Notes from GTC'25: CUDA Techniques to Maximize Memory Bandwidth and Hide Latency - Part 1

You can watch the talk here - link
The talk had two major sections - maximizing memory throughput, and memory models and hiding latency. For clarity of thought and understanding, I will split my notes into two parts.
Refer to part 2 of the notes here.
Maximizing Memory Throughput
As GPU generations are progressing -
- Bandwidth is increasing rapidly
- # SMs is increasing slowly
This implies, more bandwidth per SM is available to saturate.
Little’s Law - The mean number if units in a system is equal to the (mean arrival rate) * (mean residency time)
Little’s Law for GPU memory - bytes-in-flight = bandwidth * mean latency * Bandwidth and Mean latency are determined by hardware. Bytes-in-flight can be controlled in software. * More bytes-in-flight are required to saturate DRAM bandwidth increases with every generation. Mainly due to bandwidth increase. It went 2x from Hopper to Blackwell.
bytes-in-flight per SM required to saturate bandwidth -
- Hopper - \(> 32\) KiB
- Blackwell - \(> 40\) KiB
How to increase Bytes-in-Flight?
- Instruction Level Parallelism (ILP) - More independent memory operations within a thread
- Data Level Parallelism (DLP) - Vectorized memory operations within a thread
- Asynchronous Data Copies
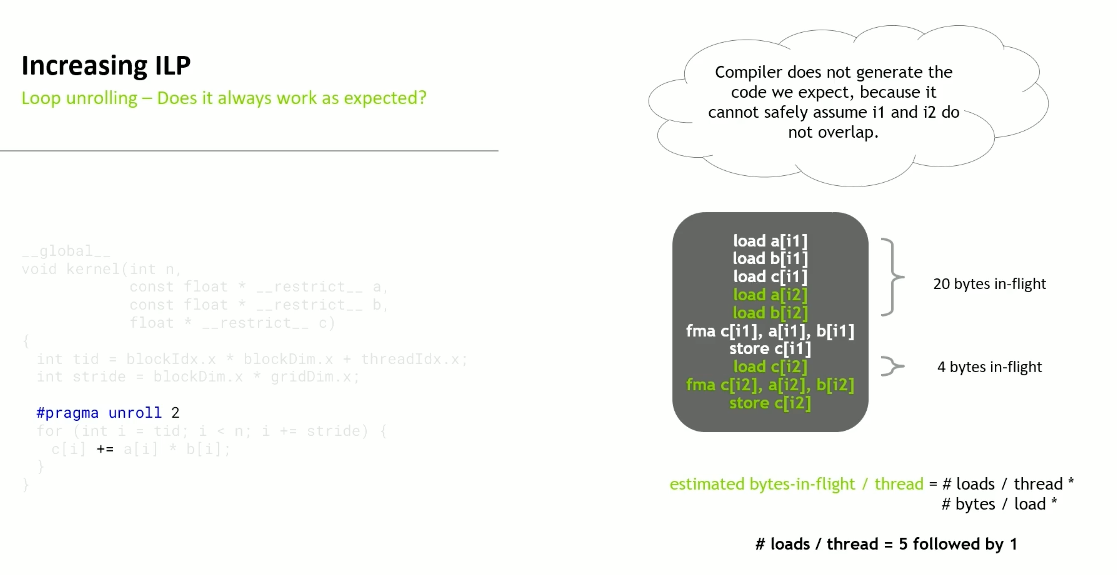
Increasing ILP
Loop Unrolling
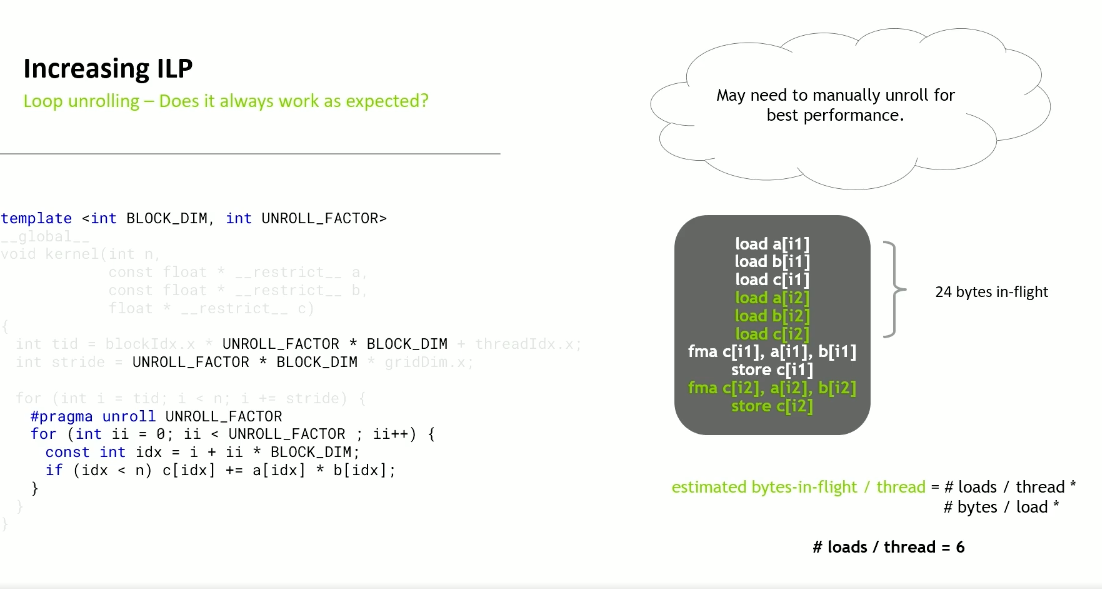
Sometimes manual unrolling may be needed
Increasing DLP
Using vectorized loads
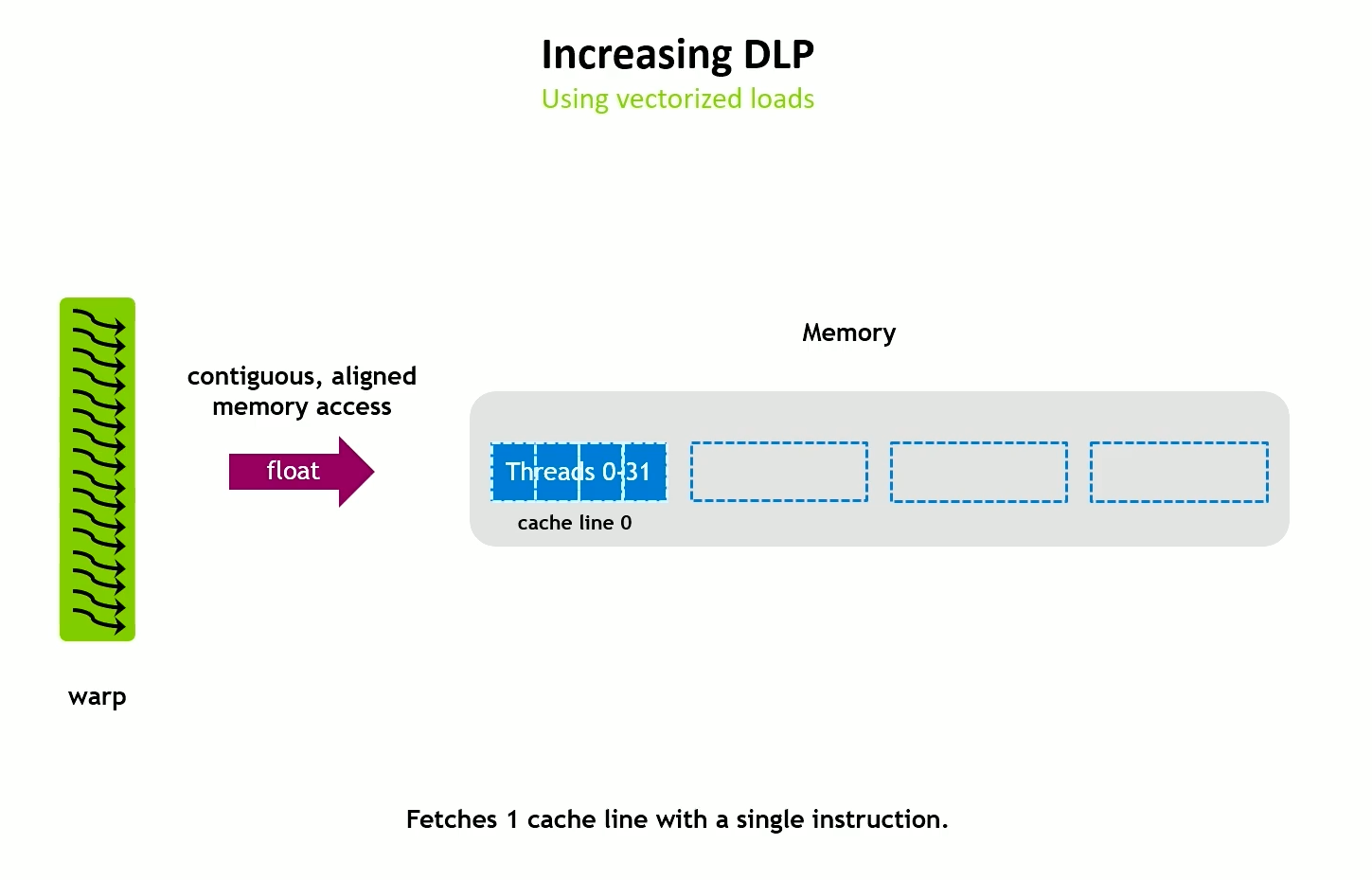
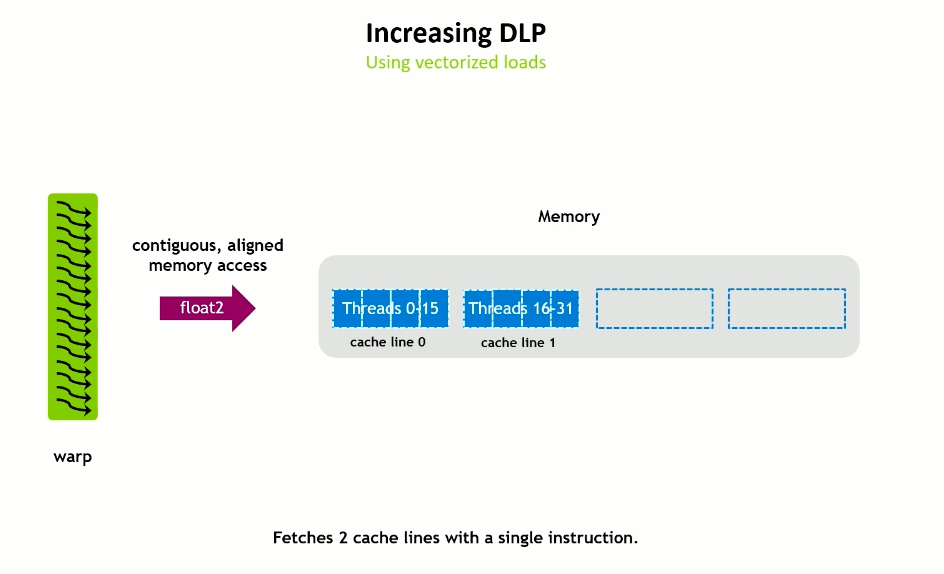
Hopper has a 128 byte cache line for both L1 and L2 caches.
Vectorized global and shared memory accesses require aligned data. Can be 64 or 128 bit width (float2, float4).
Implicit casting to vector pointers can also be used.
