Notes from GTC'25: CUDA Techniques to Maximize Memory Bandwidth and Hide Latency - Part 2

You can watch the talk here - link
Part 1 of the talk focused on maximizing memory throughput. The notes can be found here.
These are the notes for the second part of the talk which focused on memory models and hiding latency.
Memory Model
Memory model is a way to understand how memory is accessed and used in a program. It is a contract between the user and the compiler/hardware/language.
Single-threaded
Standard memory model.
Stores are visible to the thread that stored them.
Loads and stores to the same address remain in order - they cannot overtake each other in the memory subsystem.
Important concept - same-address ordering.
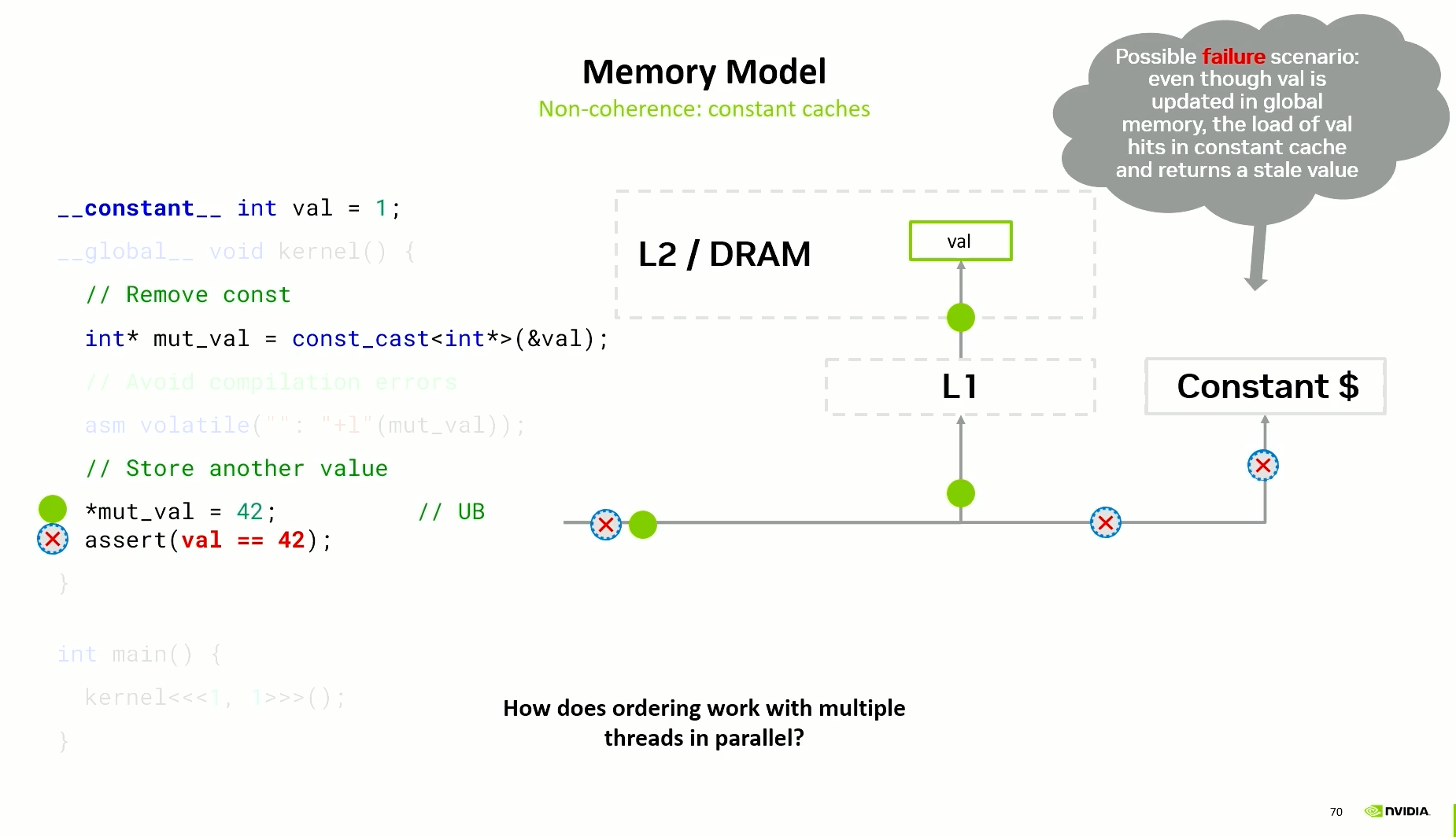
Same-address ordering does not hold always. E.g. when using constant caches. The constant caches have a link to the L2 cache but not to the L1 cache. Hence, these caches are not coherent.
So, constant cached values can cause issues. You can do the store - which would go through L1 to the L2 and update it. However, during load, the constant cache is used and it returns the old value.
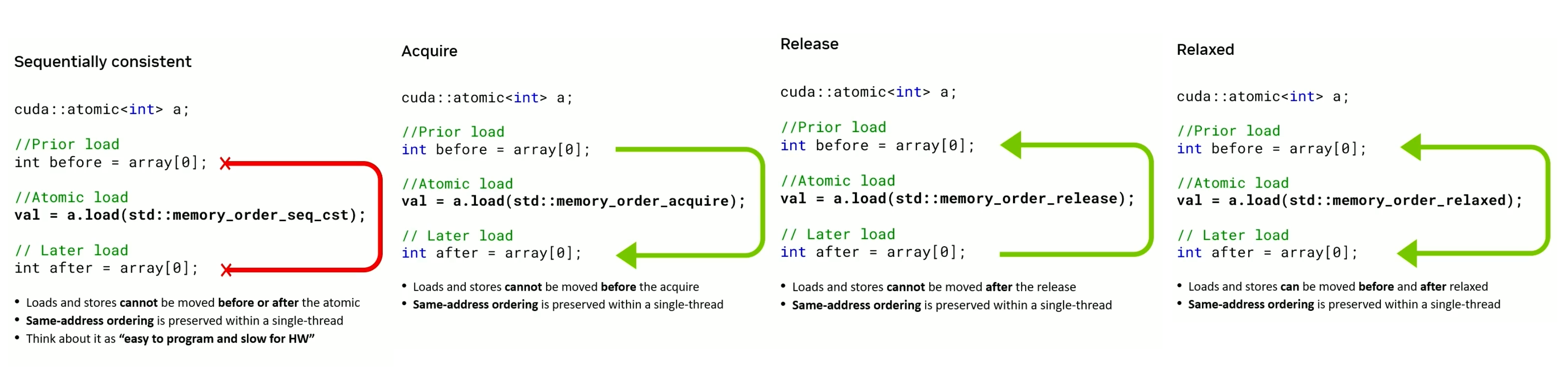
Memory Ordering
Memory order specifies how memory accesses, including regular (non-atomic) accesses, are to be ordered around an atomic operation.
Four important memory orders in multi-threaded memory model:
- Sequentially consistent
- Acquire
- Release
- Relaxed
Multi-threaded
CUDA C++ Scope
- Thread -
cuda::thread_scope_thread- Only local thread can observe this thread’s loads and stores - Thread Block -
cuda::thread_scope_block- Only threads in the same block can observe this thread’s loads and stores - GPU Device -
cuda::thread_scope_device- All threads in the GPU can observe this thread’s loads and stores - System -
cuda::thread_scope_system- All threads in the system (CPU, other GPUs, other nodes) can observe this thread’s loads and stores
CUDA PTX Scope
- Thread Block -
.cta- Only threads in the same block can observe this thread’s loads and stores - GPU Device -
.gpu- All threads in the GPU can observe this thread’s loads and stores - System -
.sys- All threads in the system (CPU, other GPUs, other nodes) can observe this thread’s loads and stores
Thread scope - Block
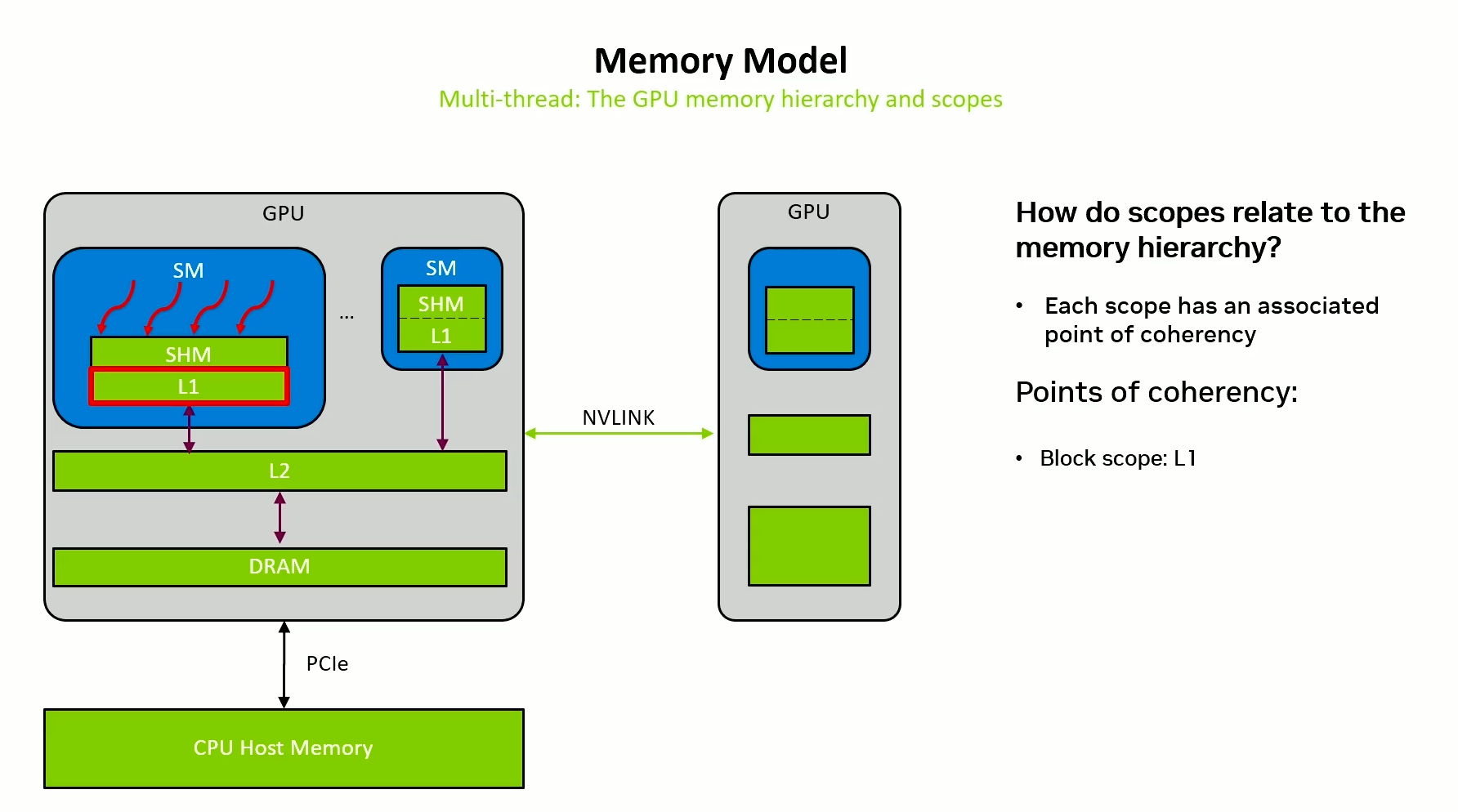
Threads in the same block execute on same SM.
