Paper Summary #14 - Physics of Language Models: Part 3.1, Knowledge Storage and Extraction

Paper: Arxiv Link
Video: YouTube Link
Annotated Paper: Github repo
Key Questions
- Large Language Models can store knowledge which can be extracted with question-answering.
- Do they answer such questions based on exposure to similar questions during training (i.e. cheating / data contamination)?
- Or, do they genuinely learn to extract knowledge from sources like Wikipedia?
Methodology
- As with the study in Part 2.1 [blog] [paper], the authors use synthetically generated data to avoid the uncontrolled nature of internet data.
- They construct a synthetic dataset of 100k biographies with attributes like birthdate, birth city, and major.
- They also use Llama to rewrite biographies to better match real-world writing styles.
- The key test: after pretraining, can a model be fine-tuned to answer questions like “Where is the birth city of [name]?”
- A fraction \(p\) of individuals appears in QA format (for finetuning), while the remaining \(1-p\) individuals are used as OOD QA evaluation. Biographies for all individuals are used in pretraining.
- Biographies of all individuals were used for the pre-training stage.
Dataset
- BIO dataset \(bioS\)
- N = 100,000 individuals. Each individual’s details are independently sampled.
- Birth dates come from \(200 \times 12 \times 28\) possibilities. Other categories have \(100 \sim 1000\) choices.
- Company city depends on company headquarters.
- Each individual has a six-sentence biography covering six attributes.
- Basic configuration: \(bioS\ single\) (single biography, fixed sentence order).
- Sample biography:
-
Anya Briar Forger was born on October 2, 1996. She spent her early years in Princeton, NJ. She received mentorship and guidance from faculty members at Massachusetts Institute of Technology. She completed her education with a focus on Communications. She had a professional role at Meta Platforms. She was employed in Menlo Park, CA.
-
- BIO dataset \(bioR\)
- Llama-generated biographies in a more realistic style.
- Sample biography:
-
Anya Briar Forger is a renowned social media strategist and community manager. She is currently working as a Marketing Manager at Meta Platforms. She completed her graduation from MIT with a degree in Communications. She was born on 2nd October 1996 in Princeton, NJ and was brought up in the same city. She later moved to Menlo Park in California to be a part of Facebook’s team. She is an avid reader and loves traveling.
-
- QA dataset
- Six questions targeting the six attributes.
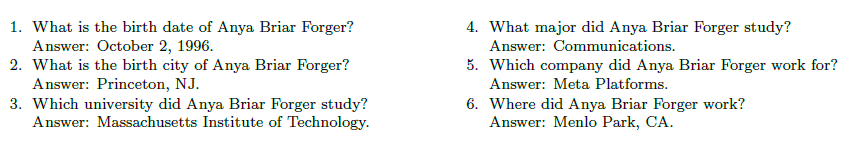
Model
- GPT2 with rotary embeddings (RoPE), still called “GPT2” in the paper.
- 12-layer, 12-head, 768-dim GPT2 (124M) for \(bioS\).
- 12-layer, 20-head, 1280-dim GPT2 (320M) for \(bioR\).
- The context length is 768 / 1024 for pretraining on \(\textrm{iGSM-med}\) / \(\textrm{iGSM-hard}\) and 2048 for evaluation.
- Later experiments also use a BERT-style model (GBERT) - explained in a later section.
Training
- Pretrain + Instruction Finetune
- Pretrain on BIO data (512-token concatenations with standard
<EOS>). - Finetune on half of the QA data; evaluate on the remaining half.
- Pretrain on BIO data (512-token concatenations with standard
- Mixed Training
- Train from scratch on all BIO data + half the QA data.
- BIO and QA entries are sampled independently (not necessarily same individual).
- Evaluate on the remaining QA data.
Key Result - Mixed Training Enables Knowledge Extraction