Increasing ILP and DLP increase register pressure
The previous techniques mentioned above increase the byte-in-flight at the cost of increased register usage.
- Bytes-in-flight need to be backed by registers.
- May lead to register spills to local memory.
Newer generation of GPUs need higher levels of ILP and DLP => more registers to saturate the memory bandwidth.
Therefore, not many registers are left for computation.
- For low compute intensity kernels, this may not be a problem.
- For high compute intensity kernels, this may lead to low occupancy and register spilling to local memory.
Asynchronous Data Copies
Asynchronous data copies are a way to skip the registers and go directly to shared memory.
- Free up more registers for computation.
- Reduce L1 traffic
- Reduce MIO pressure (less instructions)
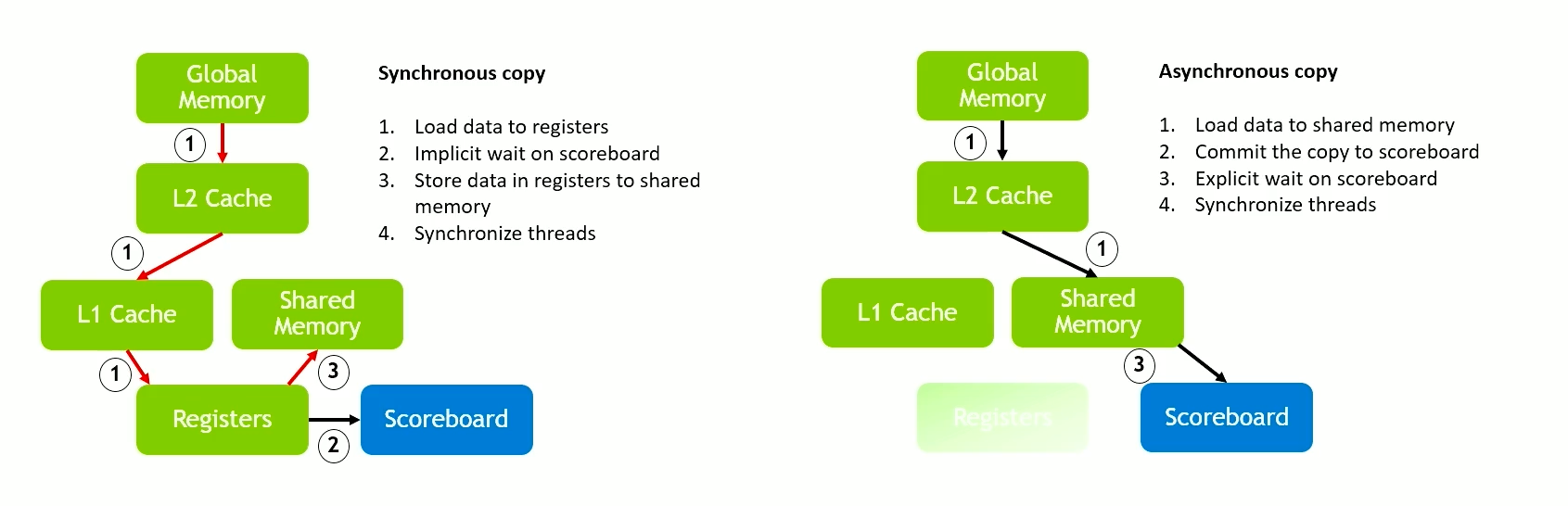
This helps us to overlap compute and data loads.
