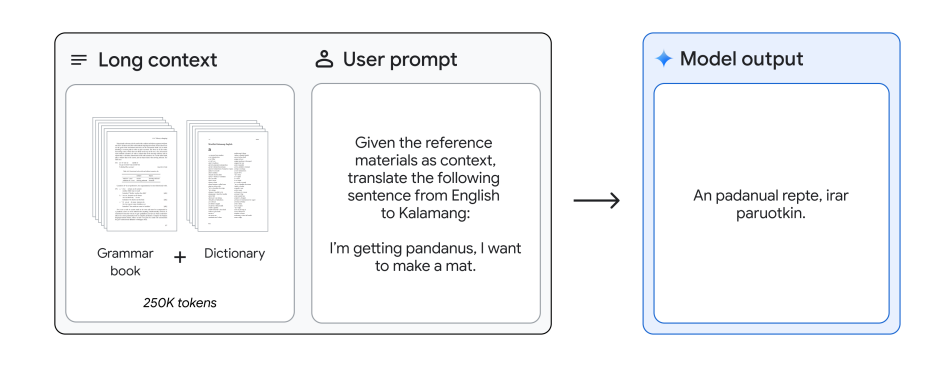
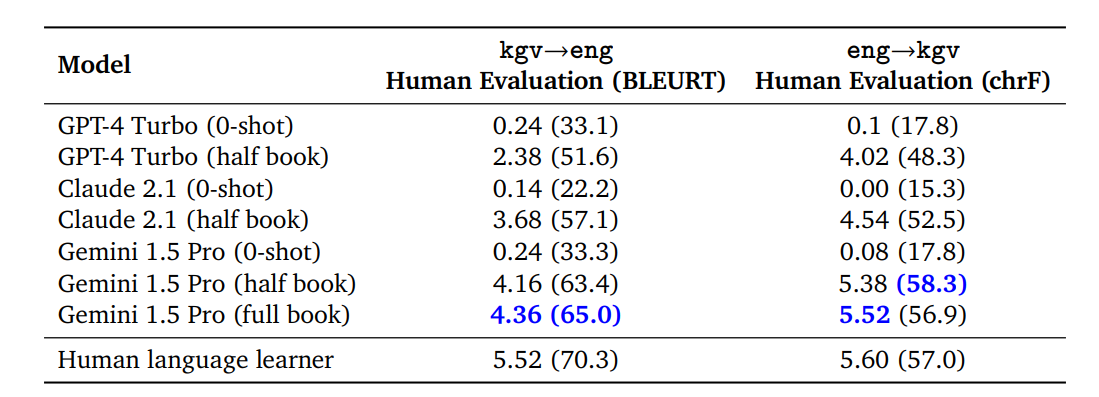
Excellent use of context for learning new skills. It was able to learn to translate from/to English to/from Kalamang, an extremely low-resource language (spoken by less than 200 people in the world), with just a single set of linguistic documentation, a dictionary, and ≈ 400 parallel sentences. That’s it!
Given a reference grammar book and a bilingual wordlist (dictionary), Gemini 1.5 Pro is able to translate from English to Kalamang with similar quality to a human who learned from the same materials.
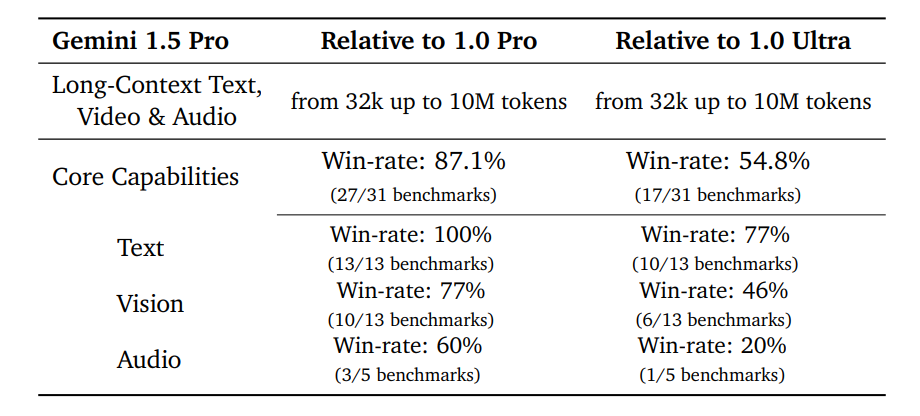
Gemini 1.5 Pro is exceeds Gemini 1.0 Ultra on text. However the latter is still better on vision and audio tasks, but the compute-efficiency and speed of shipping does suggest some ideas of distillation coming into the picture.
