PPML Series #3 - Federated Learning for Mobile Keyboard Prediction
Introduction
Gboard — the Google keyboard, is a virtual keyboard for smartphones with support for more than 900+ language varieties and over 1 billion installs. In addition to decoding noisy signals from input modalities including tap and word-gesture typing, Gboard provides auto-correction, word completion, and next-word prediction features.
Next-word predictions provide a tool for facilitating text entry and is plays an important role in improving user experience. Based on a small amount of user-generated preceding text, language models (LMs) can predict the most probable next word or phrase.
The above figure shows an example: given the text, “I love you”, Gboard predicts the user is likely to type “and”, “too”, or “so much” next. The centre position in the suggestion strip is reserved for the highest-probability candidate, while the second and third most likely candidates occupy the left and right positions, respectively.
Important - The technical details shared in this post are based on the paper which was published by Google in 2019. So, some details may be out-of-date, but the core idea behind the solution should still pretty much be the same. Checkout may annotated version of the paper here.
The primary (static) language model for the English language in Gboard is a Katz smoothed Bayesian interpolated 5-gram LM containing 1.25 million n-grams, including 164,000 unigrams. You can read more about it in this paper. We won;t go into this much as the focus of the post is on the next-word prediction task.
Another important point one should keep in mind is that mobile keyboard models are constrained in multiple ways - the models should be small, the inference time should be low. Users typically expect a visible keyboard response within 20 milliseconds of an input event. And, given the frequency with which mobile keyboard apps are used, client device batteries could be quickly depleted if CPU consumption were not constrained. As a result, language models are usually limited to tens of megabytes in size with vocabularies of hundreds of thousands of words.
In the paper, the authors also discussed about how RNNs and more specifically LSTMs can be used for language modeling since they can utilize an arbitrary and dynamically-sized context window.
Where does Federated Learning come in?
For the task of next-word prediction, publicly available datasets could have been used. However, the training distribution of those datasets does not match the population distribution. Using sample user-generated text will require efforts such as logging, infrastructure, dedicated storage and security. And even still, some users might not be comfortable with the collection and remote storage of their personal data.
For these reasons, the authors use federated learning. The federated learning environment gives users greater control over the use of their data and simplifies the task of incorporating privacy by default with distributed training and aggregation across a population of client devices. An RNN model is trained from scratch in the server and federated environments and achieves recall improvements with respect to the baseline, which is a n-gram finite state transducer (FST).
Model Architecture and Training
A variant of LSTM called Coupled Input and Forget Gate (CIFG) is used. The coupled input and forget gate variant uses only one gate for modulating the input and the cell recurrent self-connections, i.e., f = 1 - i. Read more about CIFG in this paper. Since CIFG uses a single gate to control both the input and recurrent cell self-connections, the number of parameters per cell is reduced by 25%. For time step t, input gate it and forget gate ft have the relation
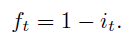
The CIFG architecture is advantageous for the mobile device environment because the number of computations and the parameter set size are reduced with no impact on model performance. The model is trained using Tensorflow and on-device inference is supported by Tensorflow Lite. Client device requirements limit the dictionary size to 10,000 words. CIFG’s input and output embedding size is 96. A single layer of CIFG with 670 units is used. Overall, 1.4 million parameters comprise the network. After weight quantization, the model shipped to Gboard devices is 1.4 megabytes in size.
The training of the model was done using the FederatedAveraging (FedAvg) algorithm, which I wrote about in my previous blog post.
Experiments
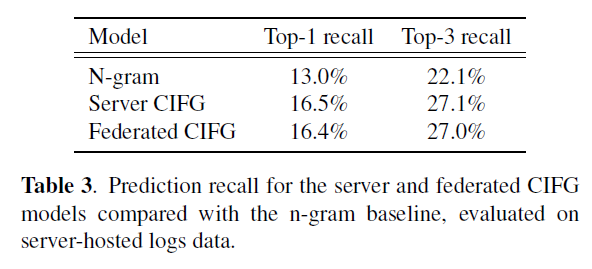
The paper shows the performance of the CIFG and the FST model on three datasets - server-hosted logs data, client-held data and in live production experiments.
Server-based logs
Server-based training of the CIFG next-word prediction model relies on data logged from Gboard users who have opted to share snippets of text while typing in Google apps. The text is truncated to contain short phrases of a few words, and snippets are only sporadically logged from individual users. Prior to training, logs are anonymized and stripped of personally identifiable information. Additionally, snippets are only used for training if they begin with a start of sentence token.
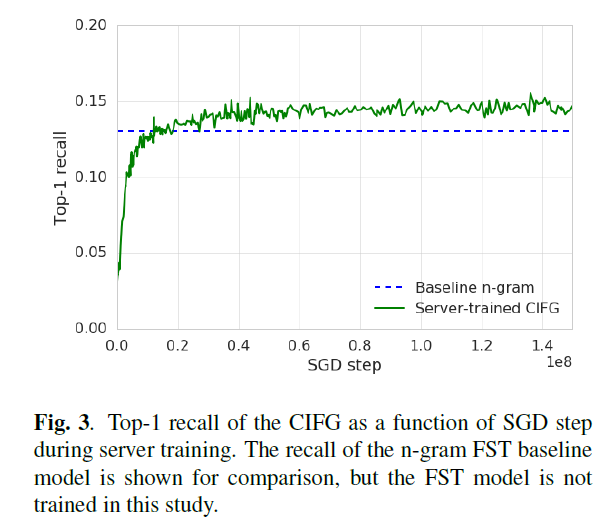
Asynchronous stochastic gradient descent with a learning rate equal to 10-3 and no weight decay or momentum is used to train the server CIFG. Adaptive gradient methods like Adam and AdaGrad do not improve convergence. The network converges after 150 million steps of SGD.