- Data prefetching - distance of \(n\)
- Producer-Consumer pattern
For the GMem -> SMem -> Computation in SMem -> Write results to GMem pattern, async copies can give large benefits when the kernel is iterative. i.e. if the prefetching can be done for future iterations.
- Especially for low occupancy compute-heavy kernels.
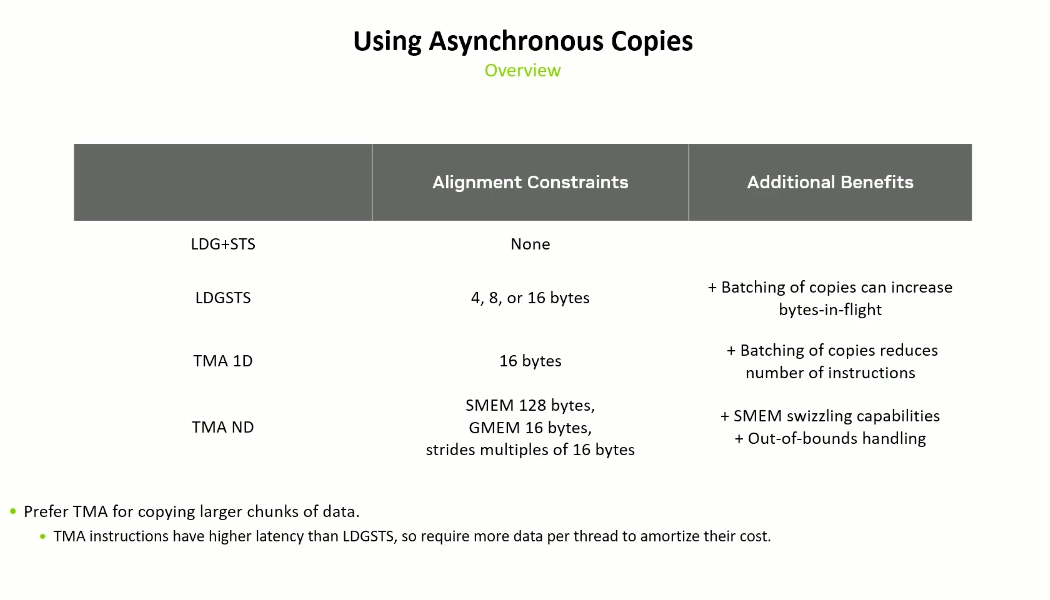
Mechanisms for async copies -
- LDGSTS in Ampere+ (Async Copy)
- TMA in Hopper+ (Bulk Async Copy)
LDGSTS
It is an async version of smem[sidx] = gmem[gidx].
- Supports copying of 4, 8, 16 bytes at a time.
- Two modes -
- L1 Bypass - the accesses invalidate / bypass the L1 cache
- size of datatype and alignment should be 16 bytes
- L1 Access - the accesses go through L1
- size of datatype and alignment should be 4 or 8 bytes
- L1 Bypass - the accesses invalidate / bypass the L1 cache
- Compiler prefers L1 Bypass mode if requirements are met.