Data only has to be consistent in L1. All threads in the block see the same data.
Release and acquire semantics are quite fast. Because data does not have to be flushed very far. We don’t have to invalidate many caches.
Thread scope - Cluster
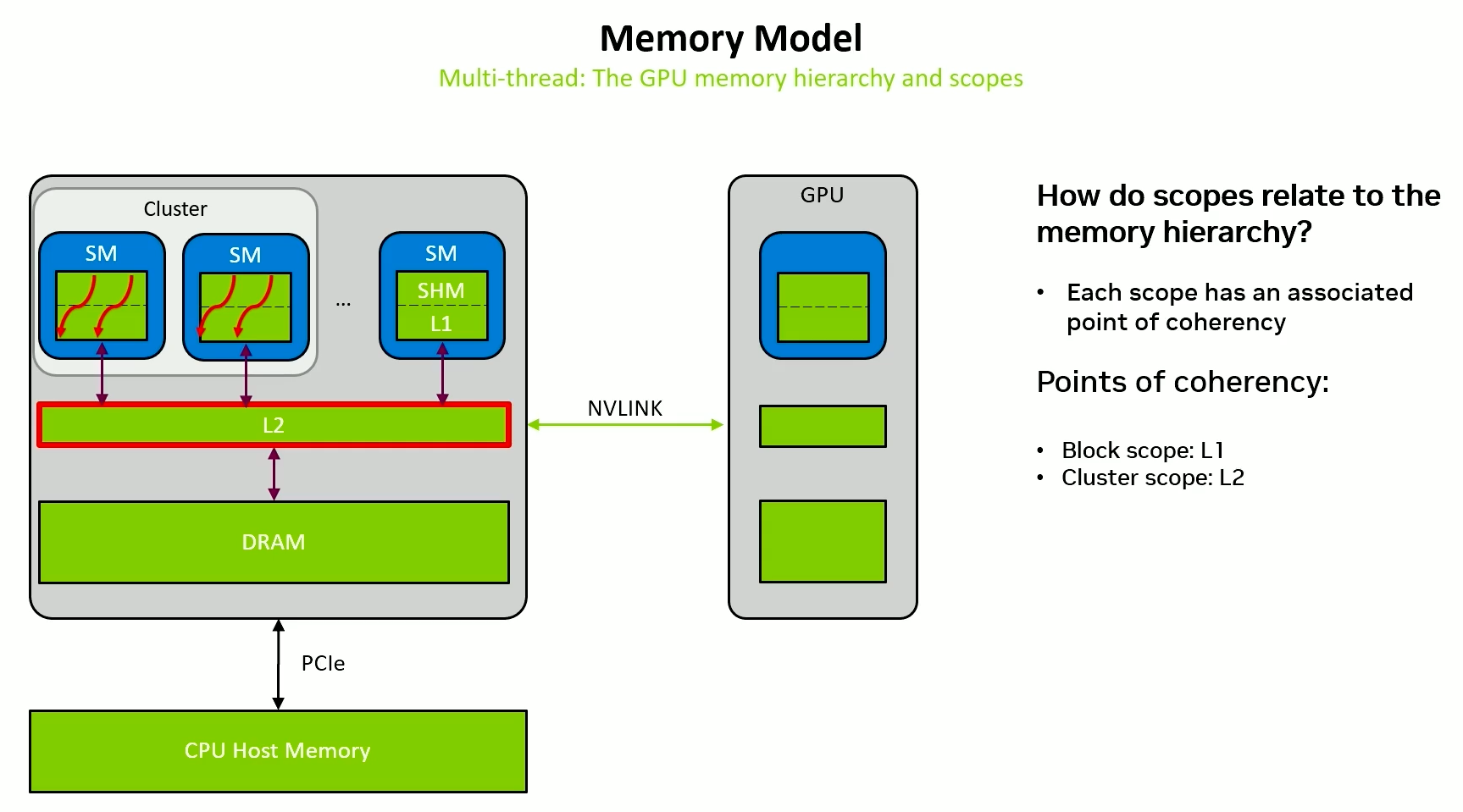
Many threads working across multiple SMs working together.
Data has to go through L2.
In release, we would have to flush to L2 and in acquire, we would have to make sure that L1 is invalidated.
Thread scope - GPU
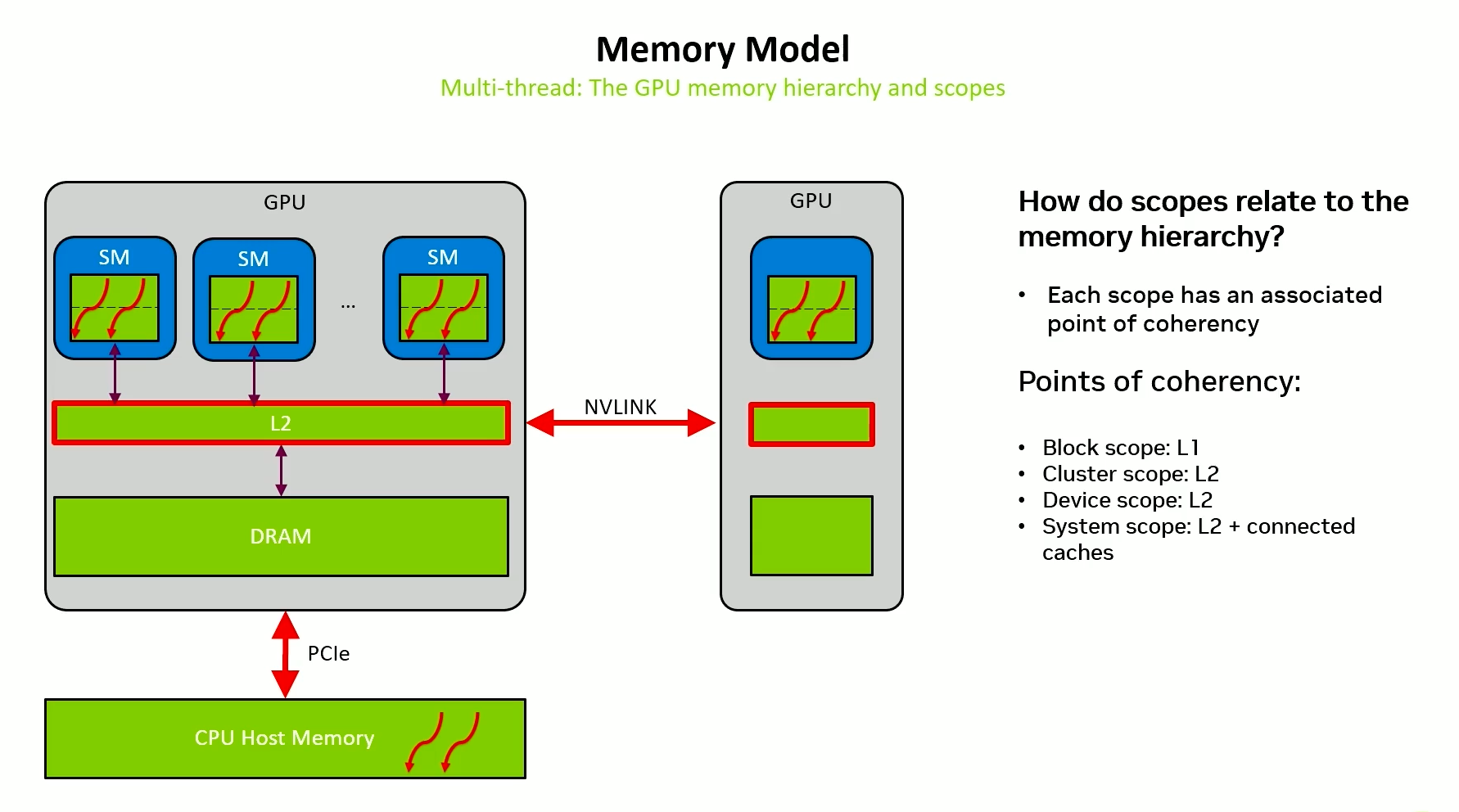
Many threads working across multiple SMs of a GPU working together.
Synchronization is as difficult as cluster.
In release, we would have to flush to L2 and in acquire, we would have to make sure that L1 is invalidated.
Thread scope - System
Many threads working across multiple GPUs working together.
In release, we would have to make sure that all the stores made it to the relevant caches across GPUs and nodes.
Acquire is still cheap, all L1s need to be invalidated.