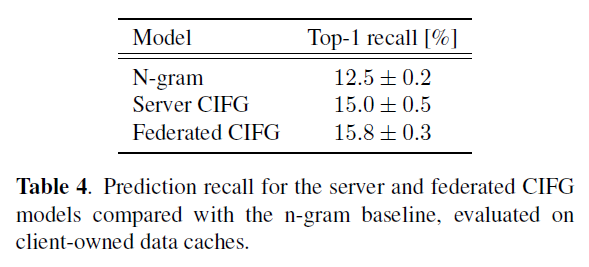
Federated training with client caches
As with the logs data, each client cache stores text belonging to the device owner, as well as prediction candidates generated by the decoder. Devices must have at least 2 gigabytes of memory available. Additionally, the clients are only allowed to participate if they are charging, connected to an un-metered network, and idle.
The FedAvg algorithm is used here. Between 100 and 500 client updates are required to close each round of federated training in Gboard. The server update is achieved via the Momentum optimizer, using Nesterov accelerated gradient, a momentum hyperparameter of 0.9, and a server learning rate of 1.0 .
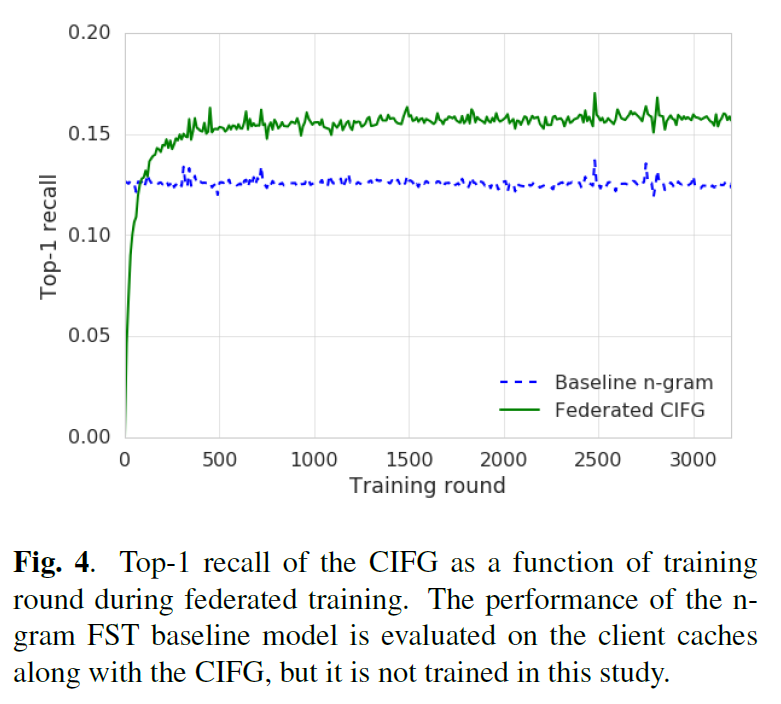
On average, each client processes approximately 400 example sentences during a single training epoch. The federated CIFG converges after 3000 training rounds, over the course of which 600 million sentences are processed by 1.5 million clients.
N-gram model recall is measured by comparing the decoder candidates stored in the on-device training cache to the actual user-entered text.
Results
Recall (metric) for the highest likelihood candidate is important for Gboard because users are more prone to read and utilize predictions in the centre suggestion spot. Both top-1 and top-3 recall are of interest here.
Server-hosted logs data and client device-owned caches are used to measure prediction recall. Although each contain snippets of data from actual users, the client caches are believed to more accurately represent the true typing data distribution. Cache data, unlike logs, are not truncated in length and are not restricted to keyboard usage in Google-owned apps.
Prediction impression recall is measured by dividing the number of predictions that match the user-entered text by the number of times users are shown prediction candidates. The prediction impression recall metric is typically lower than the standard recall metric. Zero-state prediction events (in which users open the Gboard app but do not commit any text) increase the number of impressions but not matches.
The prediction click-through rate (CTR), defined as the ratio of the number of clicks on prediction candidates to the number of proposed prediction candidates.
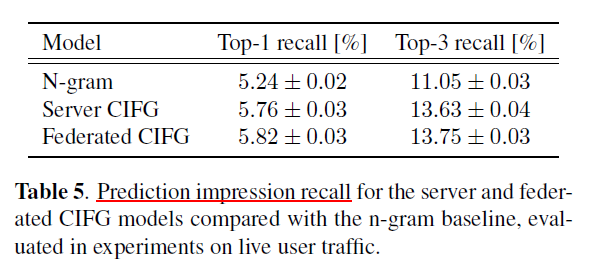

For both the server training and the federated training, the CIFG model improves the top-1 and top-3 recall with respect to the baseline n-gram FST model.
These gains are impressive given that the n-gram model uses an order of magnitude larger vocabulary and includes personalized components such as user history and contacts language models.
The results also demonstrate that the federated CIFG performs better on recall metrics than the server-trained CIFG. Comparisons on server-hosted logs data show the recall of the two models is comparable, though the logs are not as representative of the true typing distribution.
Different flavors of SGD are used in each training context—the results show that federated learning provides a preferable alternative to server-based training of neural language models.
Conclusion
CIFG language model trained from scratch using federated learning can outperform an identical server trained CIFG model and baseline n-gram model on the keyboard next-word prediction task.
I have also released an annotated version of the paper. If you are interested, you can find it here.
That’s all for now!