Flash Attention in Pytorch
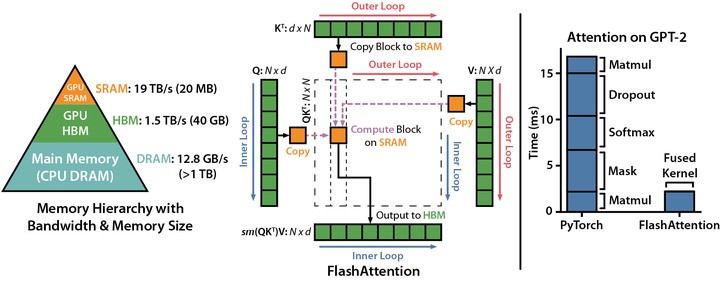
A simplified implementation of FlashAttention in PyTorch. I have implemented the forward pass and backward pass algorithms from the paper, and also shown that it is equivalent to the normal attention formulation in Transformers. I also include some code for benchmarking.
Note that this is for educational purposes only as I haven’t implemented any of the CUDA and SRAM memory tricks as described in the paper.