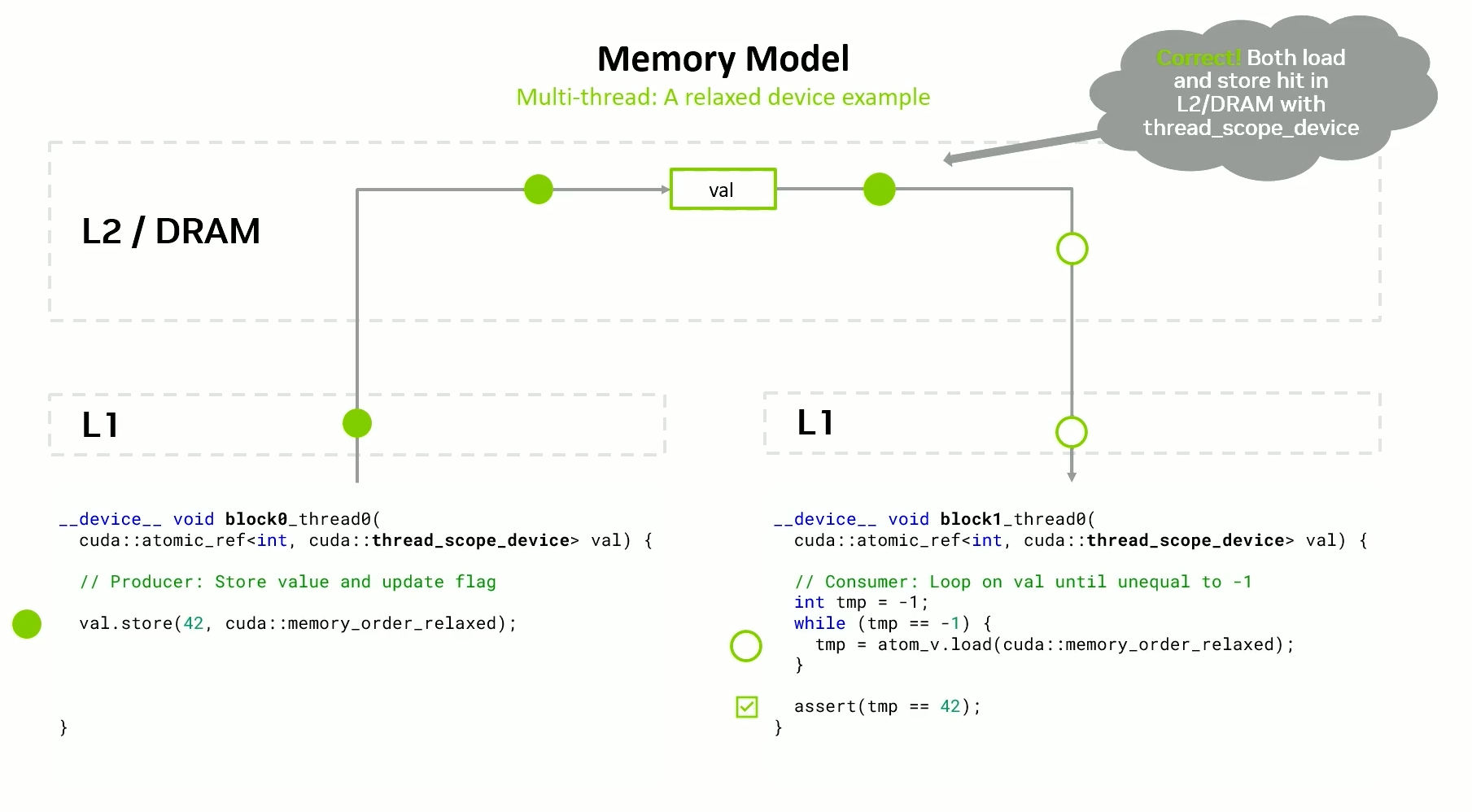
Data transfer examples
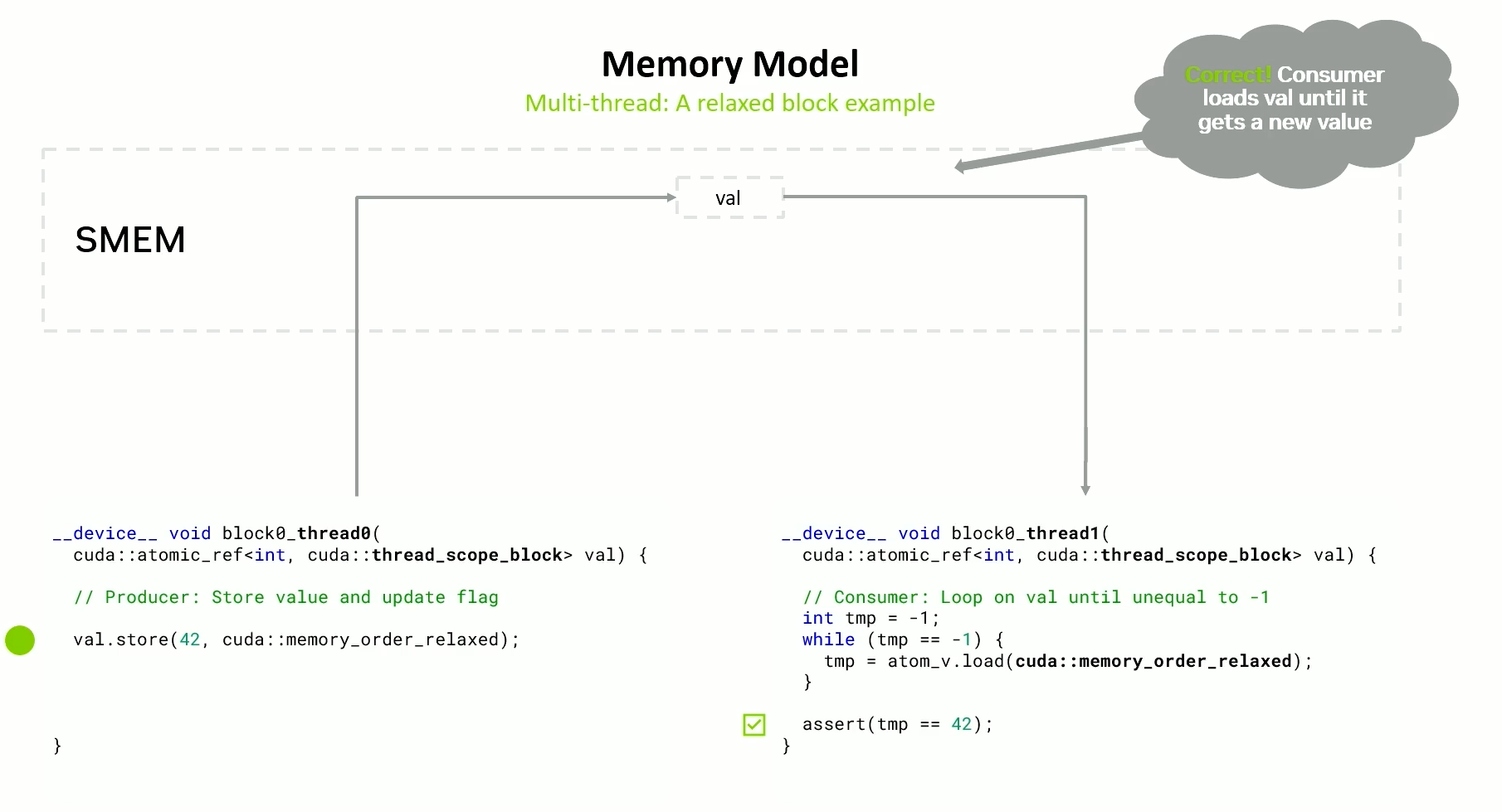
Using thread scope block when working with same block.
Using thread scope device when working with different thread blocks.
But, for a not so relaxed example, where there are two variables we need to work with, simply using device scope is not enough.
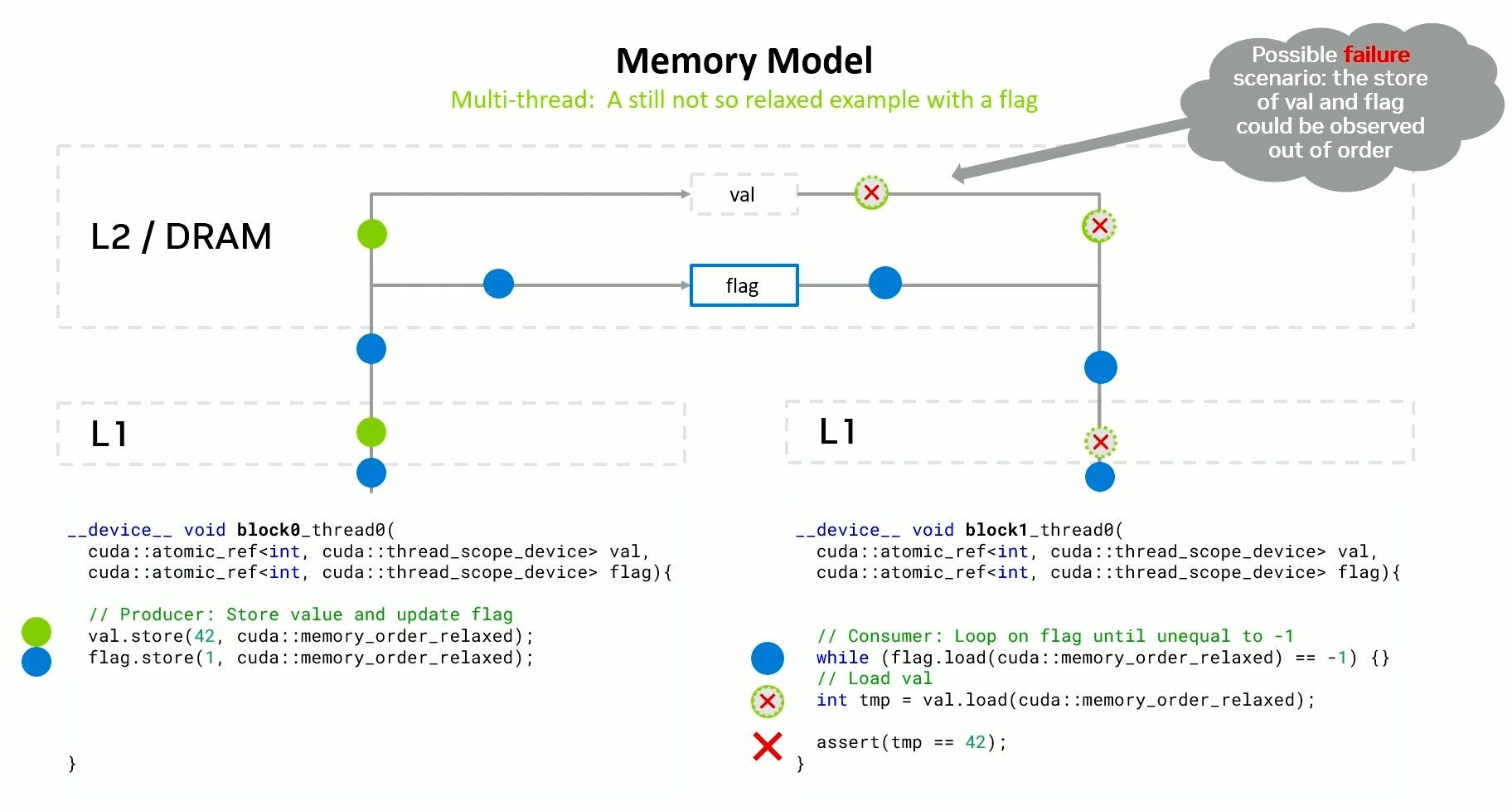
We need to use a release-acquire pattern.
