Paper Summary #17 - Engram
Paper: Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
Official implementation: DeepSeek-AI/Engram
Self-attention links tokens inside the current sequence and carries global context forward.
Experts increase transformation capacity while activating only a few FFNs per token.
Hashed n-grams retrieve static vectors, then the hidden state decides whether to inject them.
Attention is not memory
Self-attention can resolve relationships in a sentence. It does not automatically provide a grounded representation of what the entities actually are.

In a standard Transformer, this grounding is reconstructed through repeated computation. Attention composes nearby tokens. Feed-forward layers transform features. Later layers gradually turn surface strings into semantic representations.
The Engram paper frames this as an architectural mismatch: dynamic reasoning should use computation, while common static phrases should often use lookup.
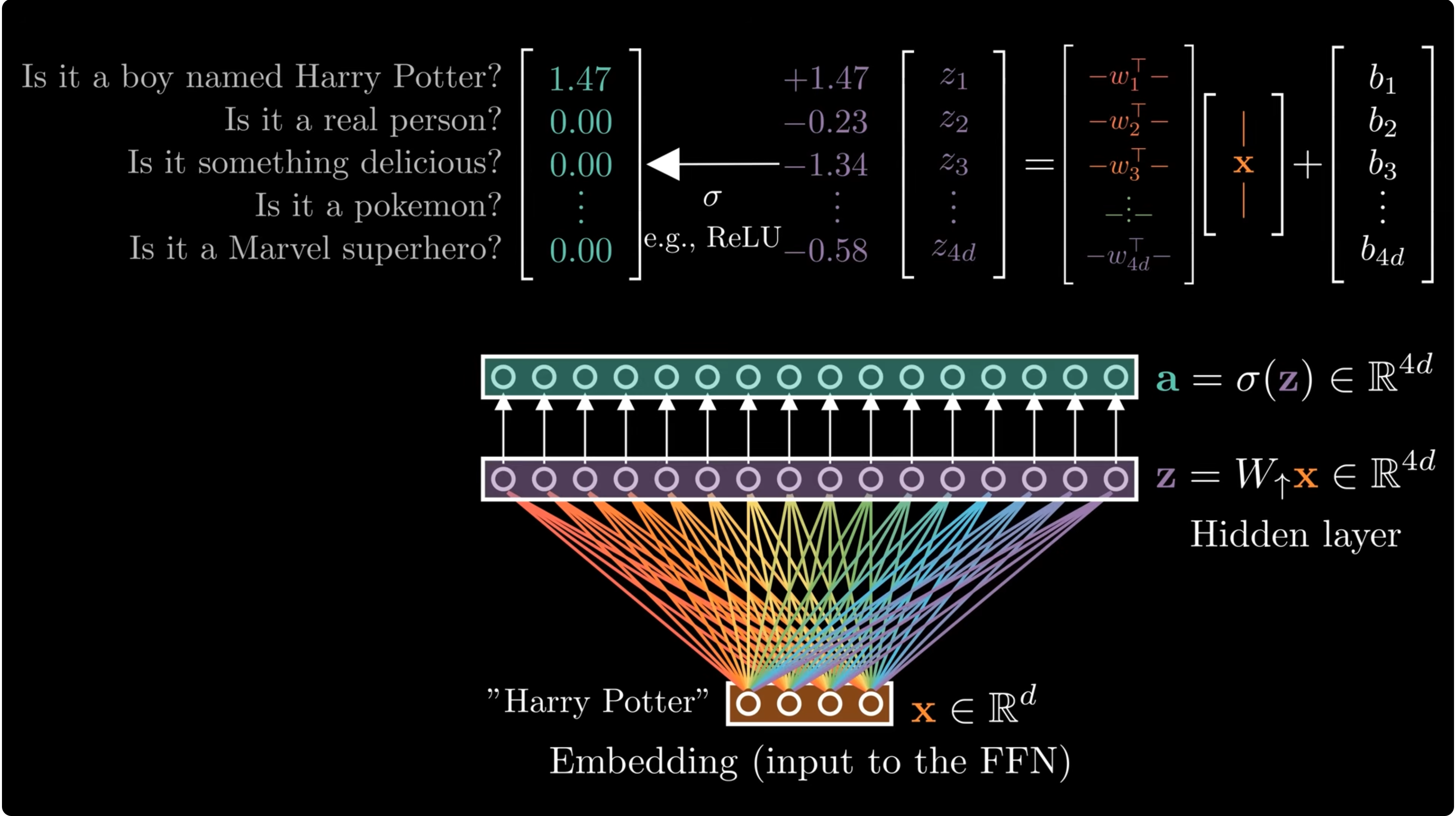
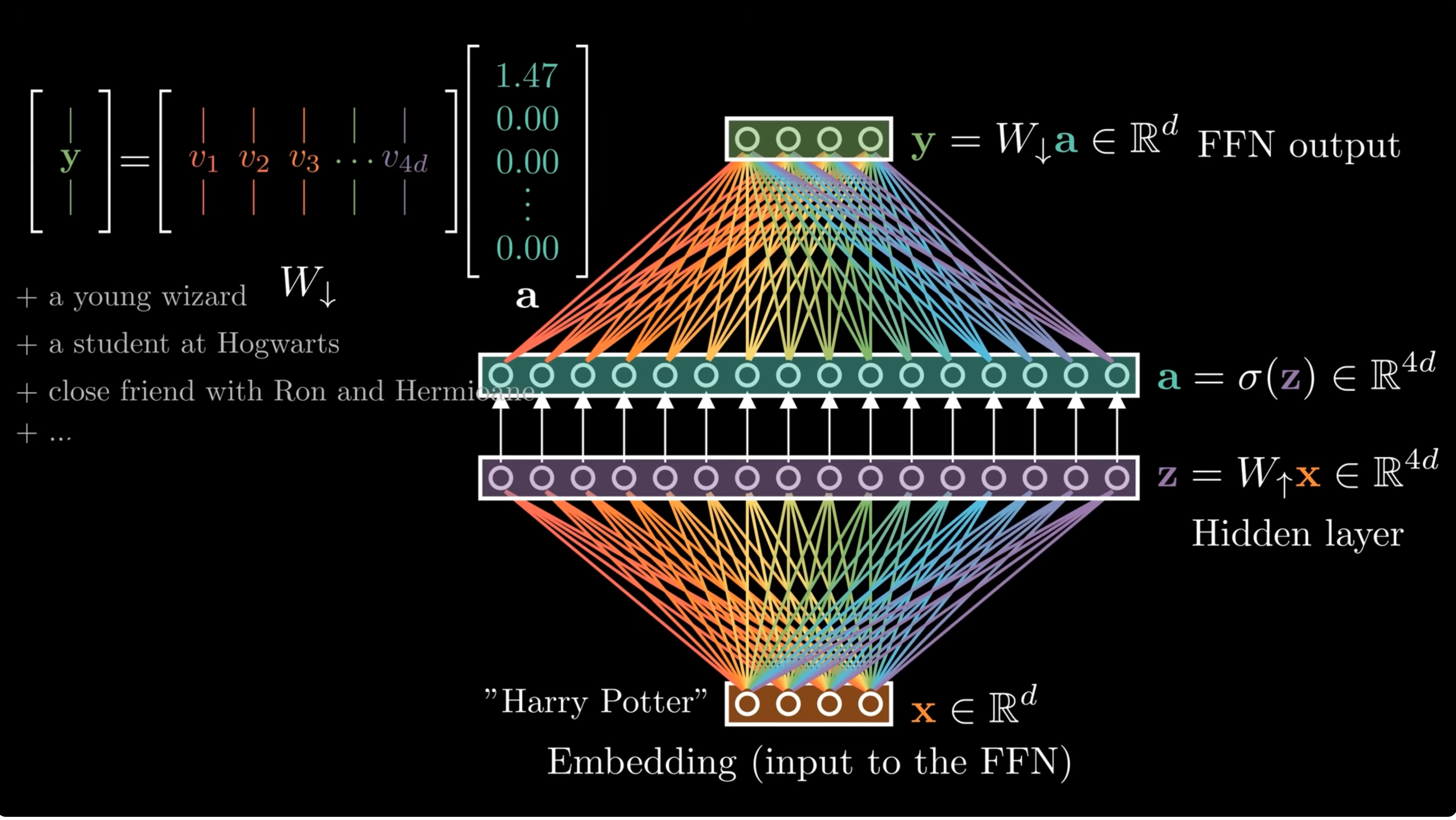
The FFN already looks like a memory
A Transformer MLP can be read as a bank of pattern detectors and value writers.
Geva et al. showed that FFNs behave like key-value memories: rows of $W_{\text{up}}$ detect patterns, while columns of $W_{\text{down}}$ write value vectors into the residual stream.