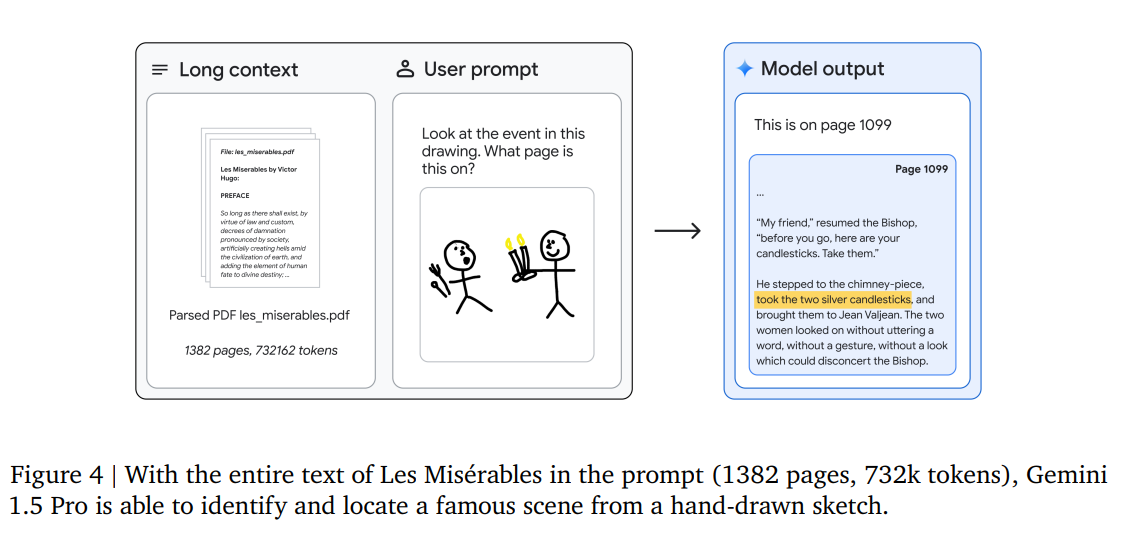
Figures 4 and 5 in the Technical report are super cool. In Figure 4, Gemini 1.5 is able to extract the exact scene with the page number from a textbook given a hand-drawn sketch as the prompt.
In Figure 5 they show that it is able to do the same in videos as well. The model returns a detailed description and timestamp of the scene.
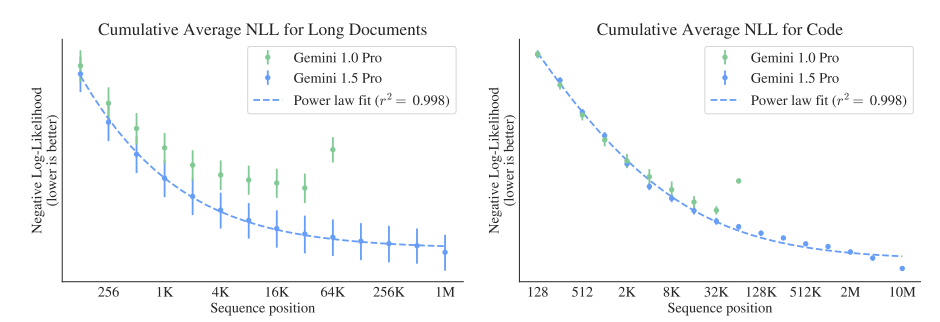
The cumulative average negative log-likelihood (NLL) as a function of token position in long documents follows a power-law quite accurately up to 1M tokens for long-documents and about 2M tokens for code but deviates at the 10M scale.