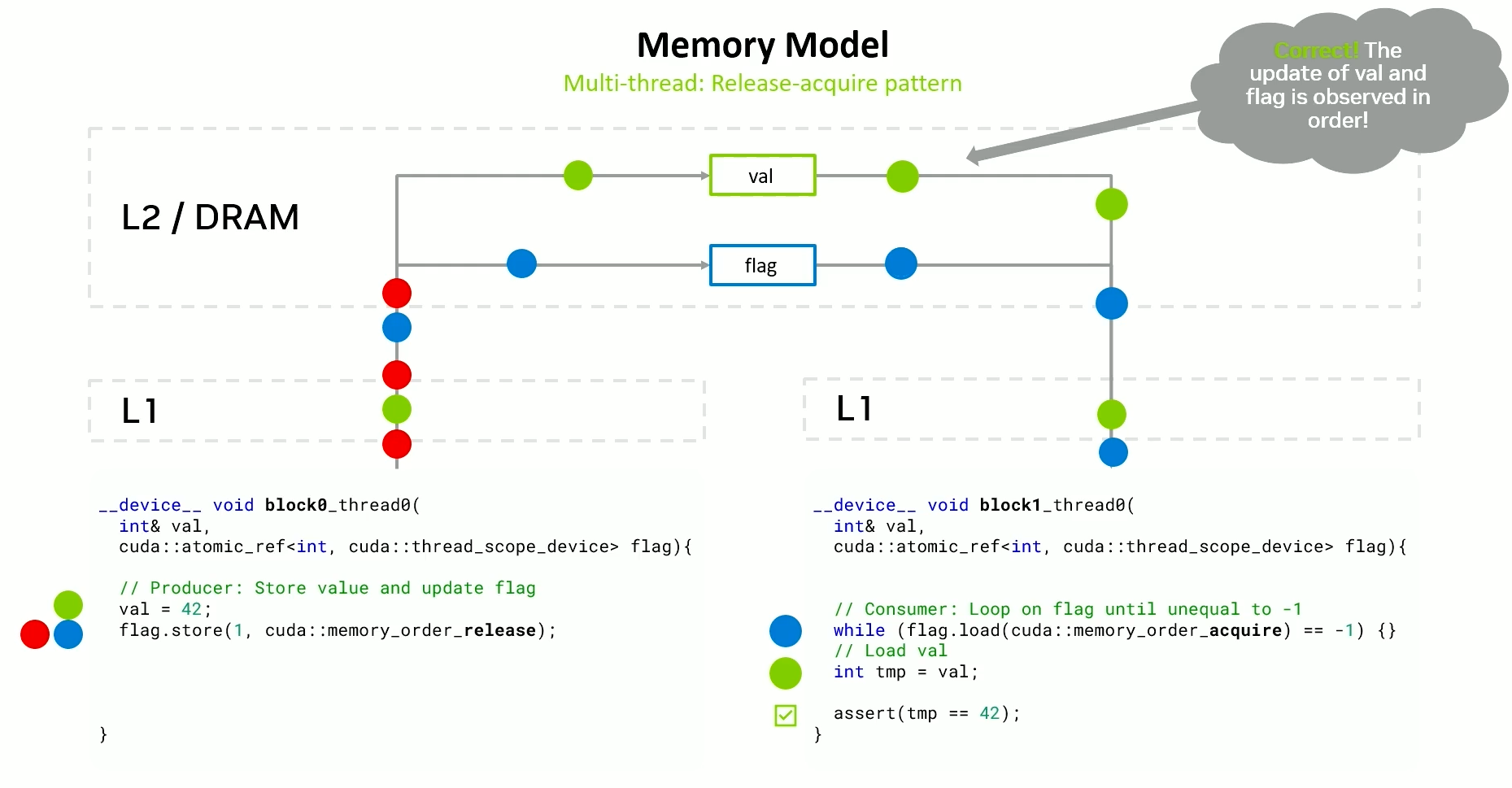
Relaxed vs Release-Acquire
Relaxed
- Faster - A single store or load to or from the cache at the point of coherency.
- Does not provide ordering w.r.t other reads and writes.
- Useful if two threads want to exchange one value.
Release-Acquire
- Slower - Requires flushing to point of coherency and / or invalidating caches.
- Provides ordering w.r.t other reads and writes.
- Useful if multiple threads want to exchange multiple values.
For larger chunks of data, release-acquire is preferred.
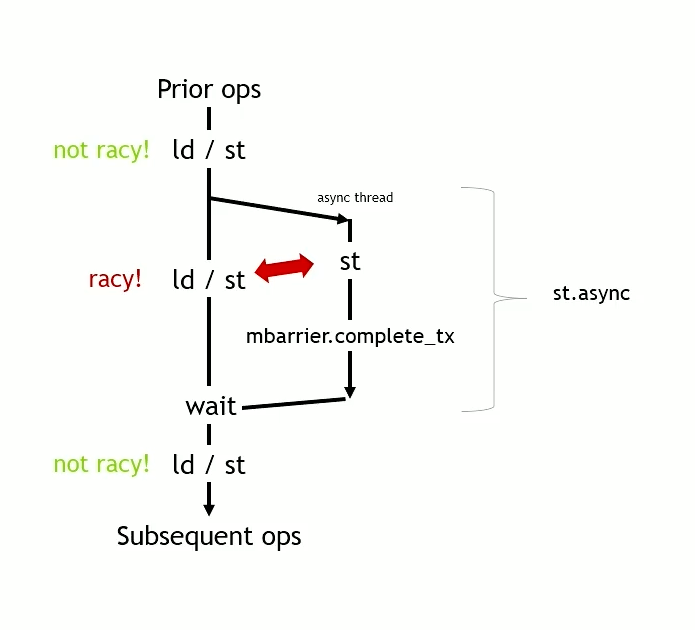
Async thread - Ampere
PTX instruction st.async
- Stores a value to Distributed Shared Memory of another block in the cluster/
- Once the store is complete, it updates a shared memory barrier in the shared memory of the other block.
However, a subsequent load or store can race ahead, violating the same-address ordering.
Async proxy - Hopper
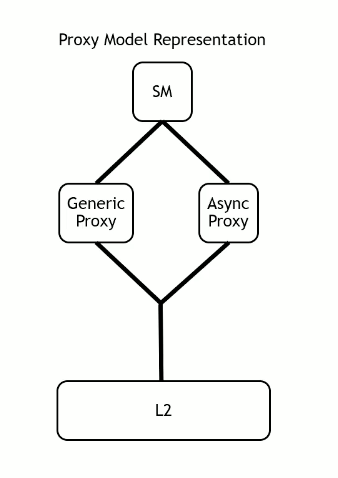
Proxies represent situations where there are multiple different paths from a single thread to a single physical memory location, with no coherence across paths.
Generic Proxy - All normal loads and stores go through the generic proxy.
Async Proxy - A different path that is used by TMA units, tensor cores and several other instructions.
Between a generic proxy load/store and an async proxy load/store, there is no same-address ordering. Even less than earlier (async threads).
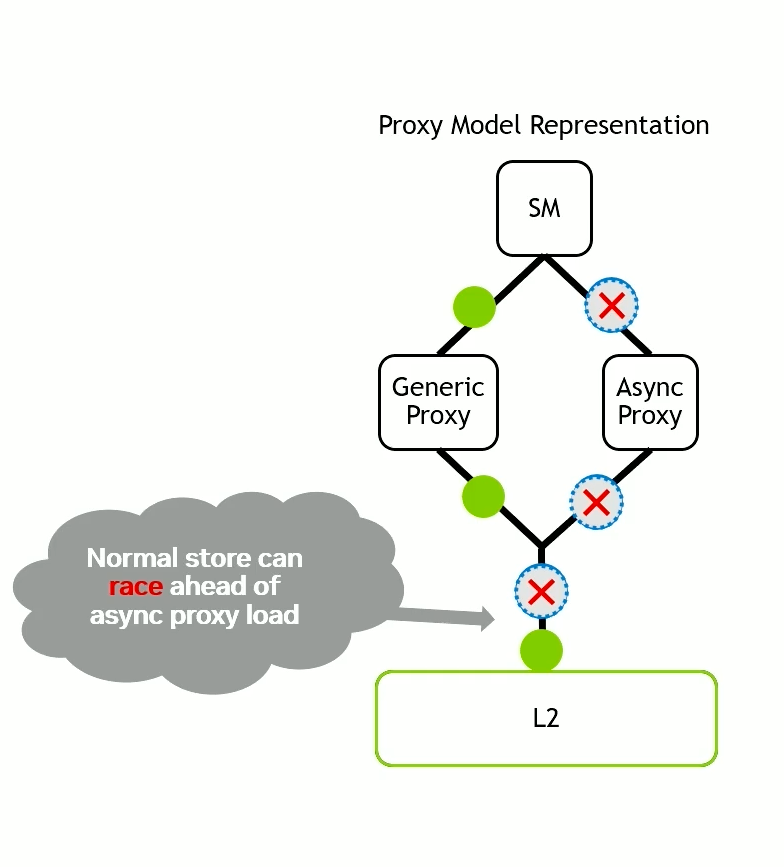
The normal store can overtake the TMA load.