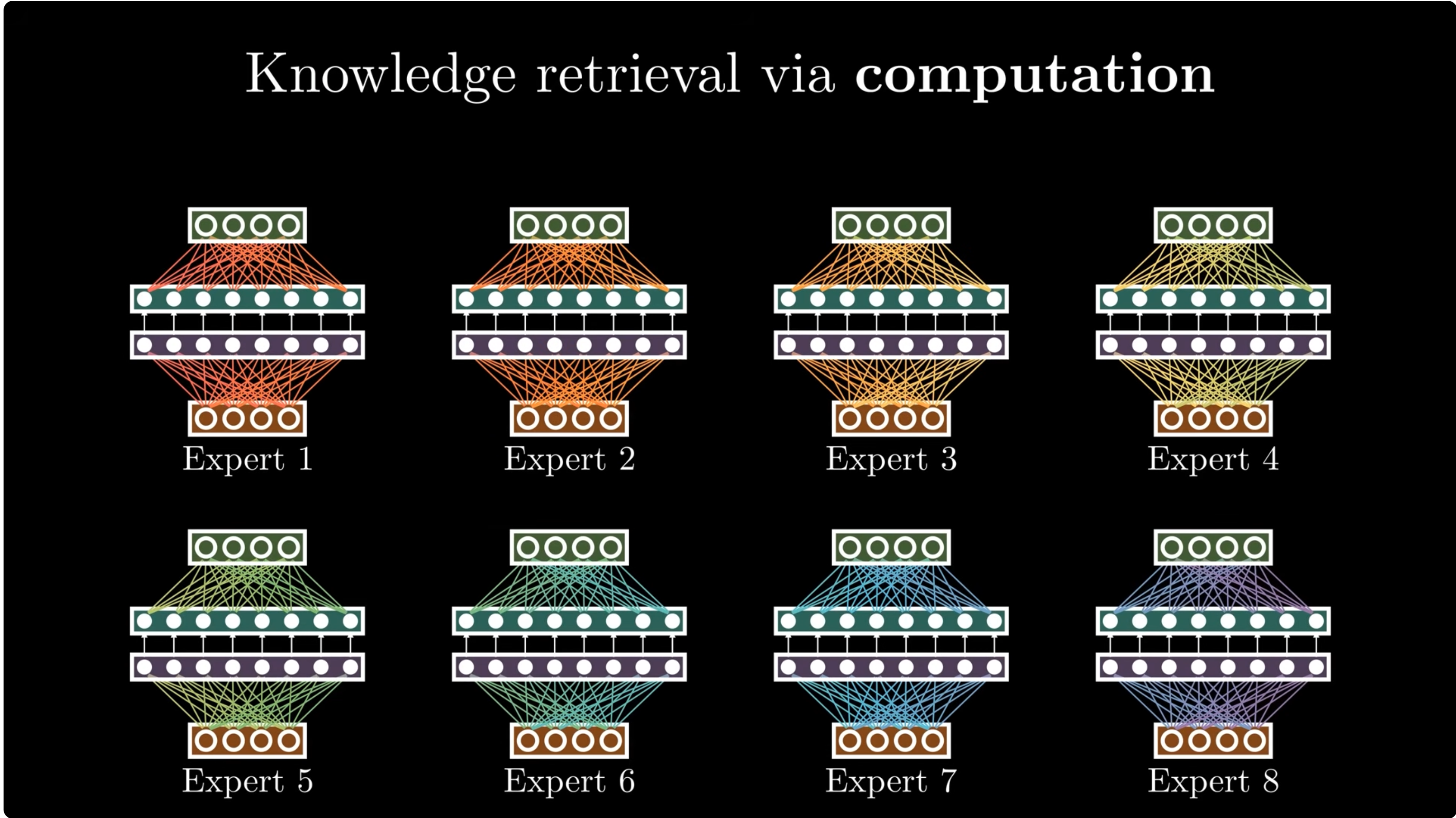
MoE scales this by adding many FFNs and routing each token to a few experts:
Static facts want tables
For a single token, lookup is simple. For phrases, the combinatorics explode.
A token embedding table maps an ID directly to a vector:
But facts are usually phrase-level. "Harry" is ambiguous; "Harry Potter" is a much more specific key.
A direct bigram table with $|V|=128{,}000$ would have:
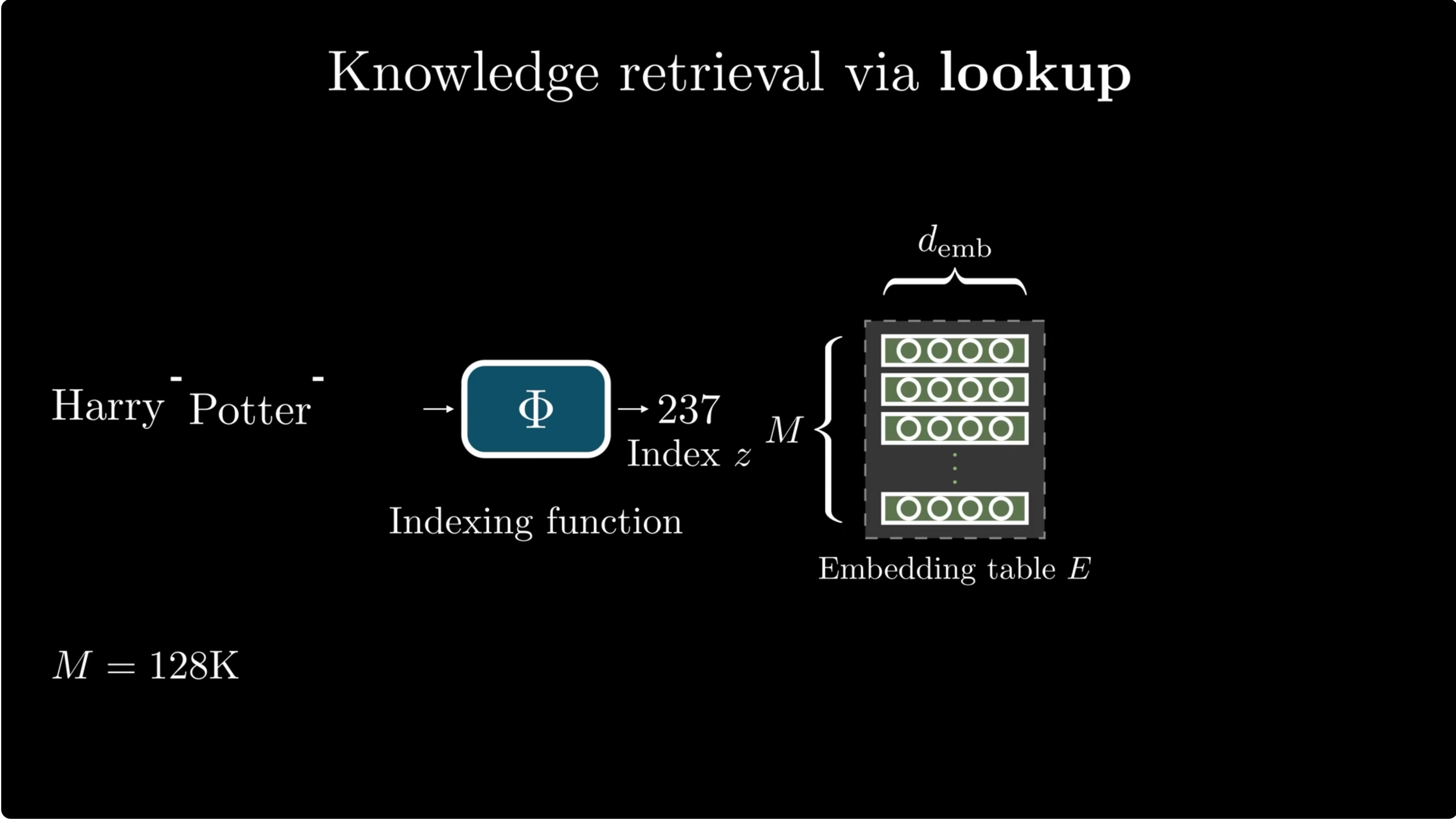
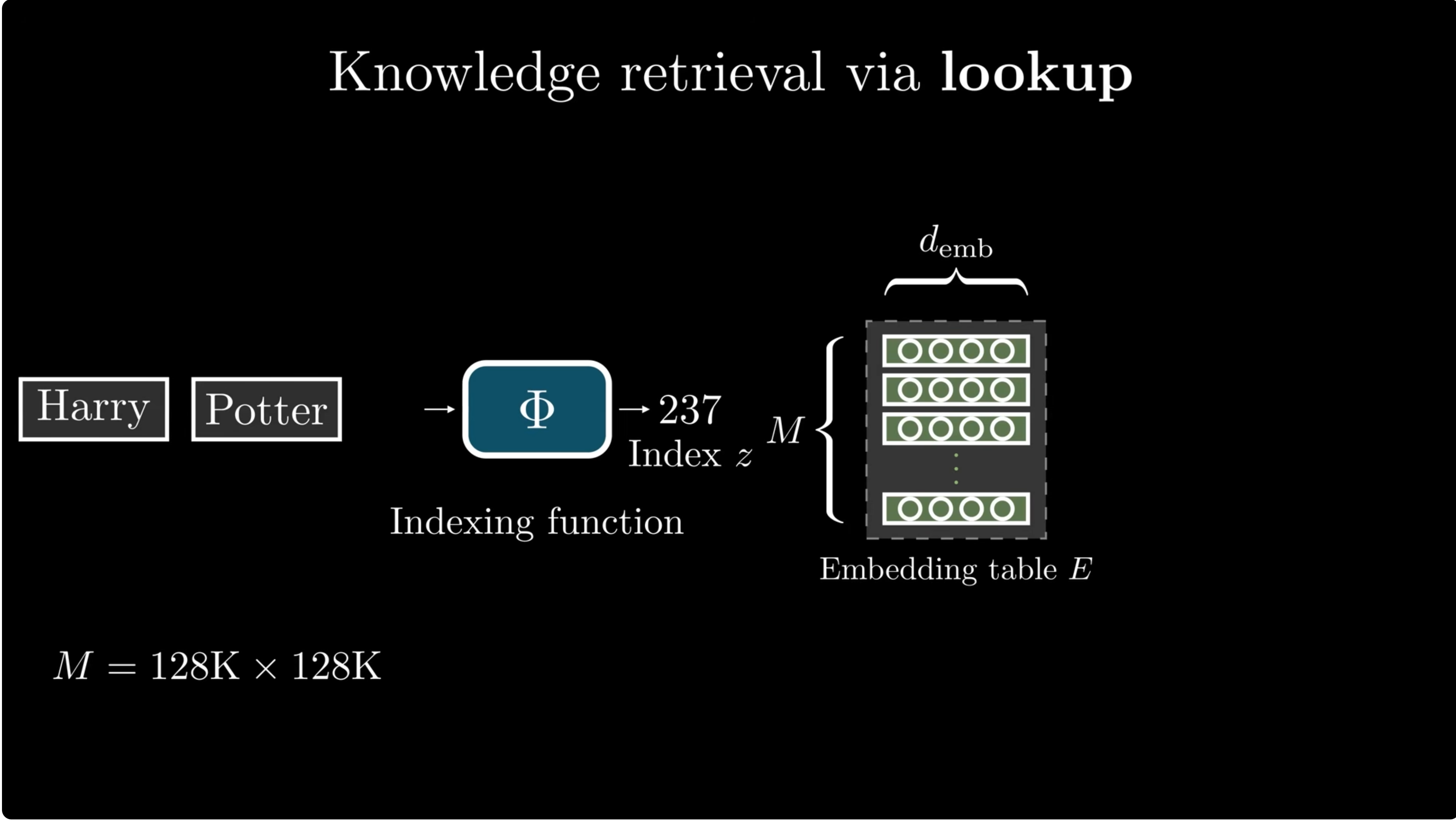
Hash the local phrase
Engram compresses token IDs, hashes suffix n-grams, and retrieves rows from multiple embedding tables.