__pipeline_commit associates a barrier with previous memcopies.
__pipeline_wait_prior’s argument indicates the number of data transfers to wait for except the last \(n\). If \(n = 0\), it waits for all.
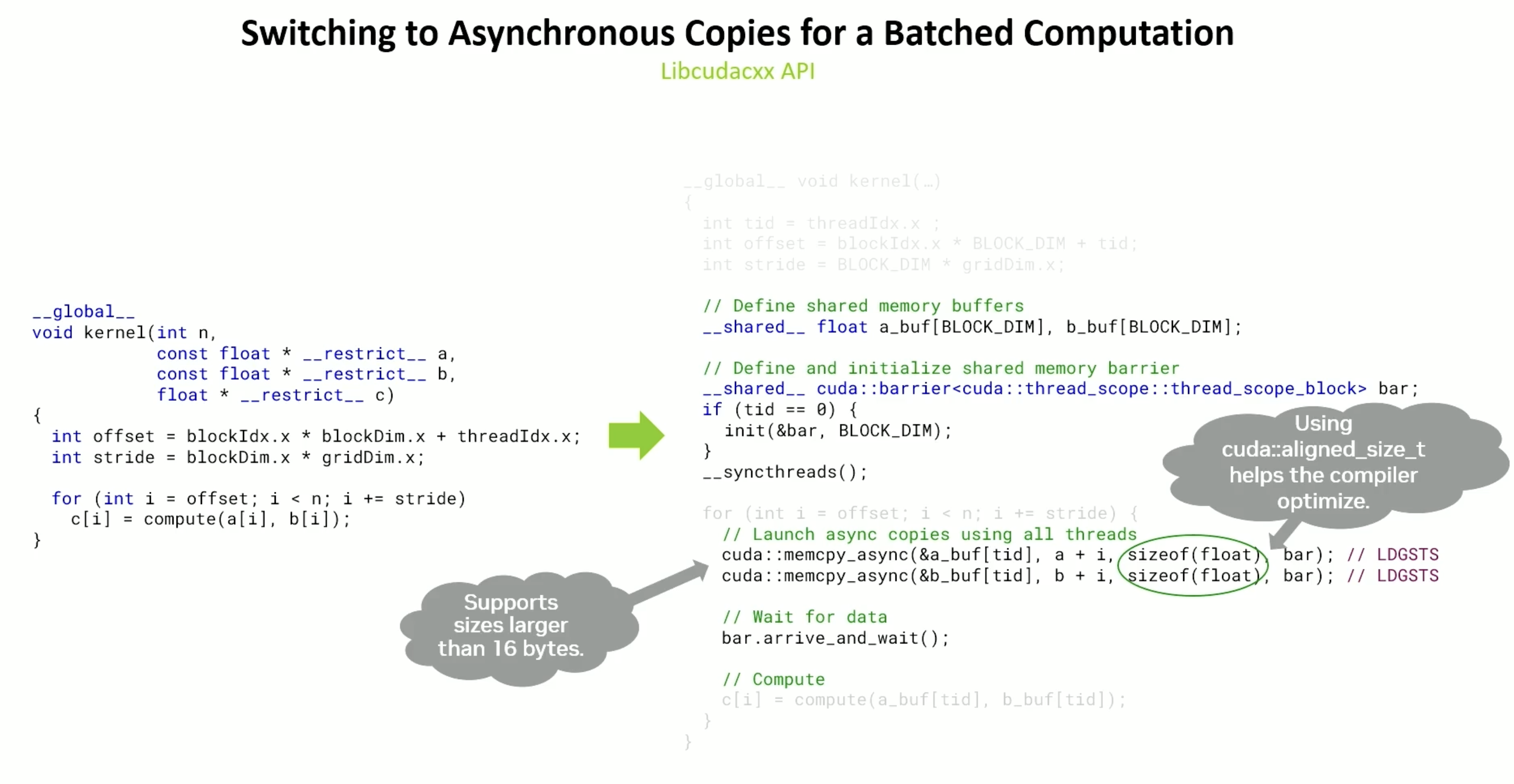
Needs an explicit barrier. Initialized with block size as all threads are going to arrive at the block.
Libcudacxx takes the barrier as input as well in memcpy_async.
Also, the libcudacxx API, can handle greater than 16 bytes under the hood.
Data Prefetching with LDGSTS