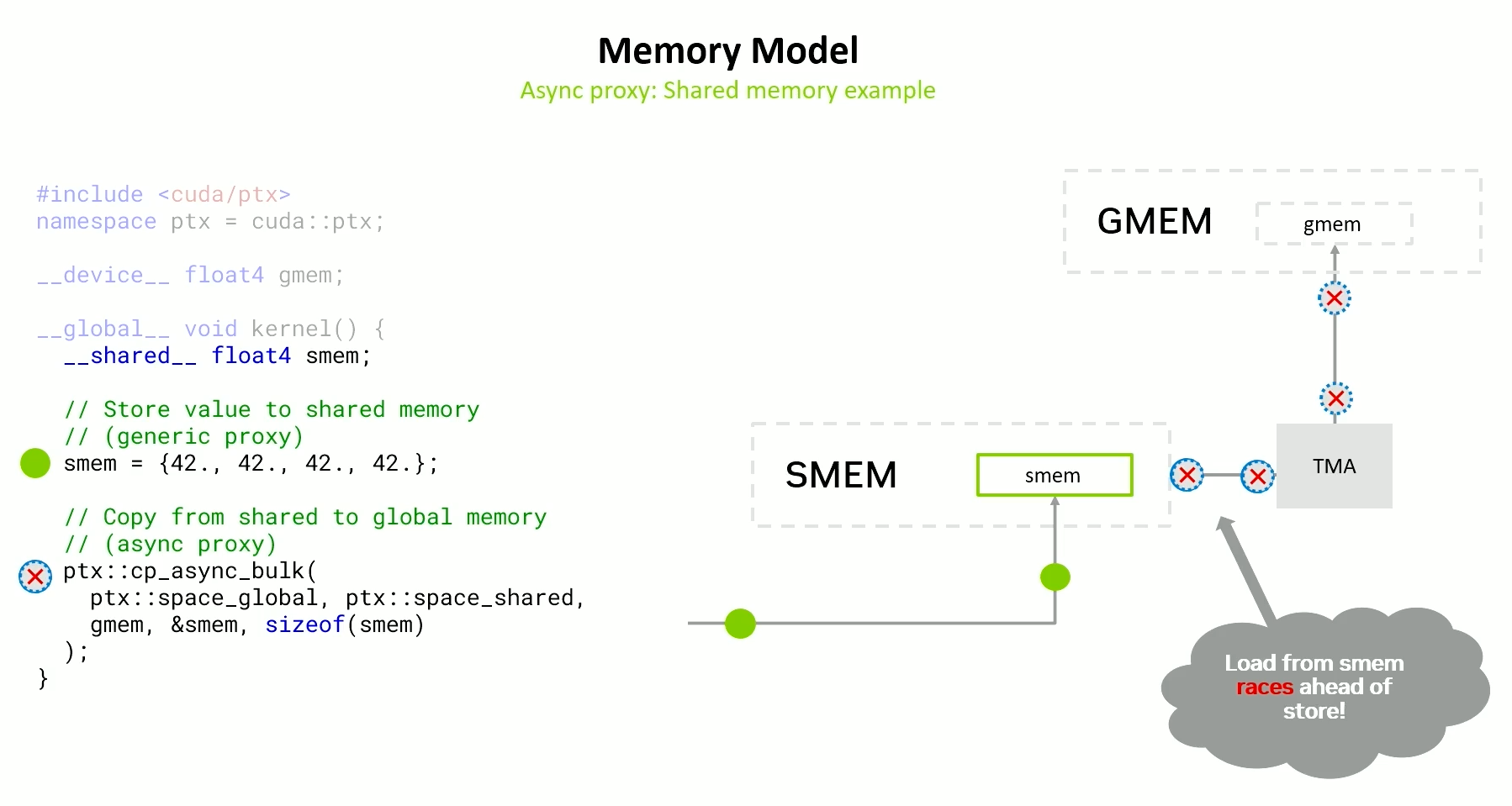
Here, the generic proxy store to shared memory will be most likely overtaken by async proxy load from shared memory.
This will store stale values to global memory.
Async Proxy Fence
Solution is to use an async proxy fence -
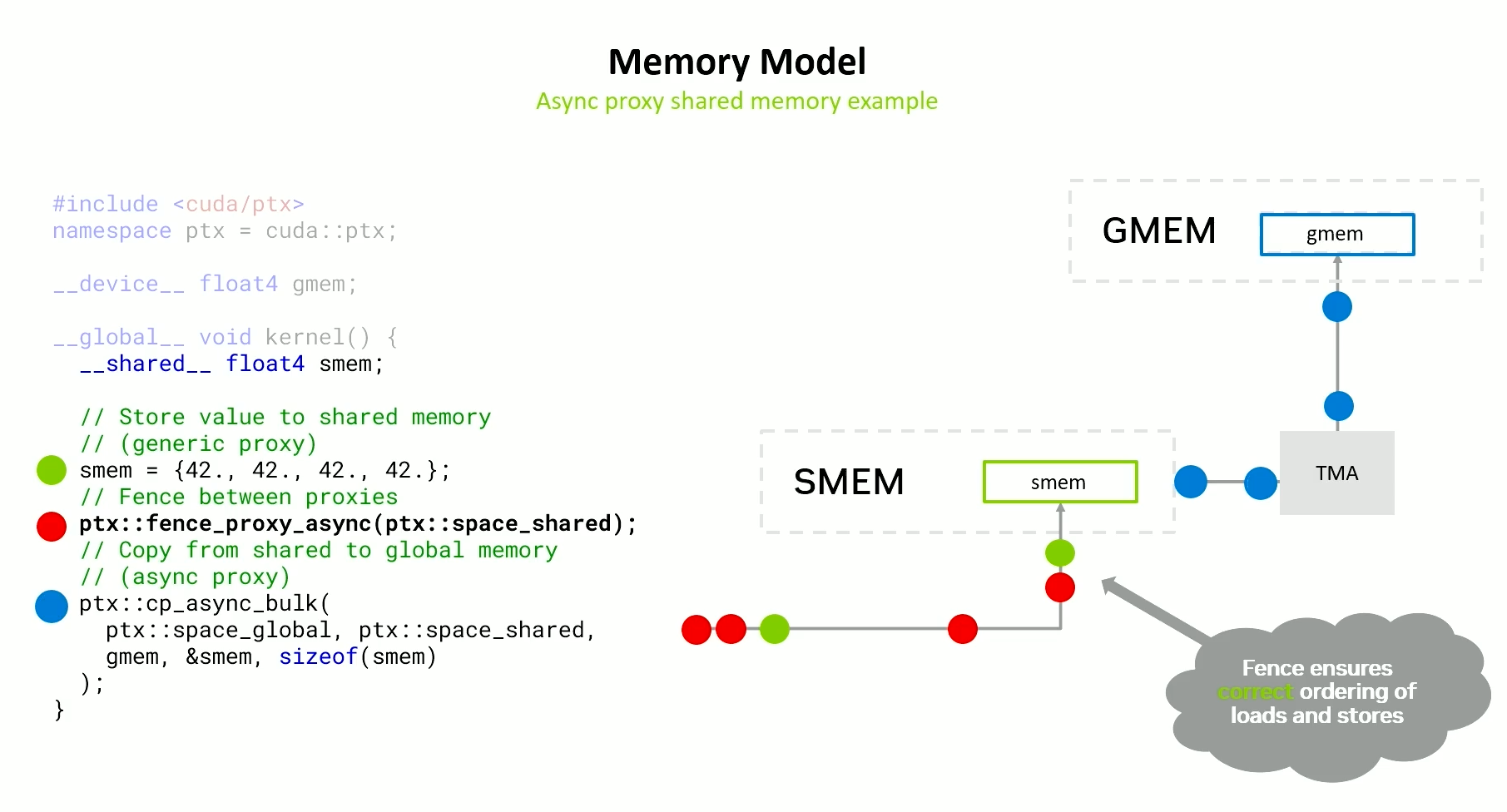
The fence traces the store to shared memory, and makes sure that the store is complete. Once it is complete, the fence comes back, notifies the thread and only then will the TMA load be allowed to proceed.
Implicit Fencing
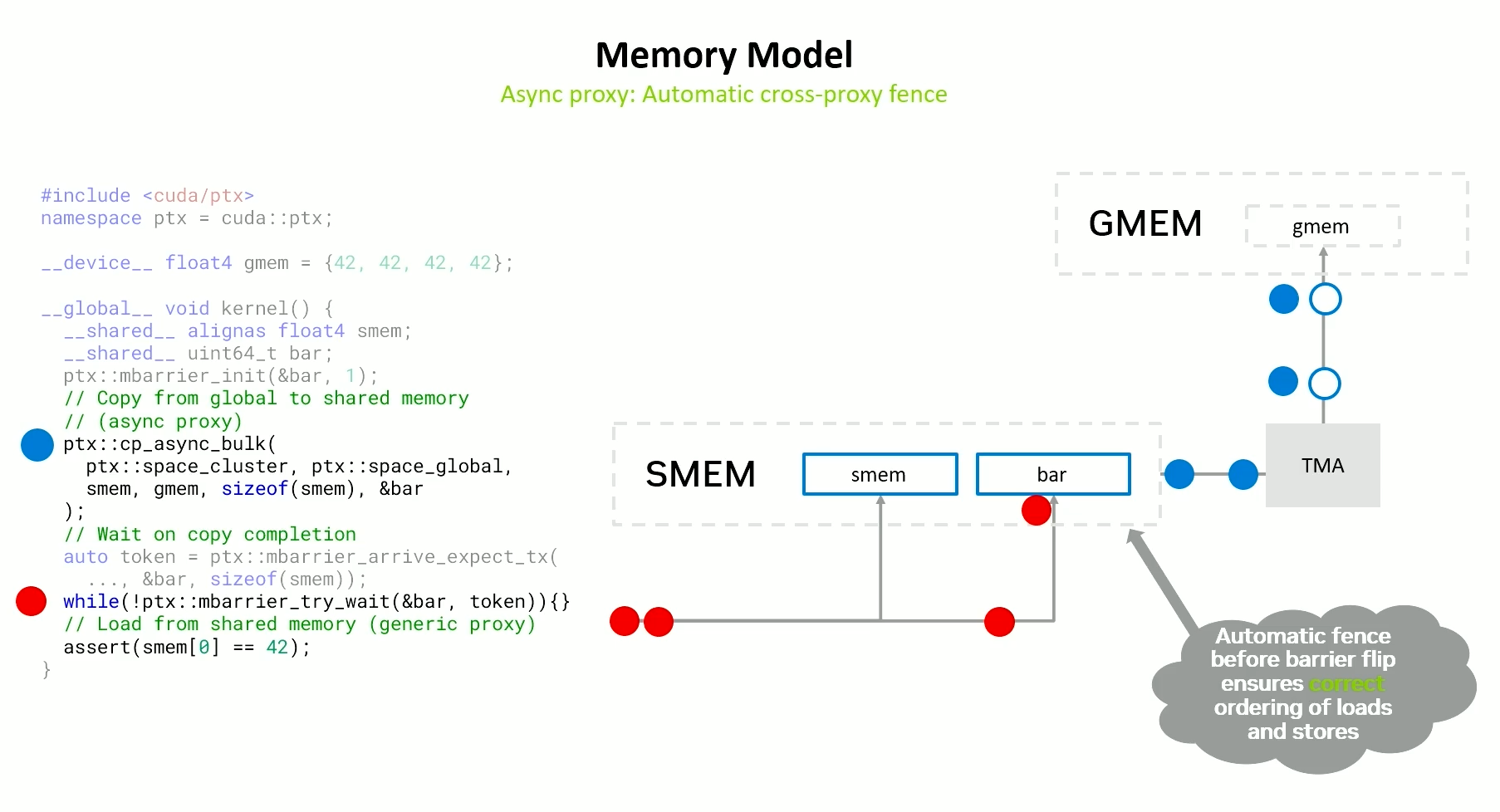
Here we start waiting on the barrier after the copy async bulk is issued. Barrier waiting request goes to to the shared memory until the load is finished. Only when all the required updates to the shared memory are done (stores), the barrier is updated.