First, a tokenizer projection maps raw token IDs into canonical IDs:
Then Engram forms suffix n-grams:
Each hash head maps the compressed n-gram into a table row:
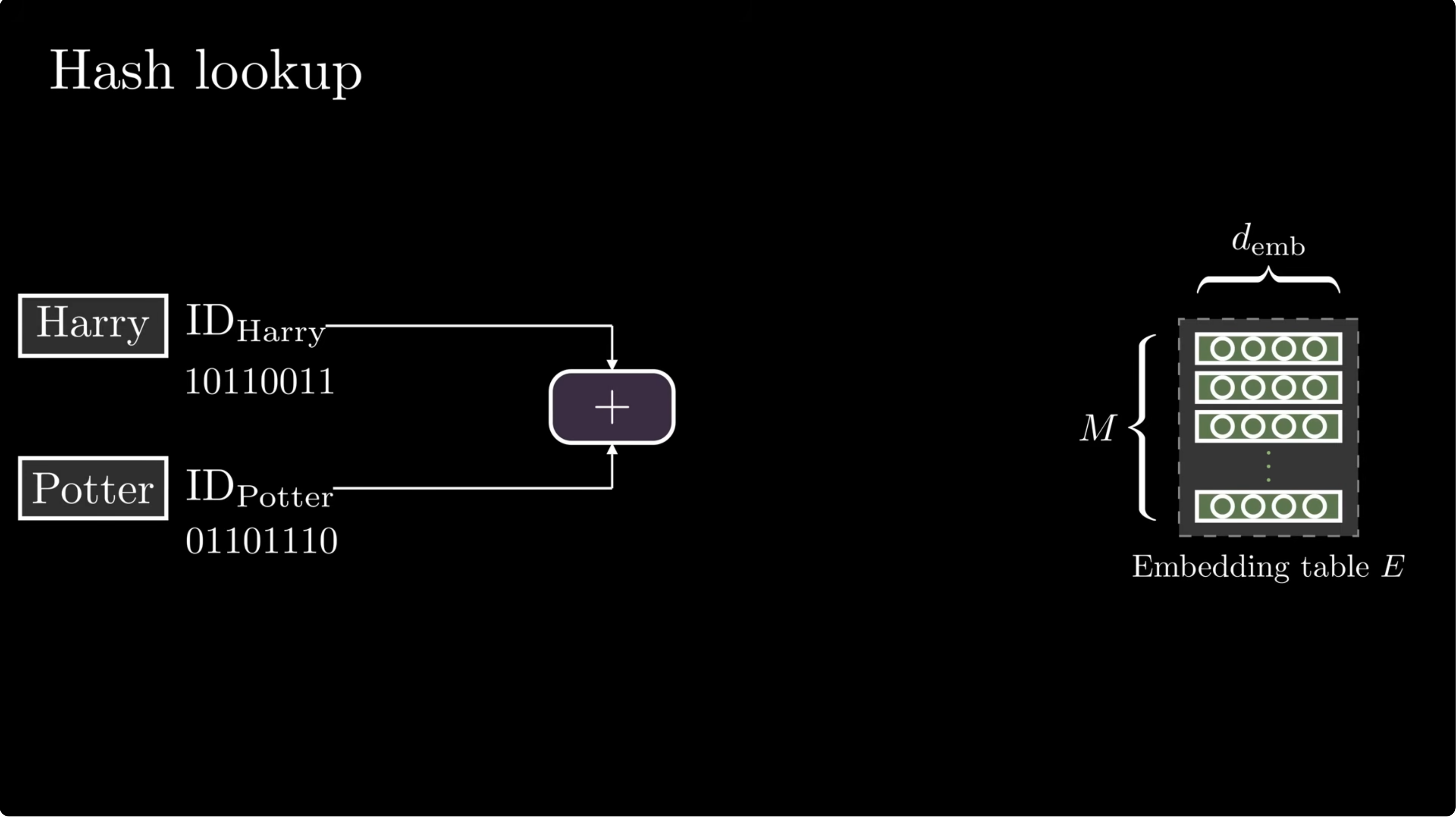
Why multiplicative-XOR?
Addition creates structured collisions and loses order. Plain XOR also loses order because it is commutative. Engram uses position-specific multipliers before XOR:
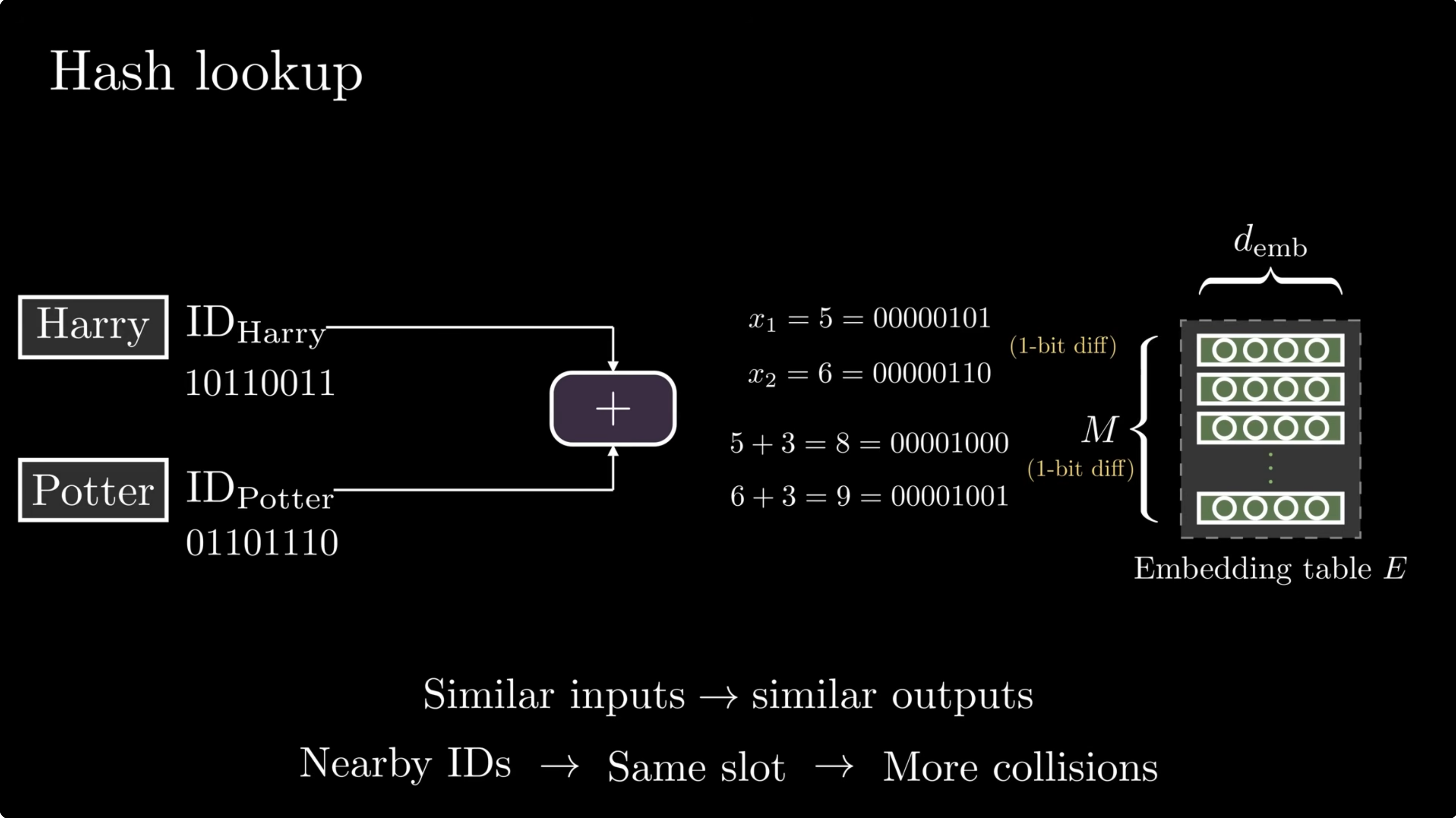
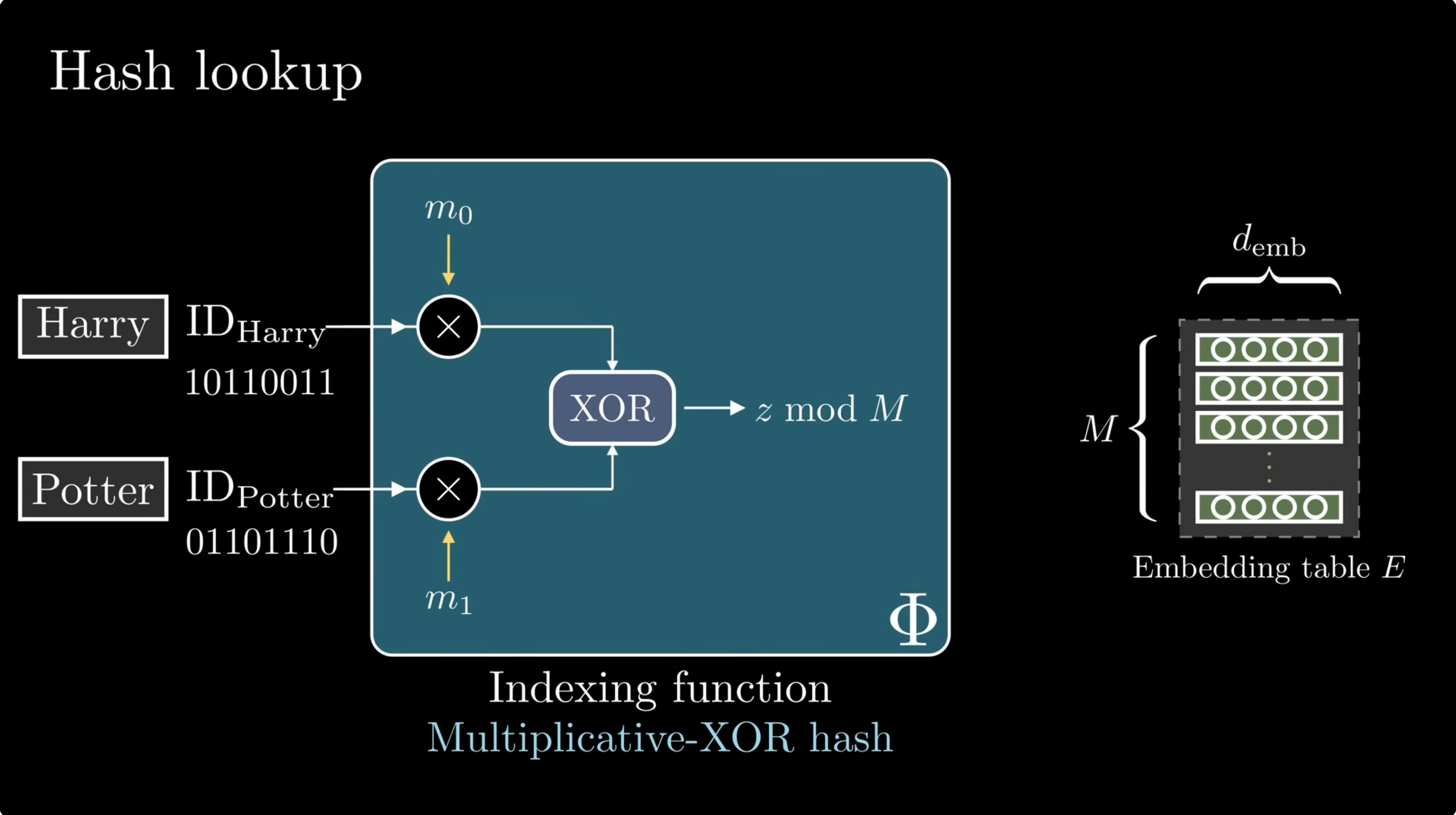