acquire and commit are called in the converged code - not in the divergent code.

There are two stages here and we wait for all except the last fetch i.e the previous iteration’s fetch (hence the \(1\) in __pipeline_wait_prior()).

The prefetching distance can be increased beyond 1. The \(\text{NUM_STAGES}\) is the number of stages in the pipeline.

Always wait for the oldest stage.

If we can copy 16 bytes at a time, i.e. float4, then we can use the L1 Bypass mode.
Less threads will be doing 16 byte loads. But all of them will be involved in the computation.

Because of producer-consumer, we need to synchronize before start of computation because a different set of threads will be doing the fetch.
Coming back to our equation for bytes-in-flight per SM,
\[\text{estimated bytes-in-flight / SM} = \text{(# bytes / load)} \times \text{(# loads / thread)} \times \text{(# threads / block)} \times \text{(# blocks / SM)}\]\(\text{estimated bytes-in-flight / SM}\) is fixed - \(> 32\) KiB for Hopper and \(> 40\) KiB for Blackwell.
\(\text{(# bytes / load)}\) is fixed
Similarly, \(\text{(# threads / block)}\) and \(\text{(# blocks / SM)}\) are fixed - based on occupancy.
So, we need to control \(\text{(# loads / thread)}\) is tunable and is dependent on the number of stages. For the above example, it is (2 * number of stages).
TMA (Tensor Memory Accelerator)
TMA is an efficient data transfer mechanism for bulk copies. There are two programming models -
- Bulk async copy of one-dimensional contiguous arrays (TMA 1D)
- Bulk async copy of multi-dimensional arrays (TMA 2D)
The programming model is warp uniform.
- Unlike LDGSTS, it is more efficient to call TMA from a single thread per warp.
- If more threads per warp are active, the compiler will generate a peeling loop to execute each TMA operation sequentially.
TMA 1D (UBLKCP)
Uses shared memory barriers.
Alignment requirements -
- Source and destination pointers should be 16 byte aligned.
- Copy size should be a multiple of 16 bytes.
API libcudacxx <cuda/ptx>
-
cuda::memcpy_async()combined withcuda::barrier -
cuda::device::memcpy_async_tx()combined withcuda::barrier -
cuda::ptxcan be used for finer-grain barrier synchronization using PTX.
Also enabled in thrust::transform in CCCL. Thrust will internally auto-tune the bytes-in-flight.
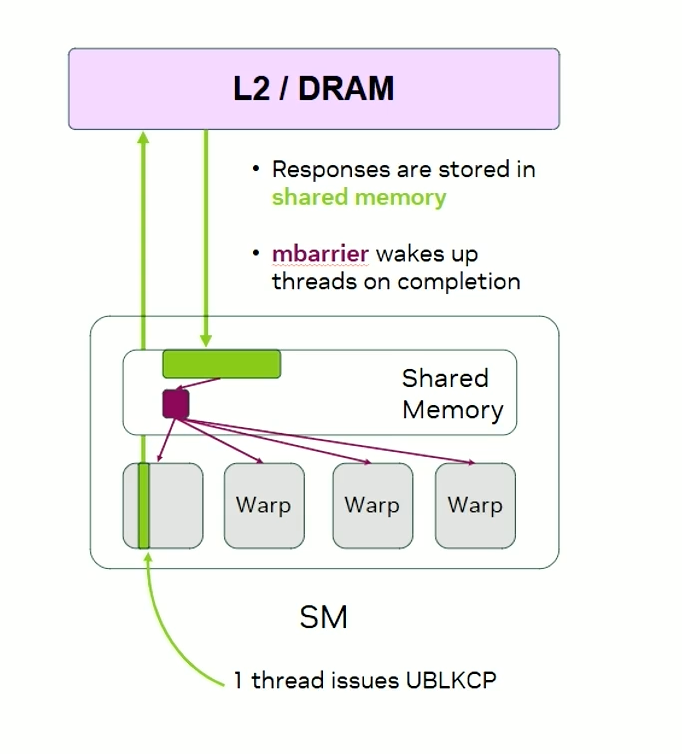