Async thread and Async proxy instructions
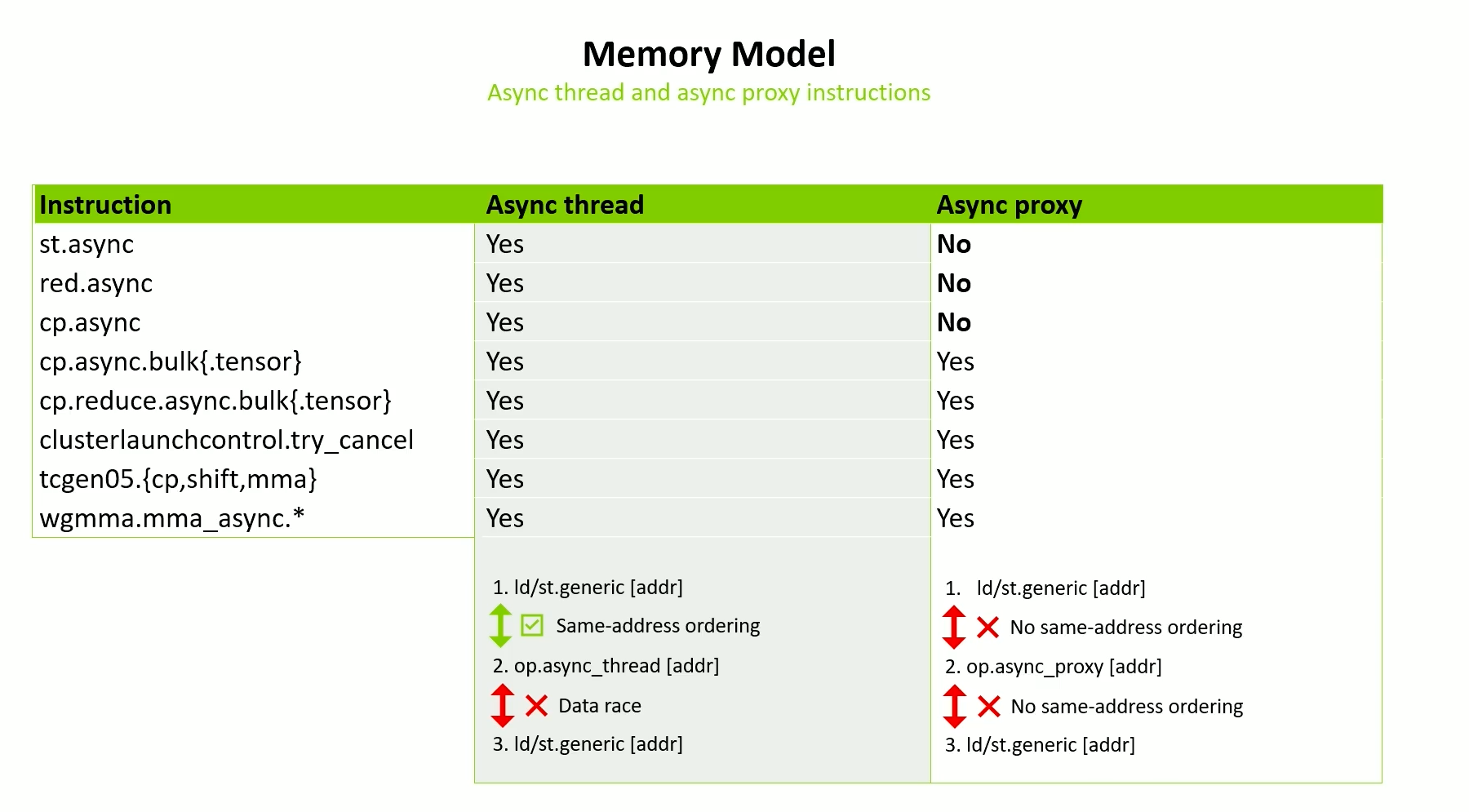
-
st.asyncandred.asyncare in Hopper but still async thread only -
cp.async- Ampere - If you have a normal load and store before - obeys same-address ordering
- But normal load and store after - it will not obey
- Async proxy fence is still needed to ensure correct ordering
Low-Latency Cluster Synchronization
Key points
- The point of coherency for a cluster is L2 - thread blocks can be in different SMs
- Any release-acquire pattern with cluster scope requires a round trip to L2 which is expensive
- To reduce latency - avoid these round trips
Thread synchronization in a cluster
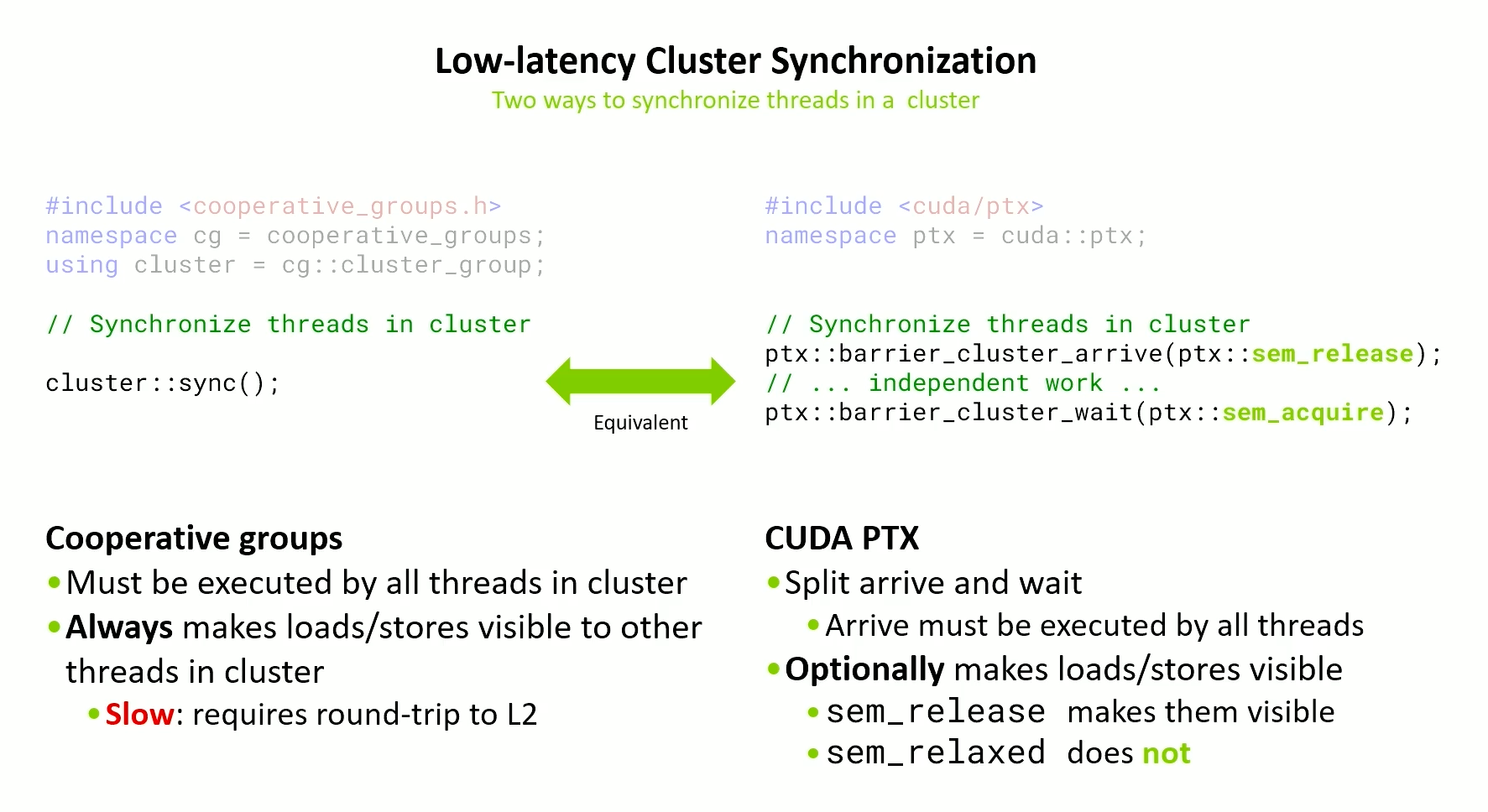
Arrive has to be executed by all threads in a cluster but wait doesn’t need to be.
The arrive can have different memory model orderings.