A small hash lab
This toy demo is not DeepSeek's implementation. It makes the design intuition visible: one phrase produces several independent table addresses.
Multi-head lookup
Choose a phrase and watch eight simulated heads map it to different slots. Multi-head hashing makes a total collision across all heads much less likely.
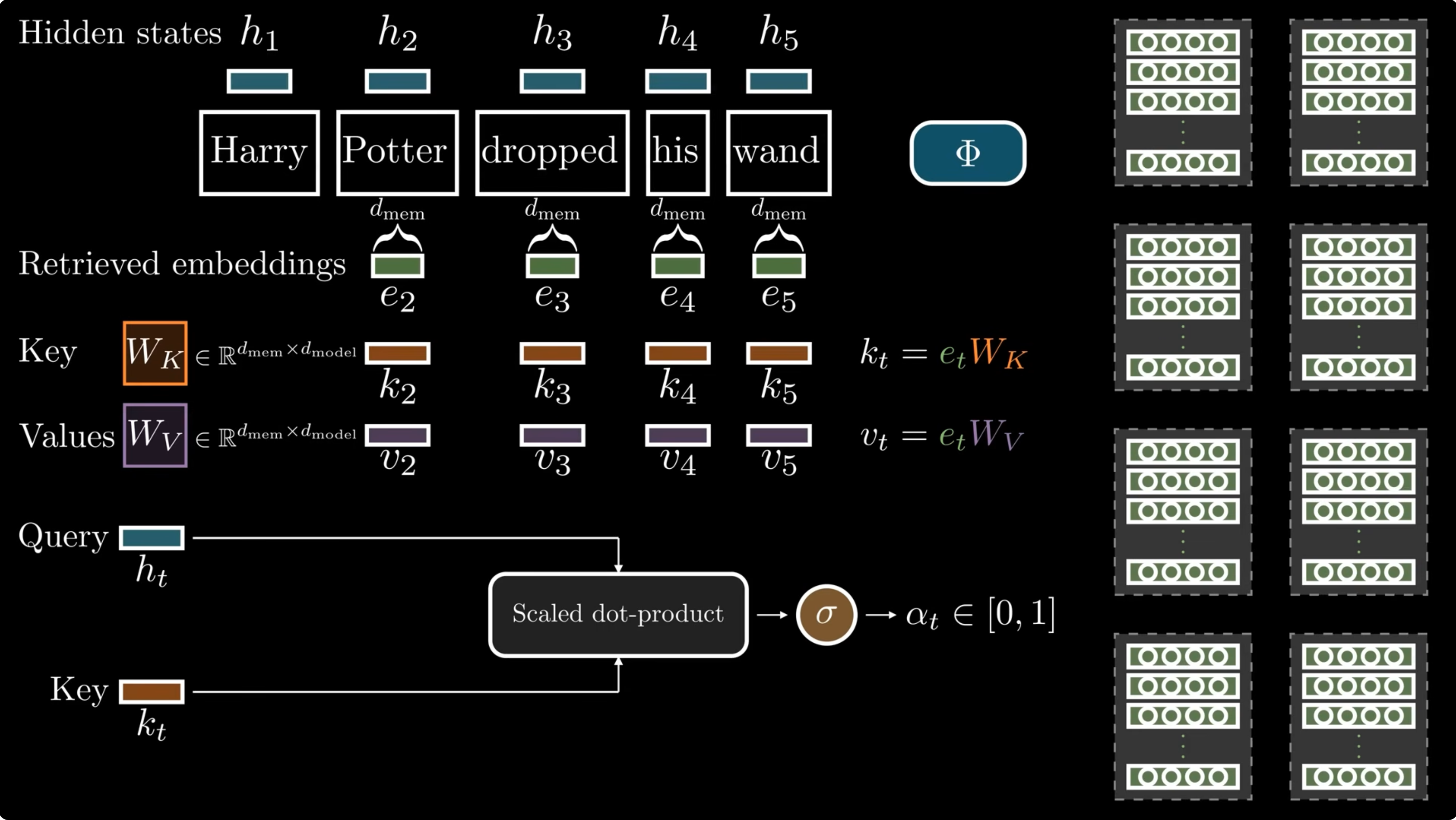
Lookup needs a gate
Static memory is useful only when the current context agrees with it.