- The paper uses \(P_{train}\) for QA pairs whose biographies appeared in pretraining, and \(P_{test}\) for those that did not.
- Metrics used:
- BIO first-token accuracy: next-token prediction on the first token of each attribute in BIO data (measures memorization).
- QA first-token accuracy: next-token prediction for the first answer token (proxy for QA performance).
- QA generation accuracy: whole-attribute QA accuracy on \(P_{test}\).
- Main results
- The model first uses QA data to encode knowledge for \(P_{train}\) as QA in-dist accuracy rises quickly.
- This helps memorize in-dist BIO data (BIO in-dist rises next).
- Only later does BIO out-dist accuracy increase, followed by QA out-dist accuracy.
- Interpretation: the model “studies to pass the test,” learning from QA first, then aligning with BIO to generalize.
- Higher QA-to-BIO ratio during training improves out-of-distribution QA accuracy.
Key Result - Model Fails to Extract Knowledge after BIO Pretrain
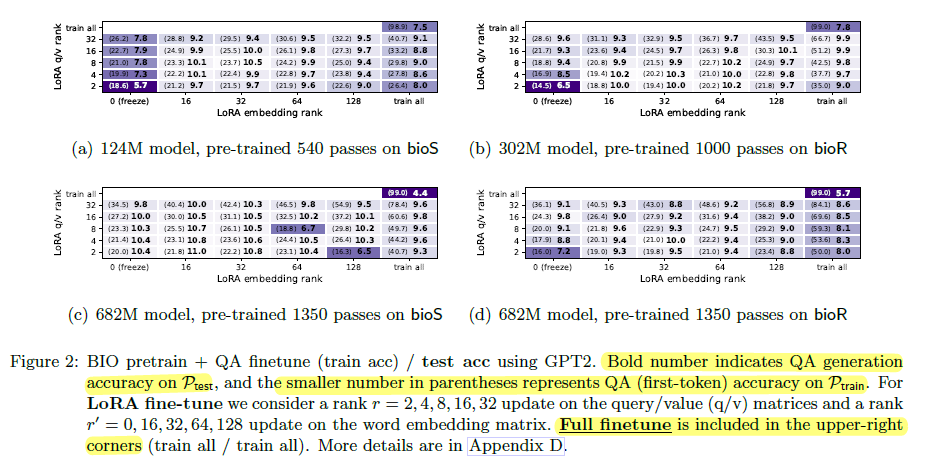
- TL;DR
- Word-by-word memorization of BIO data does not guarantee knowledge extraction.
- Perfect BIO memorization + perfect QA on \(P_{train}\) \(\nRightarrow\) correct QA on \(P_{test}\) (knowledge extraction does not come for free).
- Setup: the model is first pretrained on \(\textrm{bioS}\) or \(\textrm{bioR single}\), then QA-finetuned; the figure reports QA generalization on \(P_{test}\) and (for comparison) QA performance on \(P_{train}\).
- Even with \(99+\%\) BIO first-token accuracy during pretraining (i.e., it can memorize the BIO surface form), QA accuracy on \(P_{test}\) stays near zero across finetuning parameters.
- Full finetuning yields near-perfect in-dist QA on \(P_{train}\) (it can memorize training-set QAs for individuals) but still fails to generalize to QAs about individuals in \(P_{test}\).
- This failure persists even under aggressive scaling/heavy exposure (e.g., model size \(\sim 1000\textrm{x}\) larger than \(N=100k\), each individual seen \(\sim 1350\) times during pretraining) and after exploring many finetuning parameter choices.
- The one partial exception is “birthdate” at ~33% QA generalization, largely because \(\textrm{bioS\ single}\) consistently places birthdate as the first attribute after a person’s name (a positional shortcut); real internet biographies present/repeat facts with variable order and diverse wordings, so other attributes don’t benefit from this crutch.
Key Result - Knowledge Augmentation
- The authors study three augmentations for both \(\textrm{bioS}\) and \(\textrm{bioR}\) (the unaugmented versions are \(\textrm{bioS single}\) and \(\textrm{bioR single}\)):
- \(multiM\): generate \(M\) distinct biography entries per individual using varied templates / wordings. Example:
“Anya Briar Forger came into this world on October 2, 1996. She originated from Princeton, NJ. She pursued advanced coursework at Massachusetts Institute of Technology. She dedicated her studies to Communications. She developed her career at Meta Platforms. She gained work experience in Menlo Park, CA.”
- \(fullname\): replace pronouns with the person’s full name (name repetition). Example:
“Anya Briar Forger originated from Princeton, NJ. Anya Briar Forger dedicated her studies to Communications. Anya Briar Forger gained work experience in Menlo Park, CA. Anya Briar Forger developed her career at Meta Platforms. Anya Briar Forger came into this world on October 2, 1996. Anya Briar Forger pursued advanced coursework at Massachusetts Institute of Technology.”
- \(permute\): shuffle the six attribute sentences randomly. Example:
“Anya Briar Forger originated from Princeton, NJ. She dedicated her studies to Communications. She gained work experience in Menlo Park, CA. She developed her career at Meta Platforms. She came into this world on October 2, 1996. She pursued advanced coursework at Massachusetts Institute of Technology.”
- \(multiM\): generate \(M\) distinct biography entries per individual using varied templates / wordings. Example:

- Main results
- Adding multiplicity, permutations, or fullname repetition improves knowledge storage during pretraining, which makes knowledge extraction via QA finetuning much easier later.
- Notably, \(\textrm{bioS-multi5}\) boosts QA finetune accuracy on \(P_{test}\) from 9.7% to 96.6%.
- More augmentation \(\Rightarrow\) better gains (accuracy tends to increase as multiplicity/permutation counts increase).
- Intuition: exposing the model to varied expressions of the same facts encourages encoding the underlying structure of the knowledge, rather than a single word-by-word surface form.
Key Result - Knowledge Probes on the Pretrained BIO Model
Position-based (P) Probing
- Probes where attributes are encoded in the biography text.
- Uses a frozen model + rank-2 embedding update + linear classifier on last-layer hidden states.
- Special token positions are identified in the biography entries. These positions are immediately before the first occurrences of each attribute.
- There are six such token positions, one for each attribute, leading to 6 × 6 classification tasks.
- Model Modification
- The pretrained network is kept frozen during the probing process.
- A trainable rank-2 update is added to the embedding layer to adapt to the classification tasks.
- Attribute Prediction
- The transformer’s last hidden layer at the identified token positions is used to predict the six target attributes via a linear classifier.
- Evaluation
- The technique assesses how early in the biography the attributes are encoded.
- High accuracy at an early position indicates that the model directly encodes the attribute early in the text.
- Delayed accuracy suggests the model might be relying on less direct, possibly flawed, reasoning.
- If the linear classifier to predict “company name” shows high accuracy right after the person’s full name, it implies that the model is directly learning “Anya’s employer is Meta Platforms”.
- However, if high accuracy is only achieved at the biography’s end, the model might be using a flawed logic, such as “the birthday is October 2, 1996, the university is MIT, hence the employer is Meta.”

- Main results
- In \(bioS\ single\), accuracy is low until the token right before the attribute (suggesting weak early storage).
- In \(bioS-multi5 + permute\), all six attributes are predicted with near-100% accuracy from the earliest special position.
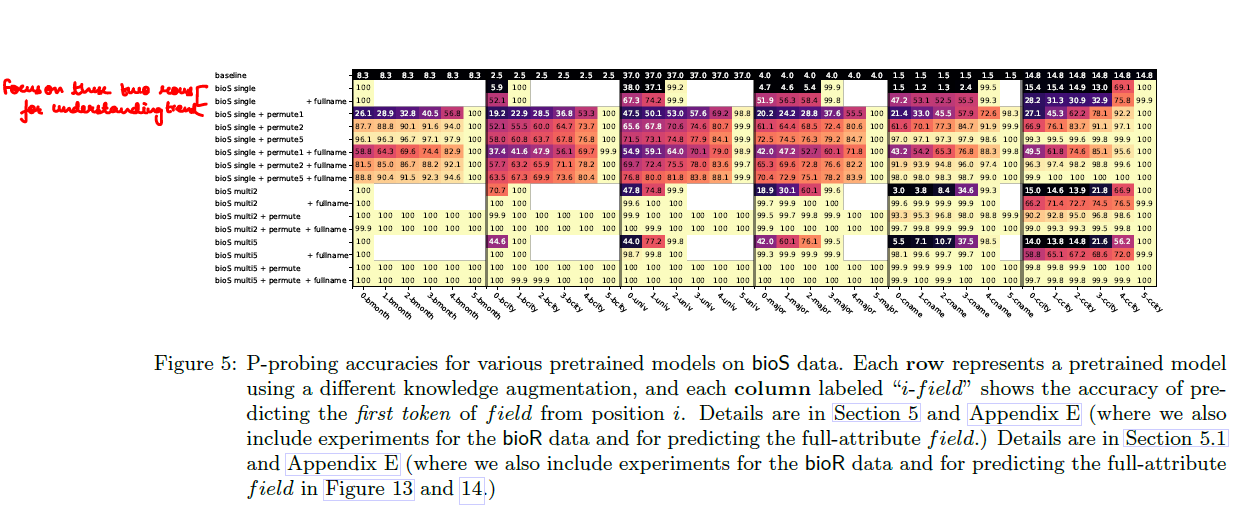
- Takeaway
- Increased knowledge augmentation in the pretrain data improves P-probing accuracies at earlier token positions.
- Consequently, a key-value pair knowledge (e.g., person-employer) more directly associates the value with the key rather than with other related attributes.
- This mechanism facilitates the (out-of-distribution) extraction of knowledge through fine-tuning.
Query-based (Q) Probing
- Q-Probing aims to obtain a precise, context-free assessment of how well a pretrained model associates specific attributes with a person’s name.
- Limitation of P-Probing:
- P-Probing depends on the exact context and structure of the original biography entry, which may limit its effectiveness.
- For example, knowledge might be embedded in specific phrases, making it challenging to assess early knowledge storage accurately.
- Sentences containing only the person’s full name, surrounded by a starting token and an ending token, are fed into the model.
- A linear classifier is trained on the hidden states of the last layer to predict six target attributes associated with the person.
- Model Modification
- Similar to P-Probing, all transformer layers acquired through pretraining are kept frozen.
- A low-rank update is applied to the embedding layer, using rank 16 (compared to rank 2 in P-Probing), to adjust for the different classification task and input distribution.
- Attribute Prediction
- The hidden states from the last layer at the ending token are extracted and used by a trainable linear classifier to predict the person’s six attributes.
- Evaluation
- High accuracy in this context-free setup indicates that the model directly associates the person’s name with their attributes.
- This method provides a more focused analysis of the knowledge directly tied to the name, independent of the broader context found in full biography entries.