- Release - Requires flushing to L2 but gives synchronization of data
- Relaxed - Only execution synchronization but no data synchronization
Barrier Initialization - Simple way
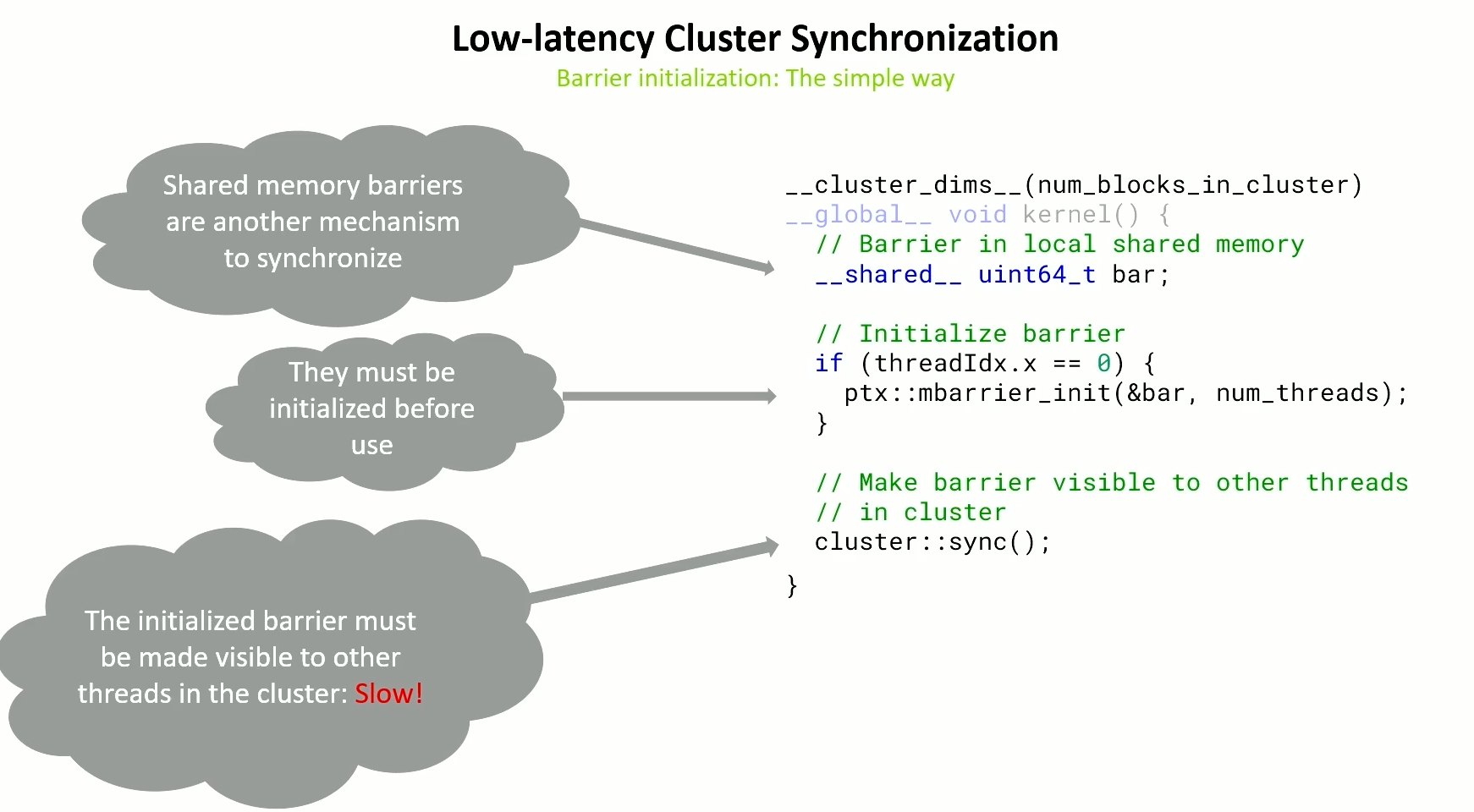
Initializing a shared memory barrier and making it visible to all threads in the cluster.
A cluster sync is done to make the barrier visible to all threads.
Nothing needs to be flushed to L2 => this is more expensive than it has to be.
Barrier Initialization - Fast way
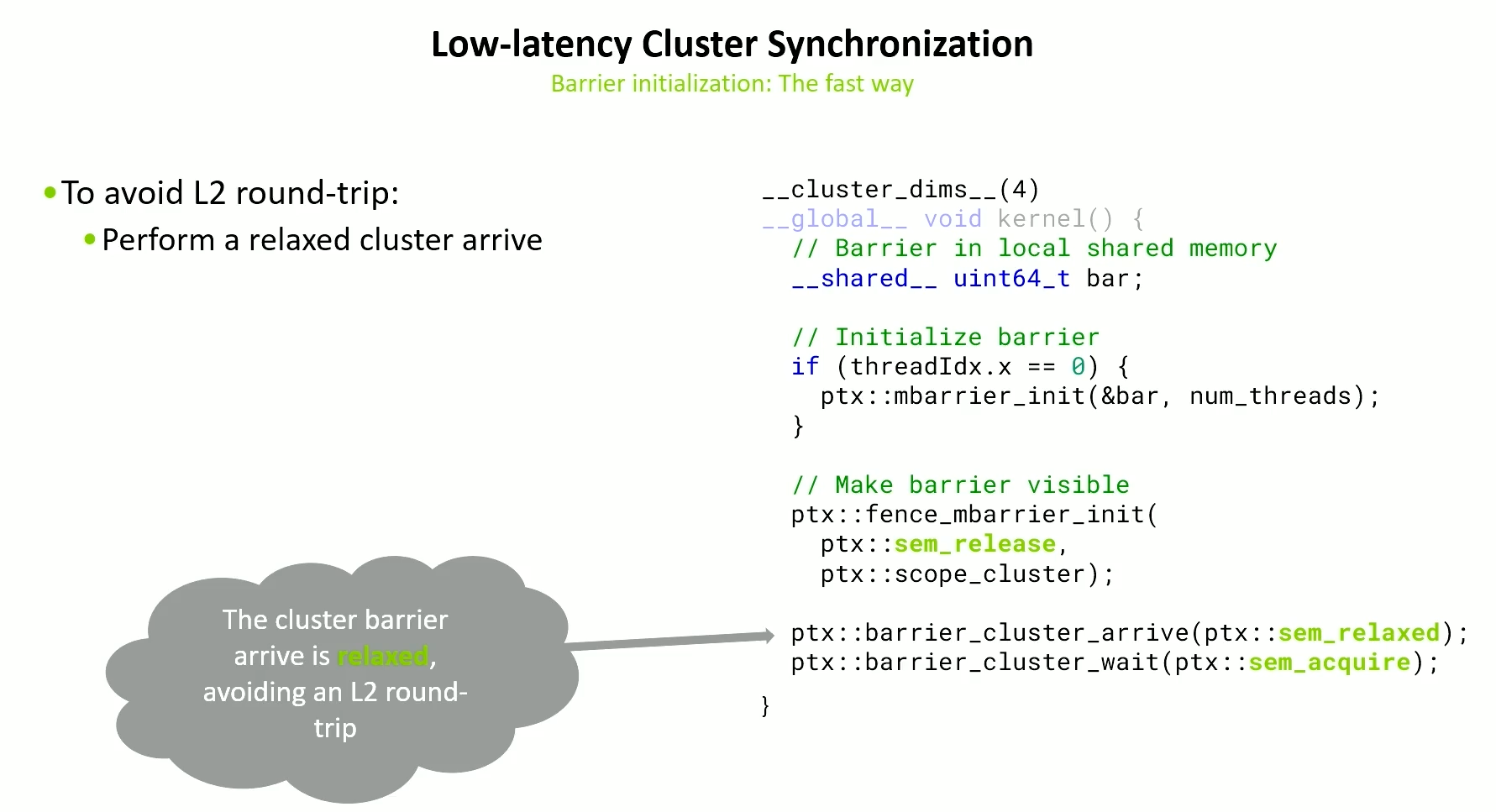
Instead of cluster::sync, we use a relaxed arrive which does not flush anything to L2, but ensures execution synchronization.
But to ensure correctness, we do a release fence of just the mbarrier init.
Additionally there is a release-acquire pattern and they have to be scope clusters.
fence_mbarrier_init, arrive and wait are all fairly cheap.
For kernels which are short, this type of optimization can help a lot. However, for long kernels, this won’t help much.