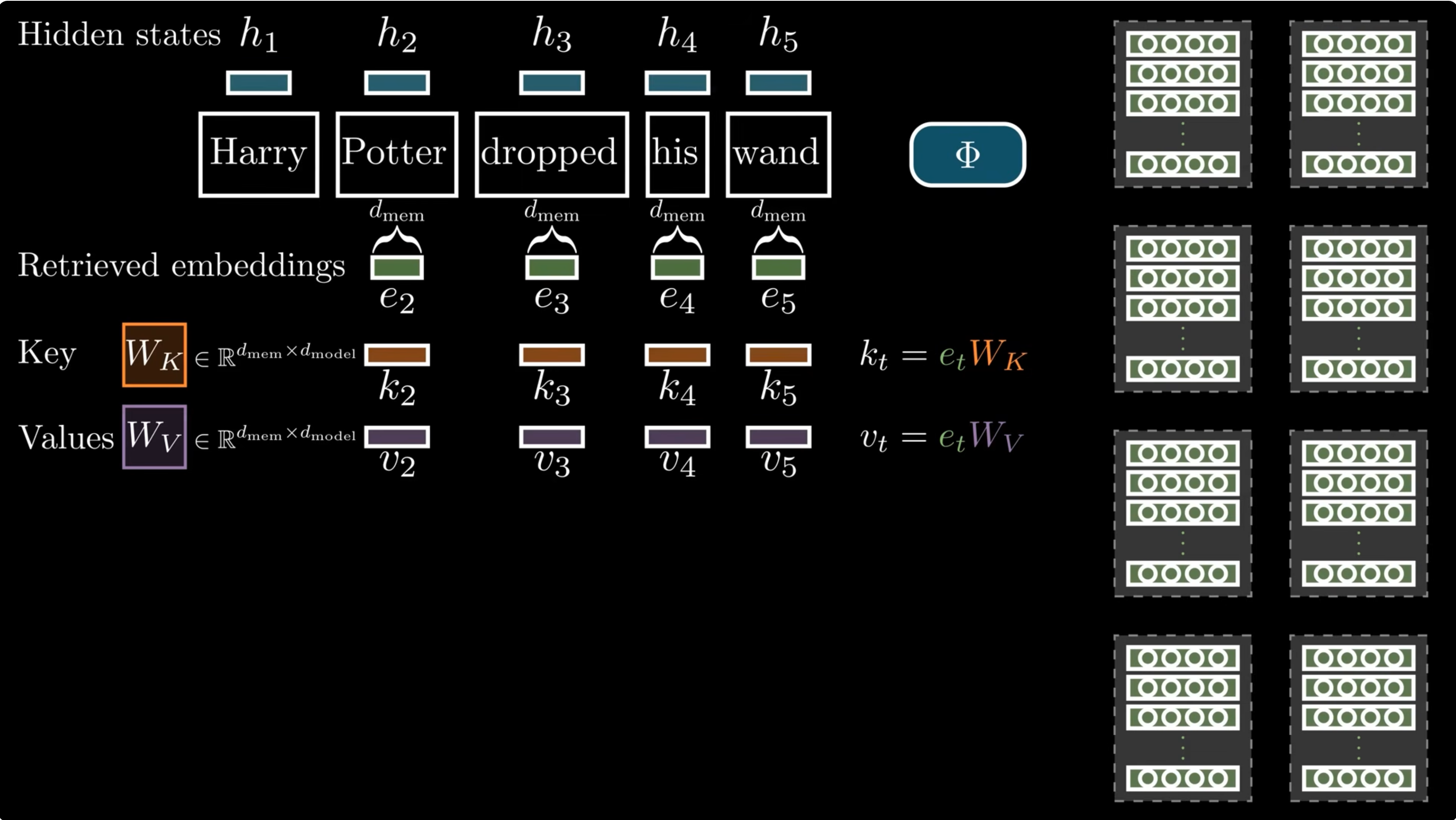
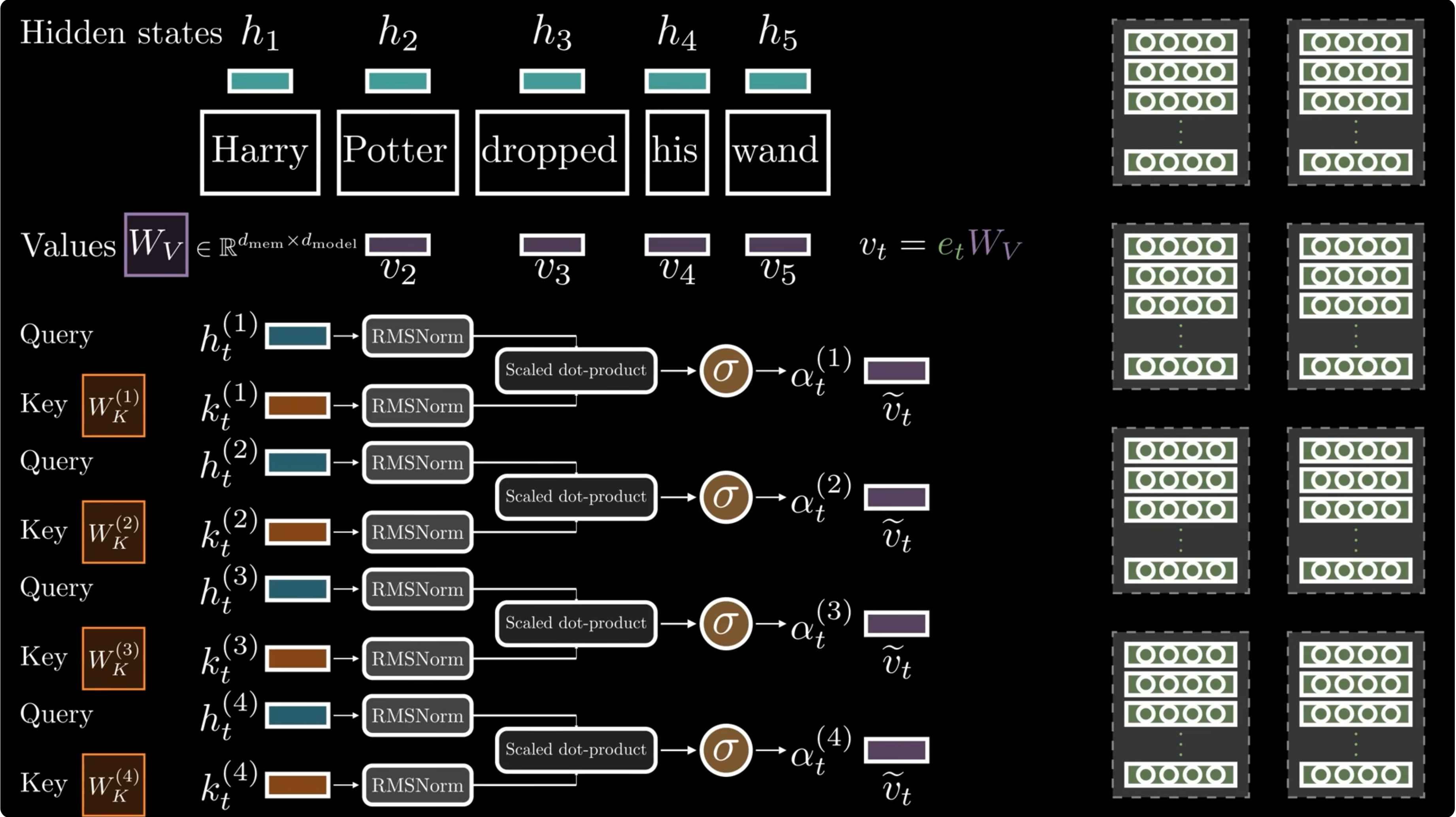
The retrieved vector $e_t$ is projected into a key and value:
The hidden state is the query. The scalar gate is:
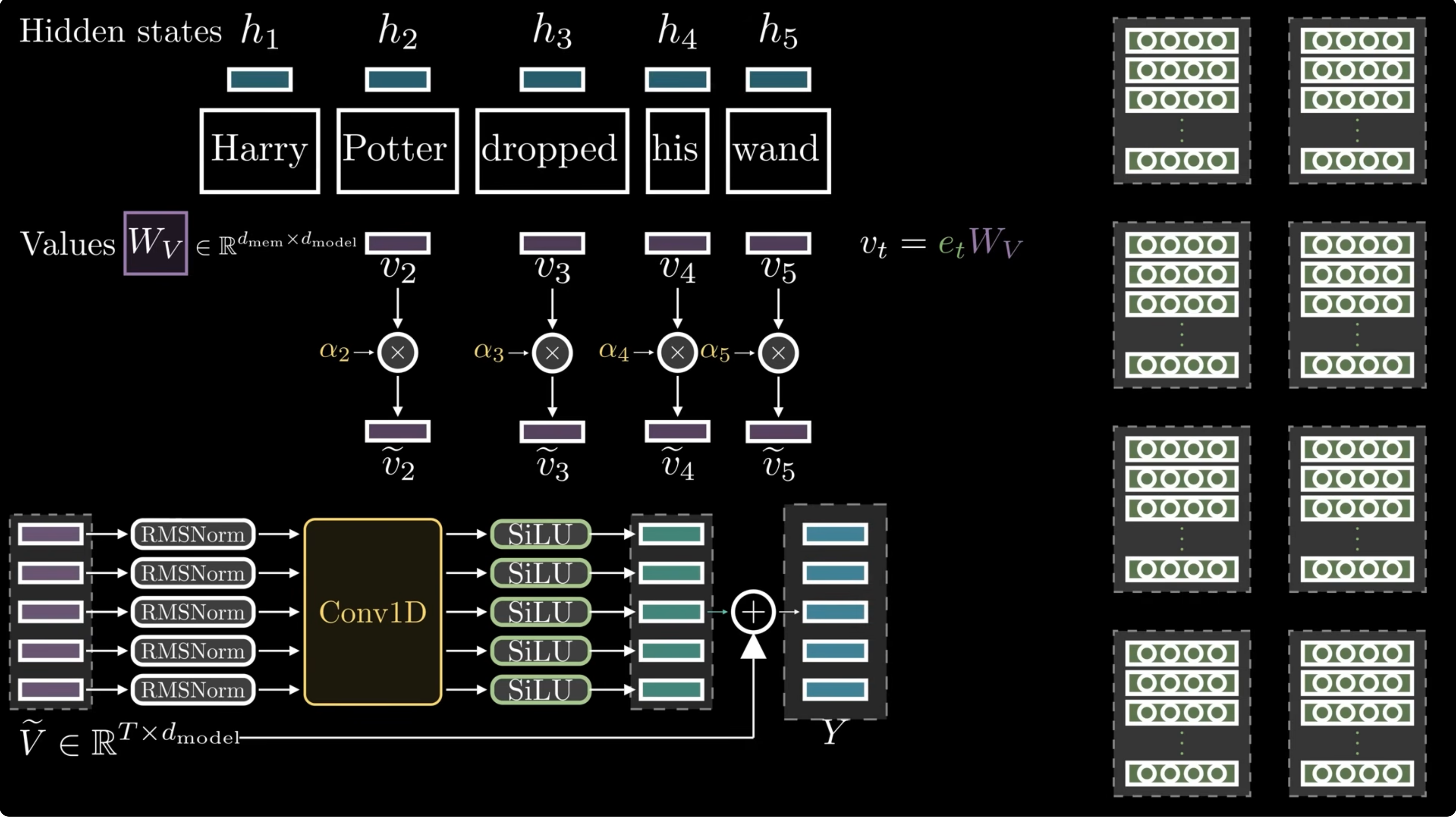
Short convolution
After gating, Engram applies a short depthwise causal convolution and a residual path:
Inside the Transformer, not just at the input
Engram is inserted into selected Transformer blocks. The paper's 27B model uses layers 2 and 15.