- Main results
- Q-probing accuracy increases strongly with augmentation.
- QA finetune accuracy correlates closely with Q-probing.
- If knowledge isn’t stored near-linearly next to the name during pretraining, QA finetuning won’t fix it.
- The results also suggest that at the last hidden-layer, the model neither uses complex or nonlinear transformations nor leverages interactions between hidden states at different token positions to extract knowledge about the person.
Key Results - Celebrity Can Help Minority

- Augmenting only a “celebrity” subset still improves minority QA accuracy.
-
The non-augmented subset is comparable to a “minority” group with limited biographical data.
- Main results
- \(bioS\) minority QA accuracy: 4.4% → 86.8% with celebrity data.
- \(bioR\) minority QA accuracy: 10% → 76.3% with celebrity data.
- This holds even though the minority BIO data is unchanged and their QA data is not used in finetuning.
Key Result - Knowledge Storage for Bidirectional Models (GBERT)
- GPT2 is modified to a BERT-like architecture (full attention matrix) with whole-word MLM pretraining, keeping the GPT2 tokenizer and rotary embedding. They call this model “GBERT”.
- Instead of tokens, whole-word masked language modeling.
- Each English whole word has a 15% chance of being selected, which is then replaced with a
<MASK>token (80% chance) or retained (10% chance), or replaced with a random token (10%). - The goal is to predict the original word for these selected tokens.
- QA is evaluated by appending
<MASK>tokens for the answer length and requiring exact recovery.

- Main results
- QA finetune and Q-probing accuracies still correlate strongly.
- This suggests that the ability to extract knowledge from a BERT-like model also depends on whether such information is nearly linearly stored in hidden states directly adjacent to the person’s name.
- Mixed training slightly outperforms BIO pretrain + QA finetune.
- Model does well on attributes like “birth date” and “major”, but struggles on others.
- QA finetune and Q-probing accuracies still correlate strongly.
- Simple reasoning: MLM learns to associate masked words with the closest related unmasked words.
- Birth date tokens (month/day/year) are relatively independent, so they link to the name.
- Birth city often links to state, preventing strong name association.
- Conclusion: MLM pretraining does not reliably promote knowledge storage for later extraction unless the knowledge is a standalone word or a set of independent words.
- Unless the knowledge is a standalone word or of independent words (like month, day, year), extracting knowledge after MLM pretraining might prove challenging, if not totally impossible.