As shown above, only one thread launches the copy.
Each thread receives a token which it uses to wait on the barrier.
memcpy_async has a fallback mechanism to handle the case when the copy size and/or alignment is not a multiple of 16 bytes.

However in memcpy_async_tx there is an undefined behavior if the copy size and/or alignment is not a multiple of 16 bytes.
So, generally it is safer to use memcpy_async.
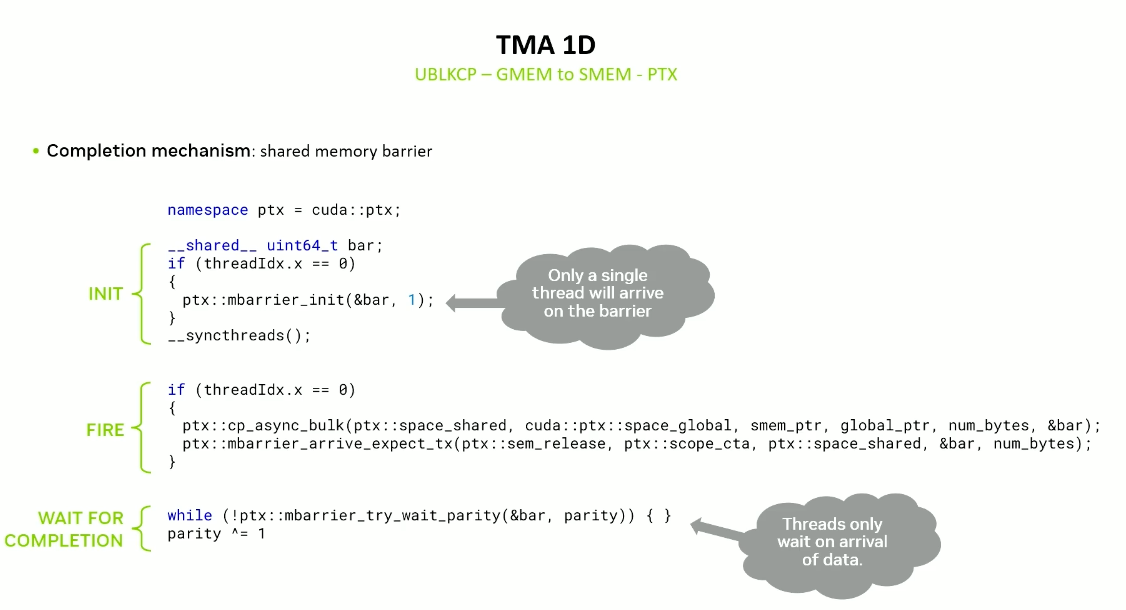
PTX gives finer control over synchronization.
Using the PTX API, we can only have one thread arrive at the barrier and inform the barrier how many bytes it is expected to transfer.
Waiting here is faster as we are essentially checking if data has arrived or not and not if all threads have completed. This is faster than barrier.wait().
Interestingly, when we launch TMA using only one thread, compiler does not know that this is true and still generates a peeling loop.
For this, the invoke_one function from cooperative groups API is used.
Using Async copies for batched computation

Thrust gives a zero-effort way to do this as well using thrust::transform.

Data Prefetching with TMA 1D

Can’t use pipeline construct and need to have two shared memory barriers (for two stages).

Optimization Guidelines Mindmap

If registers are available (and we are not limited by register pressure), we should do unrolling and vectorization.
If registers are not available, we can use shared memory.
Size of chunk of data can determine LDGSTS or TMA.
- More than 2KiB -> TMA
- Less than 1KiB -> LDGSTS
- Between 1KiB and 2KiB -> Benchmark both and decide.
Hope this was helpful!
Refer to part 2 of the notes here.