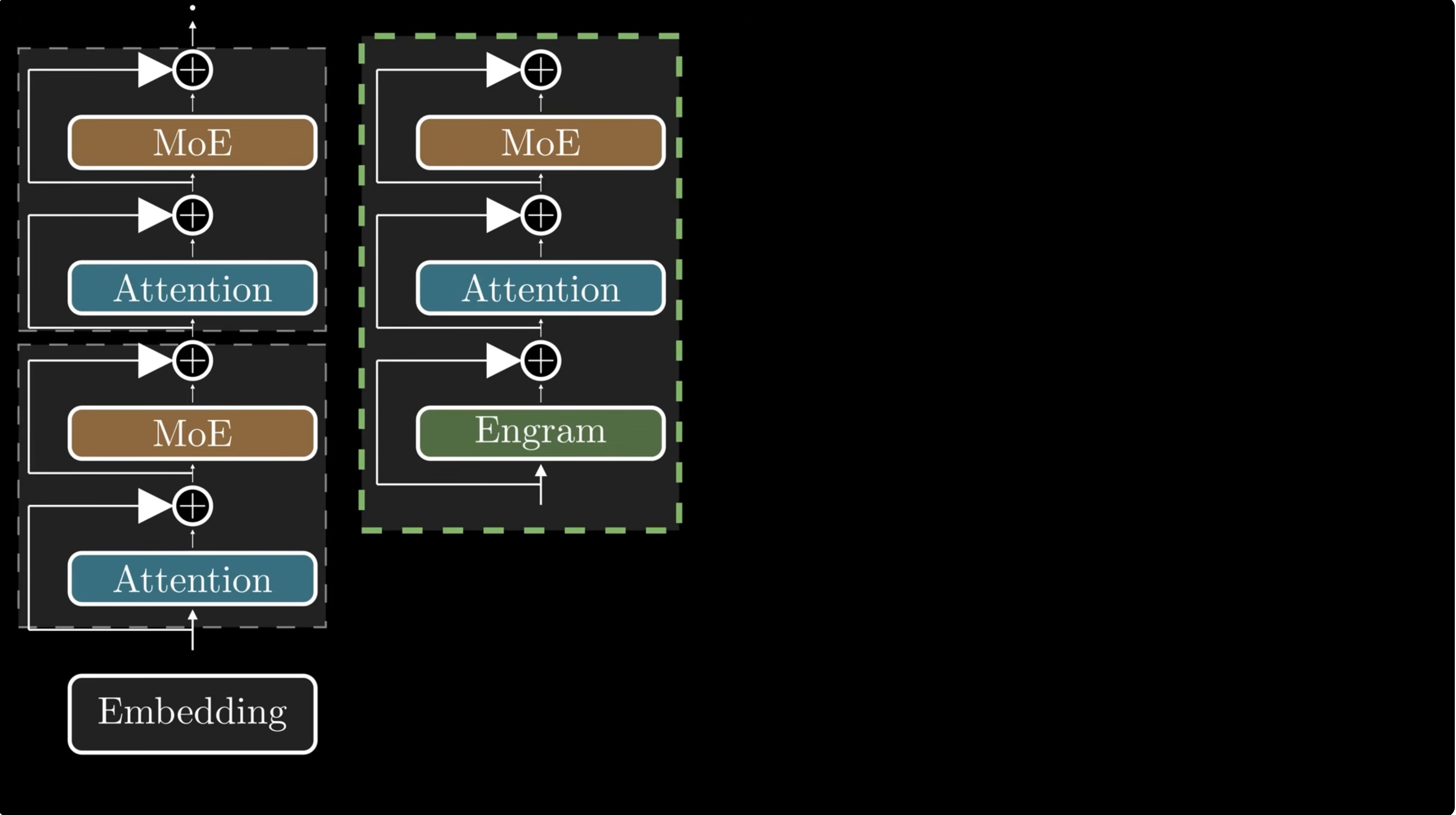
The hidden state is still close to token embeddings, so context-aware gating has little context to use.
One round of attention is enough to make the gate useful while still being early enough to save depth.
A later Engram module catches associations that only become clear after partial processing.
For multi-branch mHC backbones, Engram shares the memory table and value projection, but uses branch-specific key projections:
How much memory is enough?
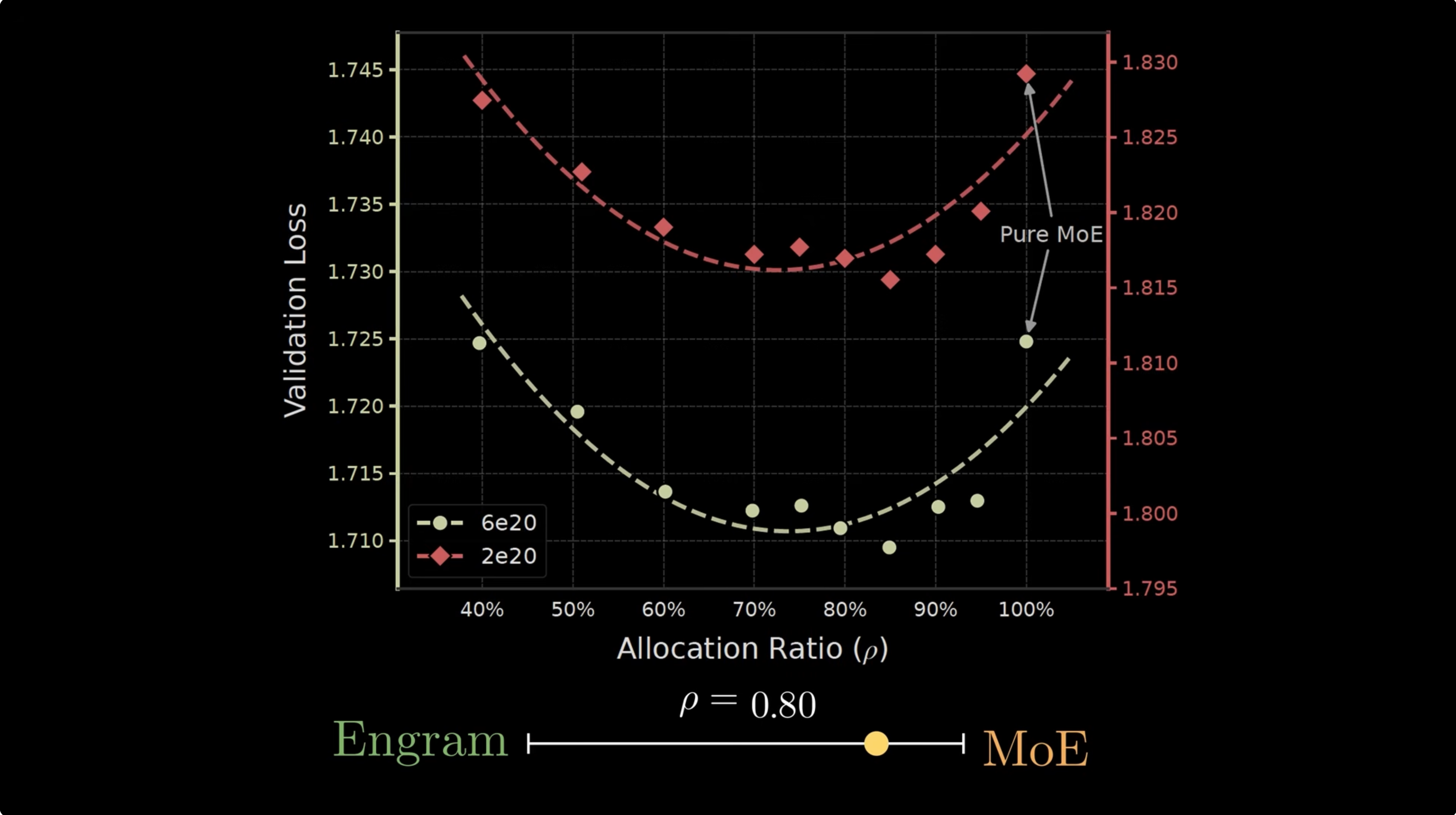
Engram's strongest empirical claim is that sparse capacity should be split between MoE and memory.
Sparsity allocation
Move the slider. The paper's optimum appears around $\rho \approx 0.75$ to $0.80$, where most sparse capacity remains MoE but a meaningful chunk becomes Engram memory.