Data communication in a cluster
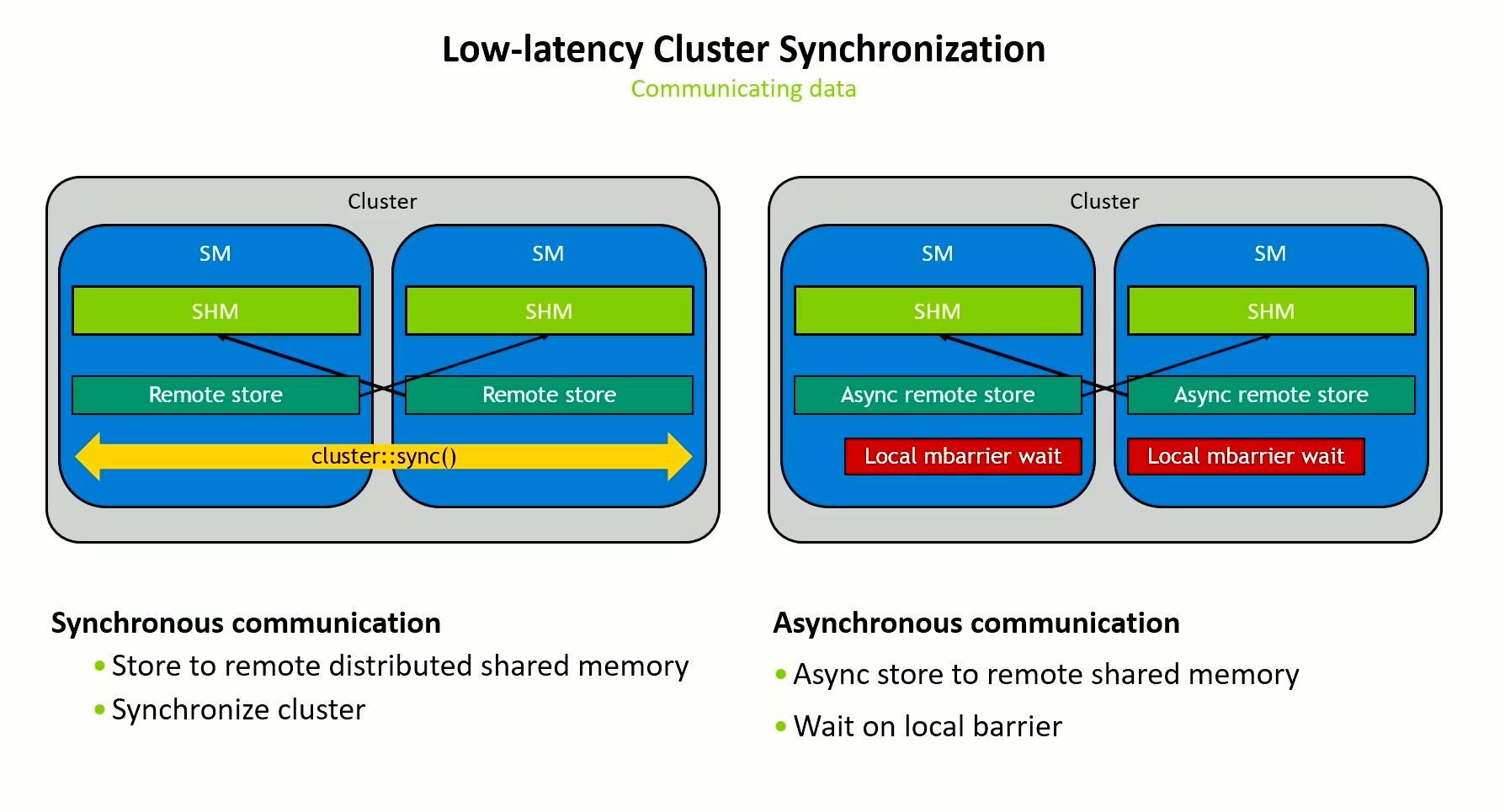
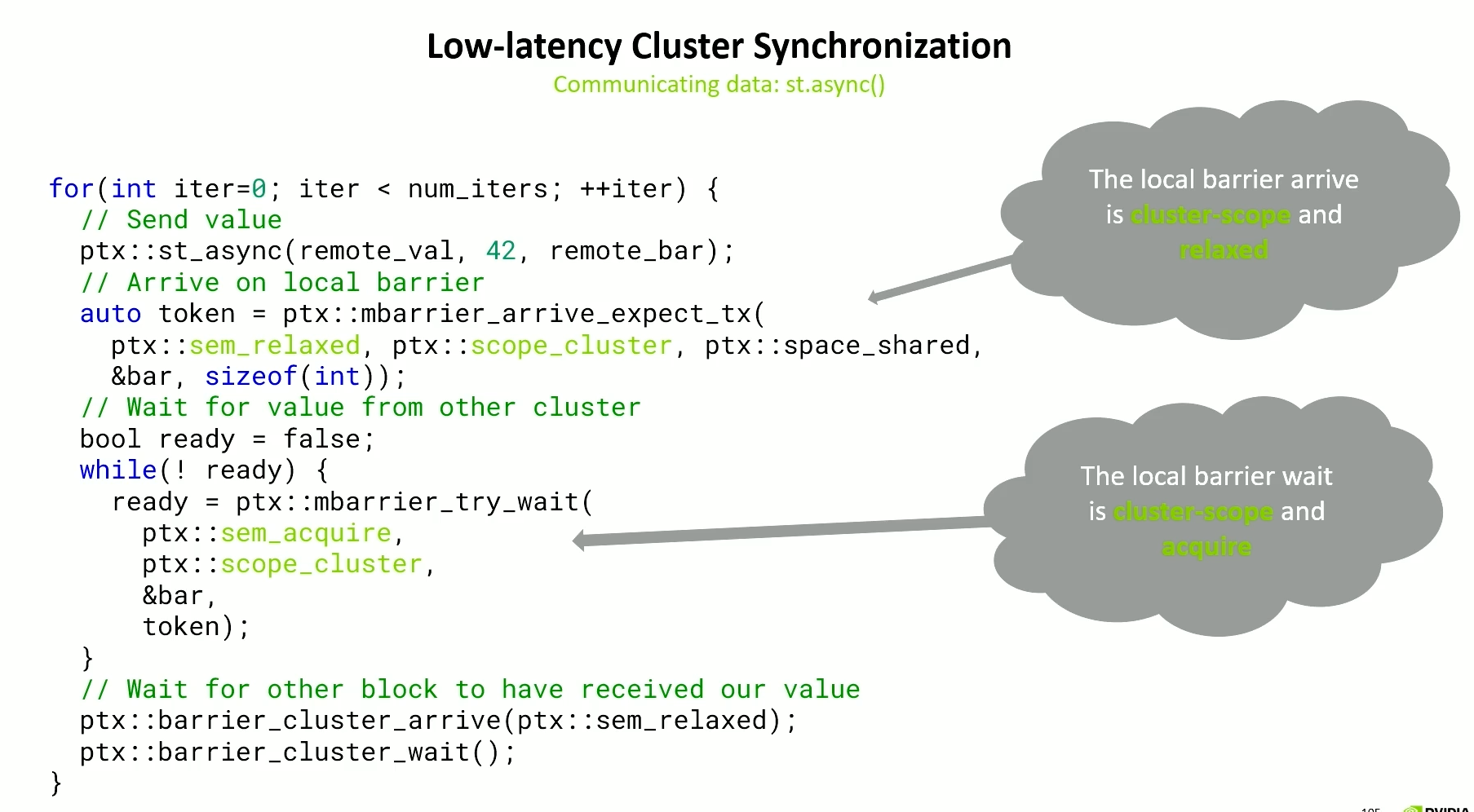
- Arrival should be relaxed and scope_cluster. If it were a release, then it would have a flush to L2.
- Wait from other cluster should be acquire (in a loop) so that it can form a release-acquire pattern with
st_async. Asst_asyncjust releases the 4 bytes it has stored and that’s what we acquire in thembarrier_try_waitwhich is also a scope cluster and you wait on the local barrier which is cheap. - FInally, we need to make sure the other thread in the cluster got our value before we send another. This can be relaxed as we just need to ensure execution synchronization.
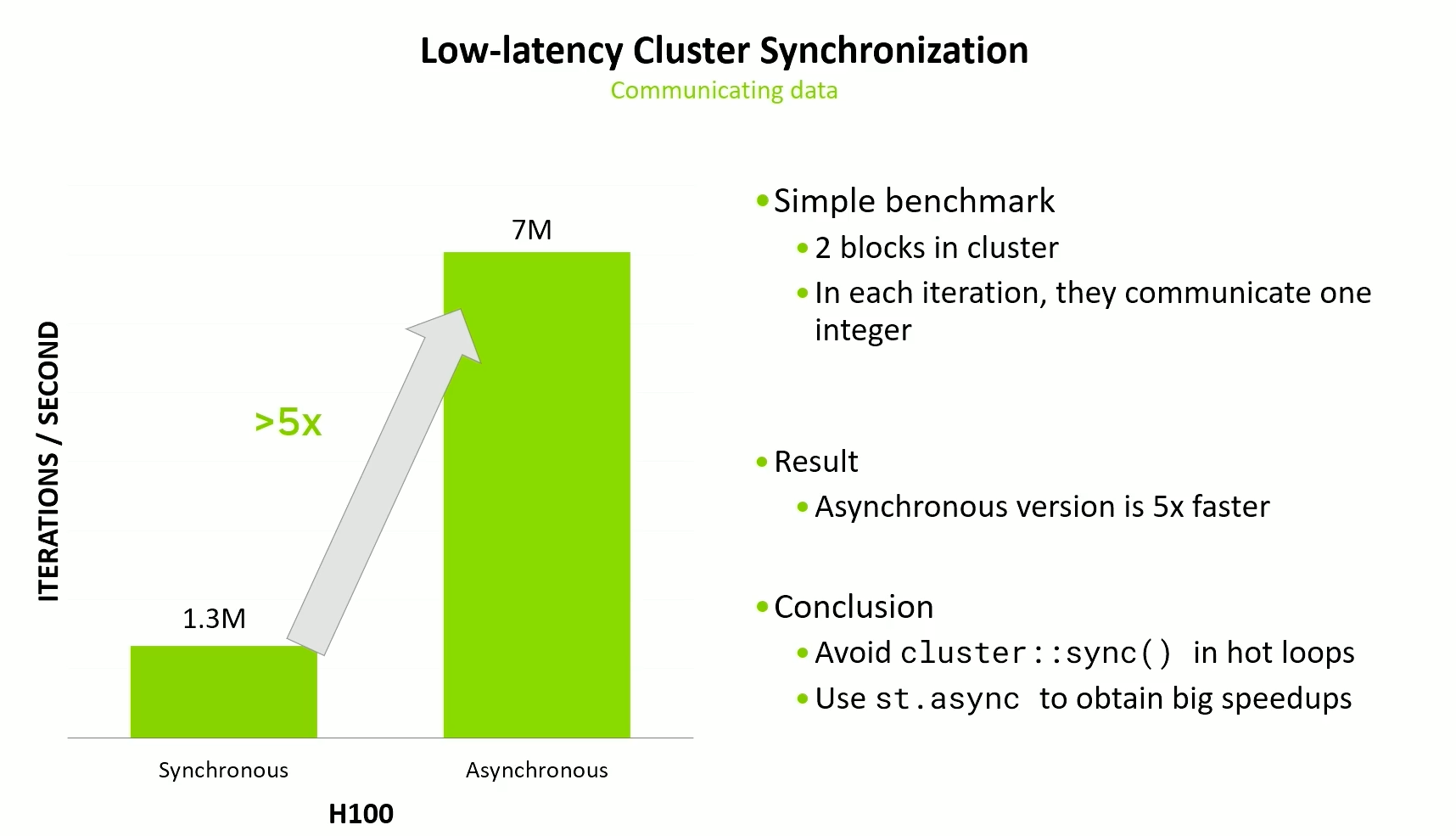
But again, this helps only for short kernels. For long kernels, this won’t help much. We can fo go for the simple code.
Hope this was helpful!
Notes for part 1 on maximizing memory bandwidth can be found here.