- mlsys
- transformer
- paper-summaries
- MLSys
- LLMs
- PPML
•
•
•
•
•
-
Paper Summary #11 - Sora
OpenAI announced a ground-breaking text-to-video diffusion model capable of generating high-definition videos up to 60 seconds long.

-
Paper Summary #10 - Gemini 1.5 Pro
Google DeepMind announced a multimodal LLM with support of up to 10M context length.

-
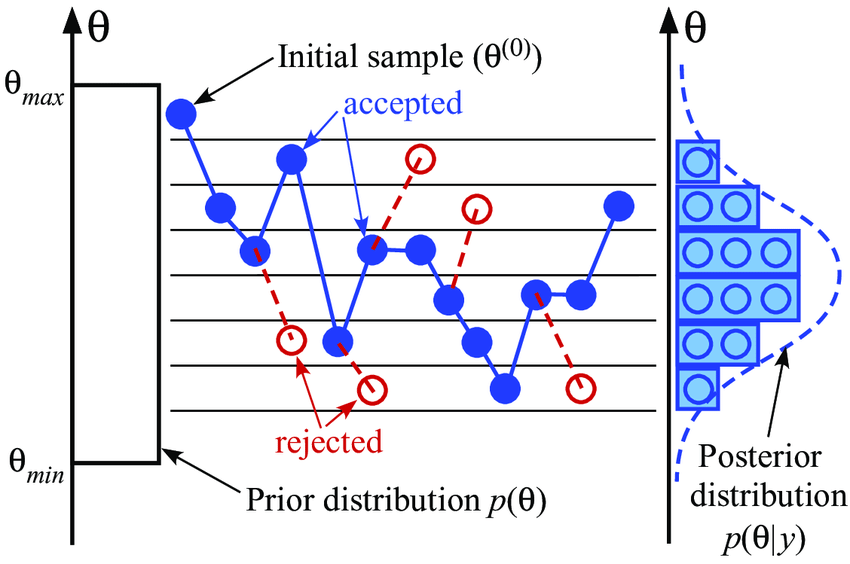
Solving Substitution Ciphers using Markov Chain Monte Carlo (MCMC)
Deciphering substitution ciphers can be framed as a Markov chain problem and a simple Monte Carlo sampling approach can help solve them very efficiently
-
Paper Summary #9 - Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training
Understanding Sophia - A new fast, scalable second-order optimizer which beats Adam on LLM pretraining.

-
Paper Summary #8 - FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Understanding FlashAttention which is the most efficient exact attention implementation out there, which optimizes for both memory requirements and wall-clock time.

-
Paper Summary #7 - Efficient Transformers: A Survey
A survey paper of improvements over the original Transformer architecture in terms of memory-efficiency.

-
Deploying Machine Learning models using GCP's Google AI Platform - A Detailed Tutorial
A step-wise tutorial to demonstrate the steps required to deploy a ML model using GCP, specifically the Google AI Platform and use Streamlit to access the model through a UI.
-
Deploying Machine Learning models using AWS Lambda and Github Actions - A Detailed Tutorial
A step-wise tutorial to demonstrate the steps required to deploy a ML model using AWS Lambda, Github Actions, API Gateway and use Streamlit to access the model API through a UI.

-
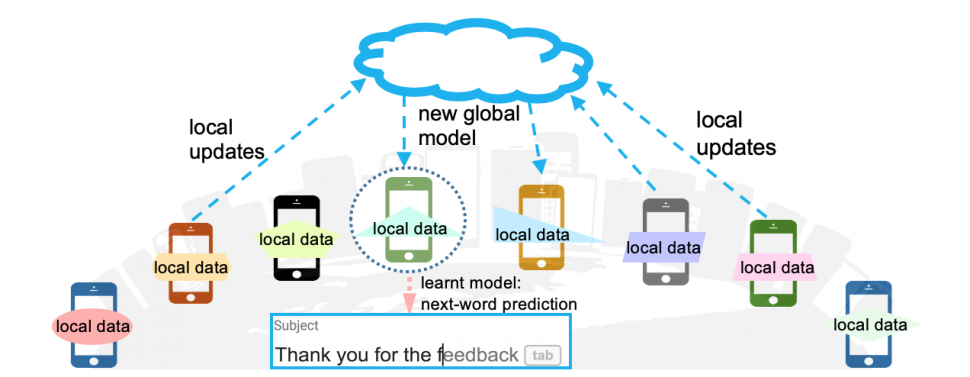
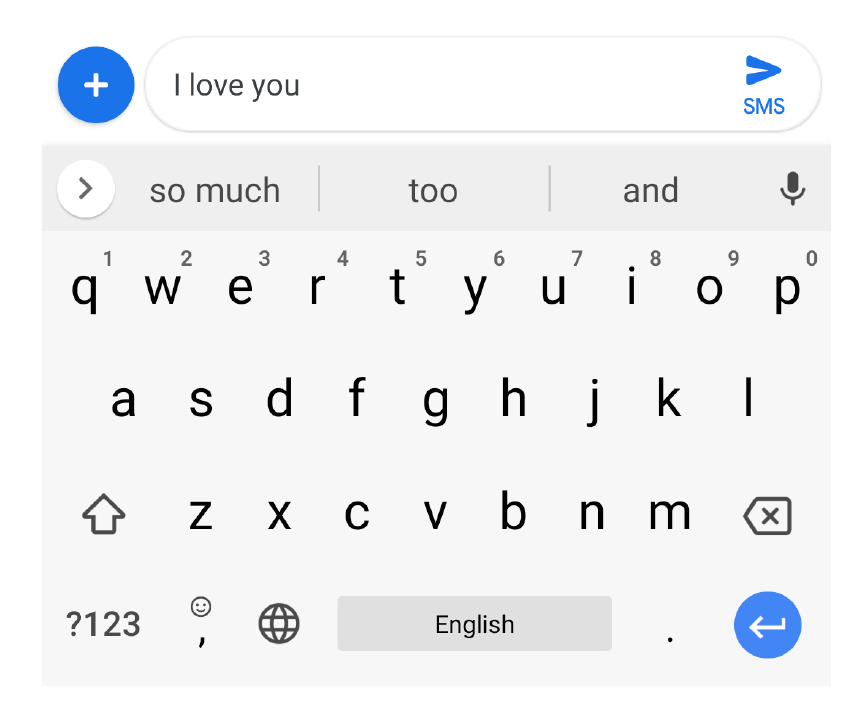
PPML Series #3 - Federated Learning for Mobile Keyboard Prediction
Understanding how your mobile keyboard (Gboard, specifically) performs the next word prediction task and performs model training and updates
-
PPML Series #2 - Federated Optimization Algorithms - FedSGD and FedAvg
A mathematical deep dive on a Federated Optimization algorithm - FedAvg and comparing it with a standard approach - FedSGD.