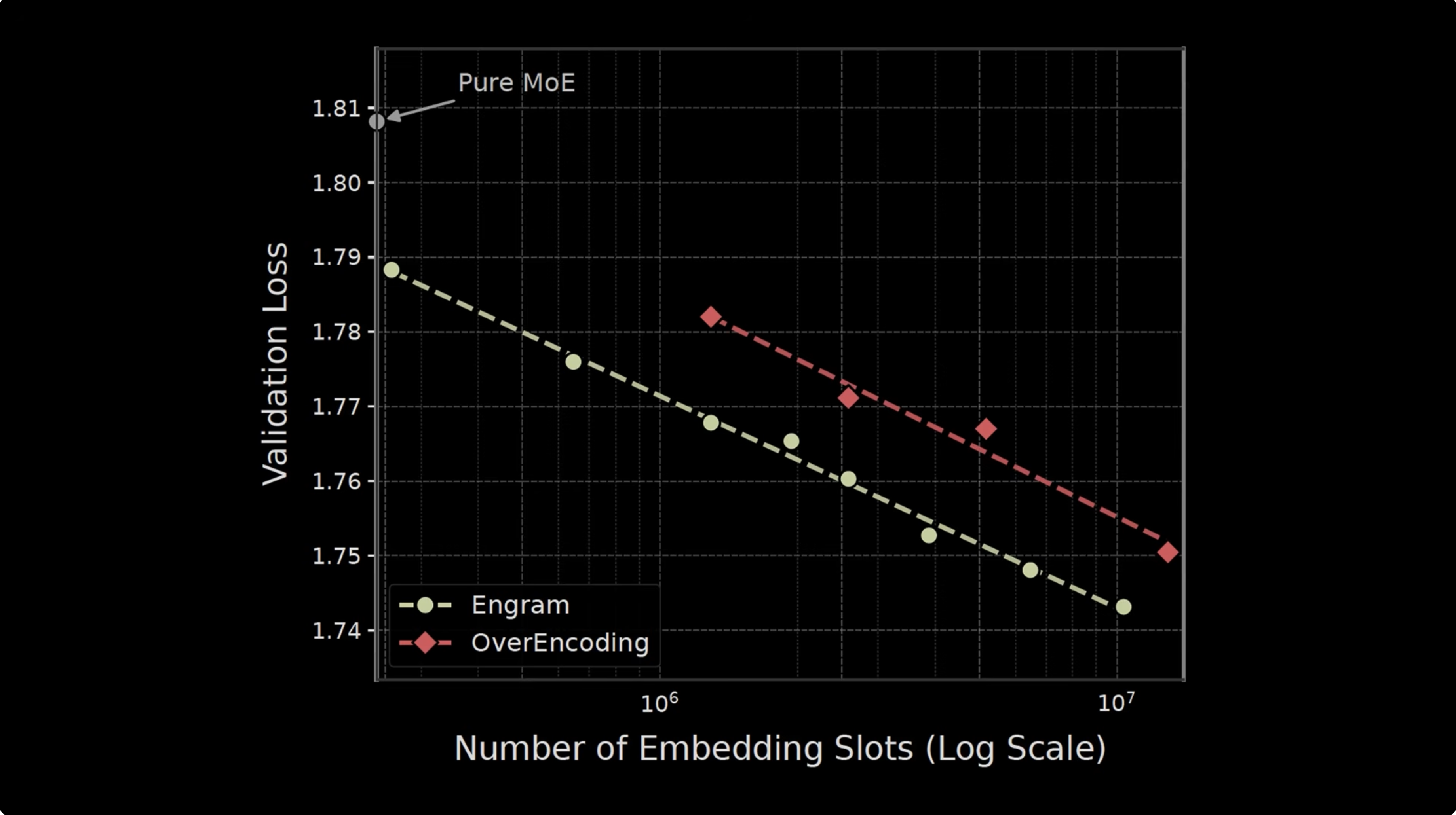
What changes at scale?
Engram-27B is iso-parameter and iso-FLOPs relative to MoE-27B. The win comes from reallocating sparse capacity, not from spending more activated compute.
| Model | Total params | Activated params | Experts | Engram params |
|---|---|---|---|---|
| Dense-4B | 4.1B | 3.8B | none | none |
| MoE-27B | 26.7B | 3.8B | 2 shared + 72 routed, top-6 | none |
| Engram-27B | 26.7B | 3.8B | 2 shared + 55 routed, top-6 | 5.7B |
| Engram-40B | 39.5B | 3.8B | 2 shared + 55 routed, top-6 | 18.5B |

Effective depth
Engram helps shallow layers behave like deeper MoE layers because static local reconstruction is handled by lookup.
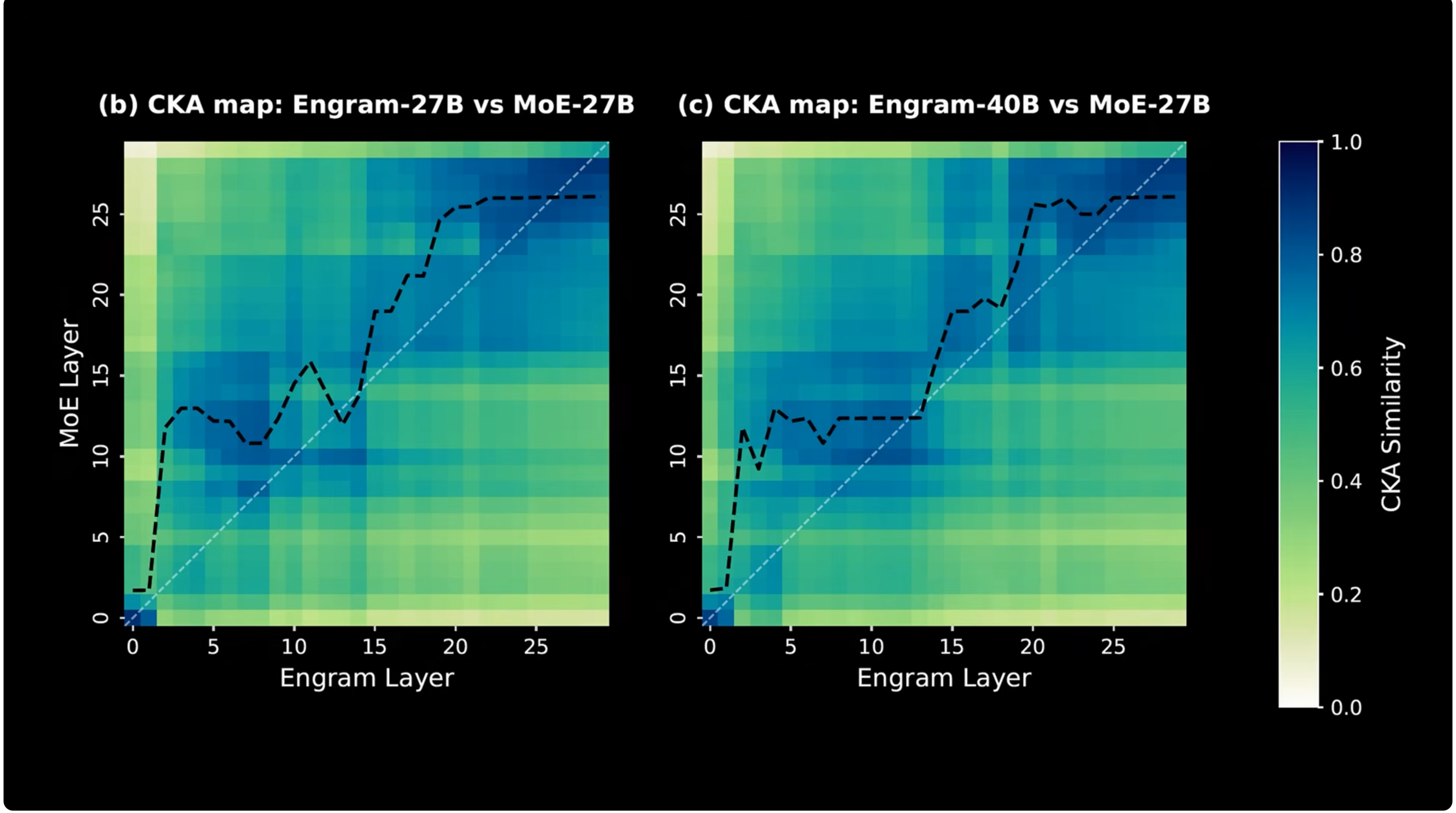
Lookup frees attention
The paper argues that once local stereotyped patterns are handled by memory, attention can spend more of its capacity on global context.
| Model | Multi-Query NIAH | Variable Tracking |
|---|---|---|
| MoE-27B, 50k pretrain steps | 84.2 | 77.0 |
| Engram-27B, 46k steps, matched loss | 97.0 | 87.2 |
This does not mean Engram directly performs long-context retrieval. It means early representations are cleaner and attention has less local reconstruction work to do.
Why CPU offload can work
MoE routing depends on hidden states. Engram indices depend only on token IDs.
Because Engram addresses are known before the layer executes, rows can be prefetched from host memory while earlier GPU layers are still computing.
The active communication volume scales with retrieved rows, not total table size:
The paper reports less than 3 percent throughput penalty when offloading a 100B-parameter Engram layer to host DRAM in their nano-vLLM-based setup.
Implementation path
The official repository ships a demo that focuses on data flow rather than production kernels.
The useful way to read the demo is as a call graph. Engram is inserted inside selected Transformer blocks before the ordinary attention and MoE sublayers. The block still receives the full token IDs because the memory address is computed from tokens, not hidden states.
class TransformerBlock(nn.Module):
def forward(self, input_ids, hidden_states):
if self.engram is not None:
hidden_states = (
self.engram(hidden_states=hidden_states, input_ids=input_ids)
+ hidden_states
)
hidden_states = self.attn(hidden_states) + hidden_states
hidden_states = self.moe(hidden_states) + hidden_states
return hidden_states
So the lookup path is not a sidecar after decoding. It is a residual branch inside the model's forward pass. For configured layers such as 1 and 15 in the demo, the sequence is:
| Step | Code object | Role |
|---|---|---|
| Compress | CompressedTokenizer | Normalize equivalent token strings and map original token IDs to a smaller canonical ID space. |
| Index | NgramHashMapping.hash | Call the n-gram hash routine for every Engram layer and return layer-specific row IDs. |
| Gather | MultiHeadEmbedding | Use offsets so many head-specific tables can live inside one contiguous embedding table. |
| Fuse | Engram.forward | Project retrieved rows into keys and values, gate with the hidden state, apply short convolution, and return a residual update. |
Tokenizer compression
The demo builds an array mapping each original token ID to a normalized canonical ID. The normalizer applies Unicode normalization, accent stripping, lowercasing, whitespace cleanup, and a fallback for undecodable tokens. This matters because many surface forms should share lookup rows.
old2new = {}
key2new = {}
for tid in range(vocab_size):
text = tokenizer.decode([tid], skip_special_tokens=False)
key = token_string_if_undecodable(text) or normalize(text)
if key not in key2new:
key2new[key] = len(key2new)
old2new[tid] = key2new[key]
lookup = np.empty(vocab_size, dtype=np.int64)
for tid in range(vocab_size):
lookup[tid] = old2new[tid]
Where the n-gram hash is called
The demo's n-gram hash routine is named _get_ngram_hashes. It is called by NgramHashMapping.hash, which first compresses the input IDs and then computes separate hash IDs for every configured Engram layer.
def hash(self, input_ids):
input_ids = self.compressed_tokenizer(input_ids)
hash_ids_for_all_layers = {}
for layer_id in self.layer_ids:
hash_ids_for_all_layers[layer_id] = self._get_ngram_hashes(
input_ids,
layer_id=layer_id,
)
return hash_ids_for_all_layers
Inside _get_ngram_hashes, the implementation forms shifted token views so that each position can see its local suffix. For a trigram-capable layer, the arrays are roughly current token, previous token, and token two steps back.
def shift_k(k):
if k == 0:
return x
shifted = np.pad(
x,
((0, 0), (k, 0)),
mode="constant",
constant_values=self.pad_id,
)[:, :T]
return shifted
base_shifts = [shift_k(k) for k in range(self.max_ngram_size)]
The actual indexing function is multiplicative-XOR followed by a per-head modulus. Each layer receives its own random odd multipliers, seeded from the layer ID, so identical n-grams can map differently in different layers.
for n in range(2, self.max_ngram_size + 1):
n_gram_index = n - 2
tokens = base_shifts[:n]
mix = tokens[0] * multipliers[0]
for k in range(1, n):
mix = np.bitwise_xor(mix, tokens[k] * multipliers[k])
for j, mod in enumerate(head_vocab_sizes):
head_hash = mix % int(mod)
all_hashes.append(head_hash.astype(np.int64, copy=False))
return np.stack(all_hashes, axis=2)
The demo chooses distinct prime table sizes for each head. That is a small but important engineering detail: if all heads used the same modulus, collisions would be correlated; different prime moduli reduce repeated collision structure.
Gathering rows
The row IDs returned by hashing have shape [B, T, H], where H = (N - 1)K. MultiHeadEmbedding stores all head tables in one embedding matrix and adds precomputed offsets so every head indexes its own region.
offsets = [0]
for table_size in list_of_N[:-1]:
offsets.append(offsets[-1] + table_size)
shifted_input_ids = input_ids + self.offsets
rows = self.embedding(shifted_input_ids)
Then Engram.forward flattens the per-head vectors into a single memory vector per token:
hash_input_ids = torch.from_numpy(
self.hash_mapping.hash(input_ids)[self.layer_id]
)
embeddings = self.multi_head_embedding(hash_input_ids)
embeddings = embeddings.flatten(start_dim=-2)
Branch-specific gating
The hidden state decides whether the retrieved memory is relevant. For every hyper-connection branch, Engram projects the memory into a key, compares it with the branch hidden state, and uses the score as a scalar gate on the value projection.
gates = []
for hc_idx in range(backbone_config.hc_mult):
key = self.key_projs[hc_idx](embeddings)
normed_key = self.norm1[hc_idx](key)
query = hidden_states[:, :, hc_idx, :]
normed_query = self.norm2[hc_idx](query)
gate = (normed_key * normed_query).sum(dim=-1)
gate = gate / math.sqrt(backbone_config.hidden_size)
gate = gate.abs().clamp_min(1e-6).sqrt() * gate.sign()
gate = gate.sigmoid().unsqueeze(-1)
gates.append(gate)
gates = torch.stack(gates, dim=2)
value = gates * self.value_proj(embeddings).unsqueeze(2)
Short convolution and residual output
After gating, the demo applies grouped depthwise causal convolution over the branch dimension, then returns the memory update. The Transformer block adds that update to the current hidden state.
output = value + self.short_conv(value)
return output
A production implementation still needs distributed sparse table sharding, fused row gather, fused key/value projections, asynchronous host-memory prefetch, cache management, and careful handling of CPU-to-GPU transfer overlap. The demo makes the algorithm readable; it is not meant to be the final serving kernel.
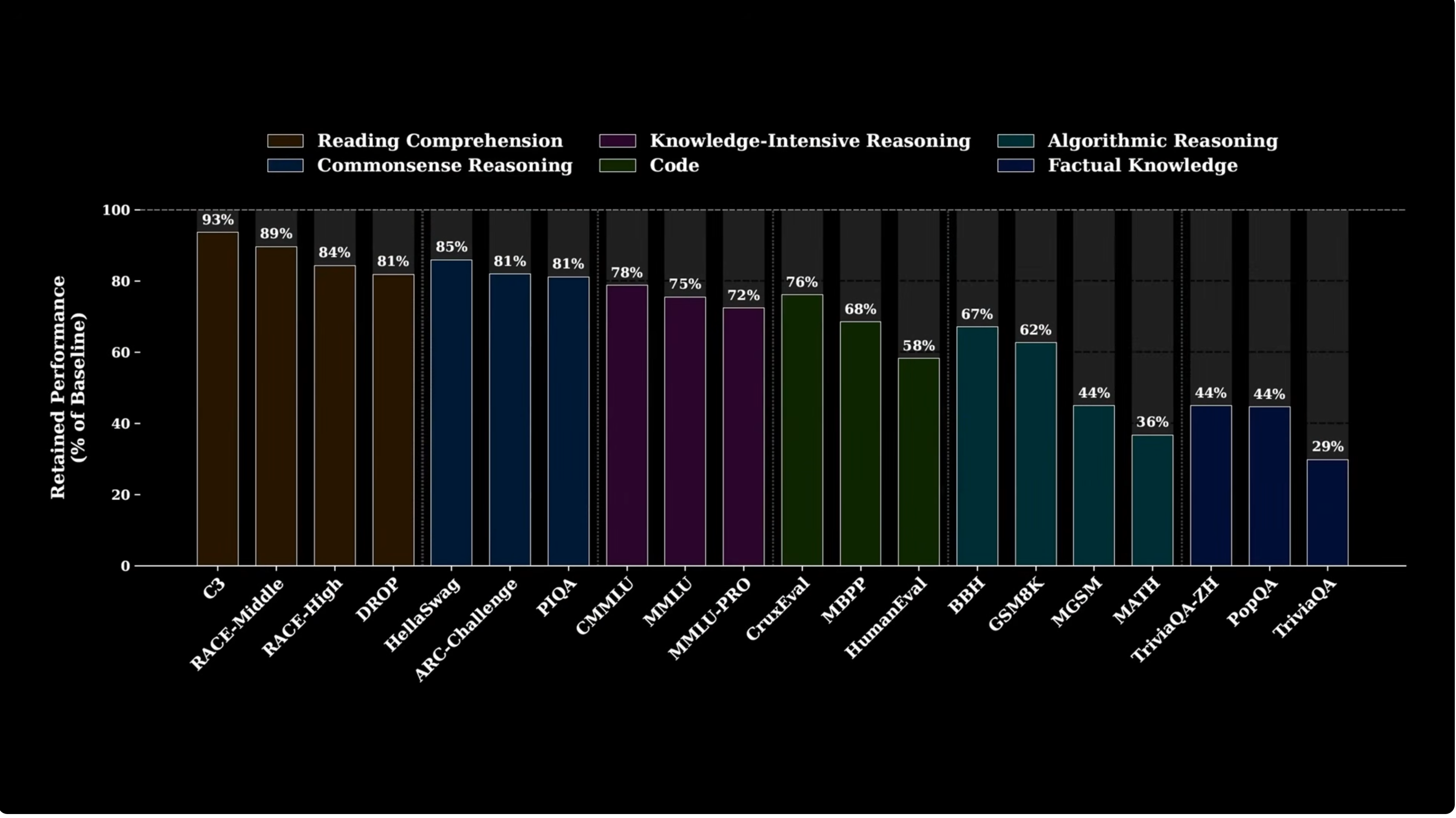
Useful, not magic
Engram is not a replacement for reasoning, external retrieval, or careful training.
- It stores parametric knowledge. Changing facts still needs fine-tuning, table editing, or another update mechanism.
- Hash collisions are reduced by multiple heads, not eliminated.
- The optimal MoE/Engram ratio is empirical and may shift with scale, data, tokenizer, and hardware.
- It is strongest for local stereotyped patterns: names, entities, idioms, common code fragments, and frequent phrase structures.
- Independent replication will matter because the systems benefits depend heavily on implementation quality.
Sources
- Xin Cheng et al. Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models.
- DeepSeek-AI official Engram repository.
- Engram video by Jia-Bin Huang.
- Da Yu et al. Scaling Embedding Layers in Language Models.
- Alisa Liu et al. SuperBPE: Space Travel for Language Models.
- Hongzhi Huang et al. Over-Tokenized Transformer: Vocabulary is Generally Worth Scaling.
- Artidoro Pagnoni et al. Byte Latent Transformer: Patches Scale Better Than Tokens.
- Hong Liu et al. Scaling Embeddings Outperforms Scaling Experts in Language Models.
- Google AI for Developers. Gemma 3n model overview.
- RWKV Wiki. RWKV Architecture History, DeepEmbed section.
- Mor Geva et al. Transformer Feed-Forward Layers Are Key-Value Memories.
- Guillaume Lample et al. Large Memory Layers with Product Keys.